 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDAC: Efficient Coreset Selection for Continual Learning via Probability Density Awareness
Nov 12, 2025Rehearsal-based Continual Learning (CL) maintains a limited memory buffer to store replay samples for knowledge retention, making these approaches heavily reliant on the quality of the stored samples. Current Rehearsal-based CL methods typically construct the memory buffer by selecting a representative subset (referred to as coresets), aiming to approximate the training efficacy of the full dataset with minimal storage overhead. However, mainstream Coreset Selection (CS) methods generally formulate the CS problem as a bi-level optimization problem that relies on numerous inner and outer iterations to solve, leading to substantial computational cost thus limiting their practical efficiency. In this paper, we aim to provide a more efficient selection logic and scheme for coreset construction. To this end, we first analyze the Mean Squared Error (MSE) between the buffer-trained model and the Bayes-optimal model through the perspective of localized error decomposition to investigate the contribution of samples from different regions to MSE suppression. Further theoretical and experimental analyses demonstrate that samples with high probability density play a dominant role in error suppression. Inspired by this, we propose the Probability Density-Aware Coreset (PDAC) method. PDAC leverages the Projected Gaussian Mixture (PGM) model to estimate each sample's joint density, enabling efficient density-prioritized buffer selection. Finally, we introduce the streaming Expectation Maximization (EM) algorithm to enhance the adaptability of PGM parameters to streaming data, yielding Streaming PDAC (SPDAC) for streaming scenarios. Extensive comparative experiments show that our methods outperforms other baselines across various CL settings while ensuring favorable efficiency.
An ICTM-RMSAV Framework for Bias-Field Aware Image Segmentation under Poisson and Multiplicative Noise
Nov 12, 2025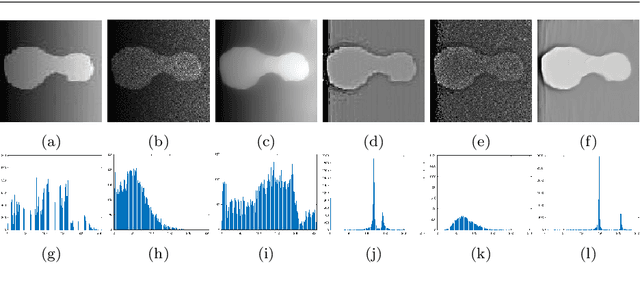
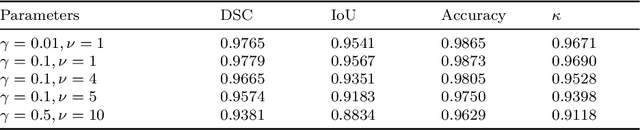

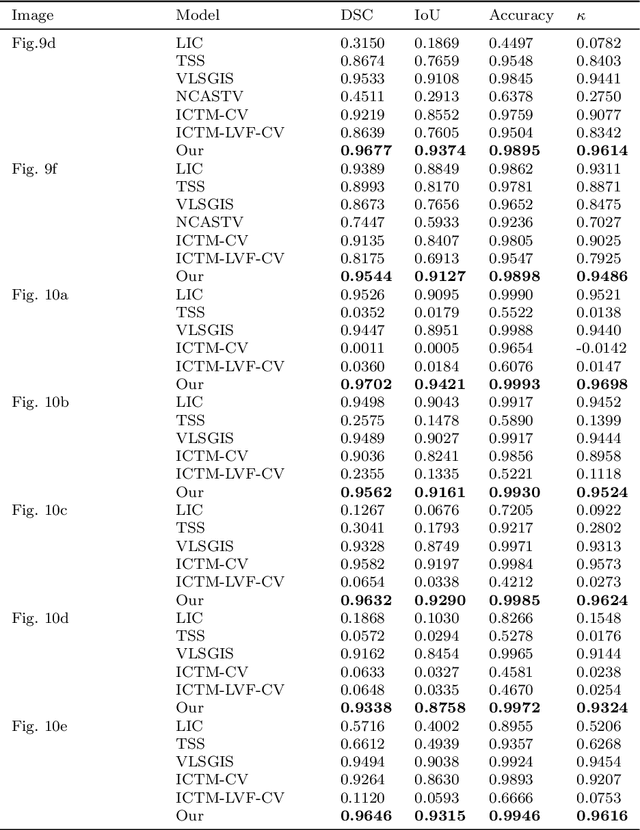
Image segmentation is a core task in image processing, yet many methods degrade when images are heavily corrupted by noise and exhibit intensity inhomogeneity. Within the iterative-convolution thresholding method (ICTM) framework, we propose a variational segmentation model that integrates denoising terms. Specifically, the denoising component consists of an I-divergence term and an adaptive total-variation (TV) regularizer, making the model well suited to images contaminated by Gamma--distributed multiplicative noise and Poisson noise. A spatially adaptive weight derived from a gray-level indicator guides diffusion differently across regions of varying intensity. To further address intensity inhomogeneity, we estimate a smoothly varying bias field, which improves segmentation accuracy. Regions are represented by characteristic functions, with contour length encoded accordingly. For efficient optimization, we couple ICTM with a relaxed modified scalar auxiliary variable (RMSAV) scheme. Extensive experiments on synthetic and real-world images with intensity inhomogeneity and diverse noise types show that the proposed model achieves superior accuracy and robustness compared with competing approaches.
Towards Frequency-Adaptive Learning for SAR Despeckling
Nov 08, 2025Synthetic Aperture Radar (SAR) images are inherently corrupted by speckle noise, limiting their utility in high-precision applications. While deep learning methods have shown promise in SAR despeckling, most methods employ a single unified network to process the entire image, failing to account for the distinct speckle statistics associated with different spatial physical characteristics. It often leads to artifacts, blurred edges, and texture distortion. To address these issues, we propose SAR-FAH, a frequency-adaptive heterogeneous despeckling model based on a divide-and-conquer architecture. First, wavelet decomposition is used to separate the image into frequency sub-bands carrying different intrinsic characteristics. Inspired by their differing noise characteristics, we design specialized sub-networks for different frequency components. The tailored approach leverages statistical variations across frequencies, improving edge and texture preservation while suppressing noise. Specifically, for the low-frequency part, denoising is formulated as a continuous dynamic system via neural ordinary differential equations, ensuring structural fidelity and sufficient smoothness that prevents artifacts. For high-frequency sub-bands rich in edges and textures, we introduce an enhanced U-Net with deformable convolutions for noise suppression and enhanced features. Extensive experiments on synthetic and real SAR images validate the superior performance of the proposed model in noise removal and structural preservation.
Mixed geometry information regularization for image multiplicative denoising
Dec 21, 2024This paper focuses on solving the multiplicative gamma denoising problem via a variation model. Variation-based regularization models have been extensively employed in a variety of inverse problem tasks in image processing. However, sufficient geometric priors and efficient algorithms are still very difficult problems in the model design process. To overcome these issues, in this paper we propose a mixed geometry information model, incorporating area term and curvature term as prior knowledge. In addition to its ability to effectively remove multiplicative noise, our model is able to preserve edges and prevent staircasing effects. Meanwhile, to address the challenges stemming from the nonlinearity and non-convexity inherent in higher-order regularization, we propose the efficient additive operator splitting algorithm (AOS) and scalar auxiliary variable algorithm (SAV). The unconditional stability possessed by these algorithms enables us to use large time step. And the SAV method shows higher computational accuracy in our model. We employ the second order SAV algorithm to further speed up the calculation while maintaining accuracy. We demonstrate the effectiveness and efficiency of the model and algorithms by a lot of numerical experiments, where the model we proposed has better features texturepreserving properties without generating any false information.
Adversarial Transferability in Deep Denoising Models: Theoretical Insights and Robustness Enhancement via Out-of-Distribution Typical Set Sampling
Dec 08, 2024Deep learning-based image denoising models demonstrate remarkable performance, but their lack of robustness analysis remains a significant concern. A major issue is that these models are susceptible to adversarial attacks, where small, carefully crafted perturbations to input data can cause them to fail. Surprisingly, perturbations specifically crafted for one model can easily transfer across various models, including CNNs, Transformers, unfolding models, and plug-and-play models, leading to failures in those models as well. Such high adversarial transferability is not observed in classification models. We analyze the possible underlying reasons behind the high adversarial transferability through a series of hypotheses and validation experiments. By characterizing the manifolds of Gaussian noise and adversarial perturbations using the concept of typical set and the asymptotic equipartition property, we prove that adversarial samples deviate slightly from the typical set of the original input distribution, causing the models to fail. Based on these insights, we propose a novel adversarial defense method: the Out-of-Distribution Typical Set Sampling Training strategy (TS). TS not only significantly enhances the model's robustness but also marginally improves denoising performance compared to the original model.
A Tunable Despeckling Neural Network Stabilized via Diffusion Equation
Nov 24, 2024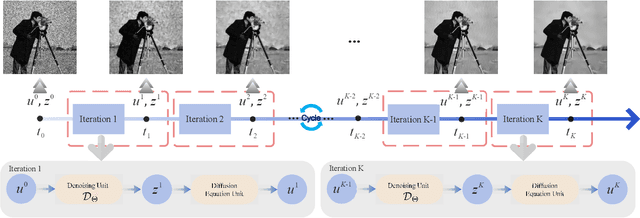
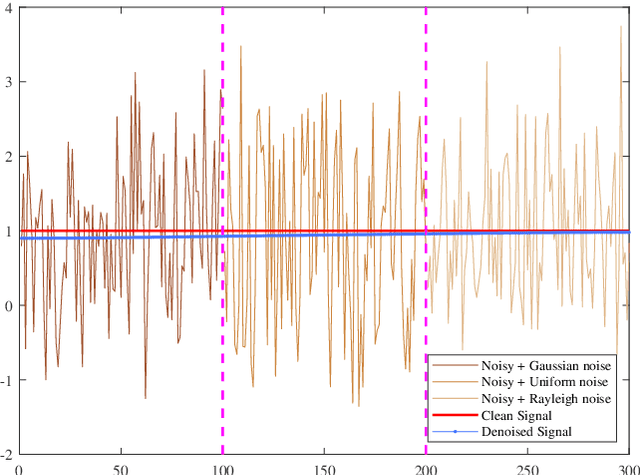
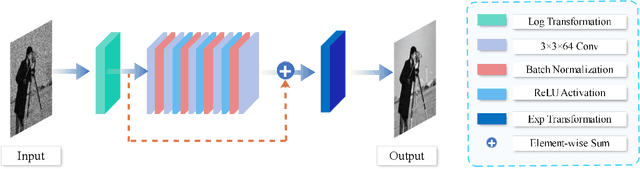

Multiplicative Gamma noise remove is a critical research area in the application of synthetic aperture radar (SAR) imaging, where neural networks serve as a potent tool. However, real-world data often diverges from theoretical models, exhibiting various disturbances, which makes the neural network less effective. Adversarial attacks work by finding perturbations that significantly disrupt functionality of neural networks, as the inherent instability of neural networks makes them highly susceptible. A network designed to withstand such extreme cases can more effectively mitigate general disturbances in real SAR data. In this work, the dissipative nature of diffusion equations is employed to underpin a novel approach for countering adversarial attacks and improve the resistance of real noise disturbance. We propose a tunable, regularized neural network that unrolls a denoising unit and a regularization unit into a single network for end-to-end training. In the network, the denoising unit and the regularization unit are composed of the denoising network and the simplest linear diffusion equation respectively. The regularization unit enhances network stability, allowing post-training time step adjustments to effectively mitigate the adverse impacts of adversarial attacks. The stability and convergence of our model are theoretically proven, and in the experiments, we compare our model with several state-of-the-art denoising methods on simulated images, adversarial samples, and real SAR images, yielding superior results in both quantitative and visual evaluations.
Perturbation Towards Easy Samples Improves Targeted Adversarial Transferability
Jun 08, 2024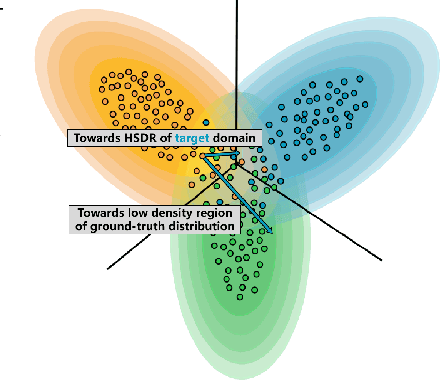

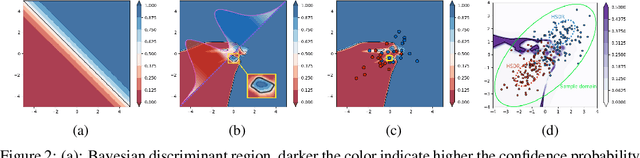

The transferability of adversarial perturbations provides an effective shortcut for black-box attacks. Targeted perturbations have greater practicality but are more difficult to transfer between models. In this paper, we experimentally and theoretically demonstrated that neural networks trained on the same dataset have more consistent performance in High-Sample-Density-Regions (HSDR) of each class instead of low sample density regions. Therefore, in the target setting, adding perturbations towards HSDR of the target class is more effective in improving transferability. However, density estimation is challenging in high-dimensional scenarios. Further theoretical and experimental verification demonstrates that easy samples with low loss are more likely to be located in HSDR. Perturbations towards such easy samples in the target class can avoid density estimation for HSDR location. Based on the above facts, we verified that adding perturbations to easy samples in the target class improves targeted adversarial transferability of existing attack methods. A generative targeted attack strategy named Easy Sample Matching Attack (ESMA) is proposed, which has a higher success rate for targeted attacks and outperforms the SOTA generative method. Moreover, ESMA requires only 5% of the storage space and much less computation time comparing to the current SOTA, as ESMA attacks all classes with only one model instead of seperate models for each class. Our code is available at https://github.com/gjq100/ESMA.
Diffusion Probabilistic Multi-cue Level Set for Reducing Edge Uncertainty in Pancreas Segmentation
Apr 11, 2024



Accurately segmenting the pancreas remains a huge challenge. Traditional methods encounter difficulties in semantic localization due to the small volume and distorted structure of the pancreas, while deep learning methods encounter challenges in obtaining accurate edges because of low contrast and organ overlapping. To overcome these issues, we propose a multi-cue level set method based on the diffusion probabilistic model, namely Diff-mcs. Our method adopts a coarse-to-fine segmentation strategy. We use the diffusion probabilistic model in the coarse segmentation stage, with the obtained probability distribution serving as both the initial localization and prior cues for the level set method. In the fine segmentation stage, we combine the prior cues with grayscale cues and texture cues to refine the edge by maximizing the difference between probability distributions of the cues inside and outside the level set curve. The method is validated on three public datasets and achieves state-of-the-art performance, which can obtain more accurate segmentation results with lower uncertainty segmentation edges. In addition, we conduct ablation studies and uncertainty analysis to verify that the diffusion probability model provides a more appropriate initialization for the level set method. Furthermore, when combined with multiple cues, the level set method can better obtain edges and improve the overall accuracy. Our code is available at https://github.com/GOUYUEE/Diff-mcs.
Adversarial Training for Physics-Informed Neural Networks
Oct 18, 2023
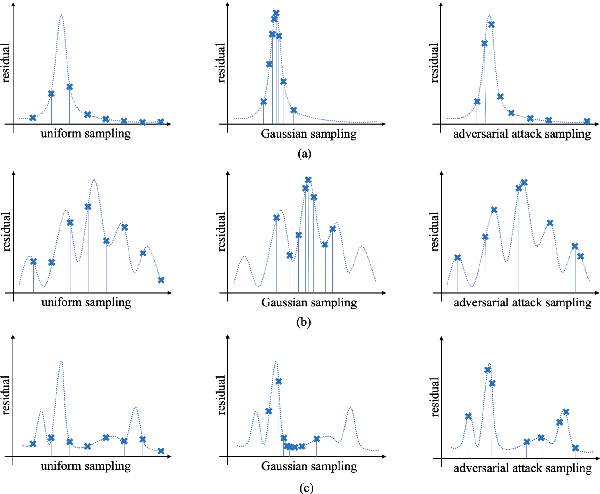


Physics-informed neural networks have shown great promise in solving partial differential equations. However, due to insufficient robustness, vanilla PINNs often face challenges when solving complex PDEs, especially those involving multi-scale behaviors or solutions with sharp or oscillatory characteristics. To address these issues, based on the projected gradient descent adversarial attack, we proposed an adversarial training strategy for PINNs termed by AT-PINNs. AT-PINNs enhance the robustness of PINNs by fine-tuning the model with adversarial samples, which can accurately identify model failure locations and drive the model to focus on those regions during training. AT-PINNs can also perform inference with temporal causality by selecting the initial collocation points around temporal initial values. We implement AT-PINNs to the elliptic equation with multi-scale coefficients, Poisson equation with multi-peak solutions, Burgers equation with sharp solutions and the Allen-Cahn equation. The results demonstrate that AT-PINNs can effectively locate and reduce failure regions. Moreover, AT-PINNs are suitable for solving complex PDEs, since locating failure regions through adversarial attacks is independent of the size of failure regions or the complexity of the distribution.
Re-initialization-free Level Set Method via Molecular Beam Epitaxy Equation Regularization for Image Segmentation
Oct 13, 2023



Variational level set method has become a powerful tool in image segmentation due to its ability to handle complex topological changes and maintain continuity and smoothness in the process of evolution. However its evolution process can be unstable, which results in over flatted or over sharpened contours and segmentation failure. To improve the accuracy and stability of evolution, we propose a high-order level set variational segmentation method integrated with molecular beam epitaxy (MBE) equation regularization. This method uses the crystal growth in the MBE process to limit the evolution of the level set function, and thus can avoid the re-initialization in the evolution process and regulate the smoothness of the segmented curve. It also works for noisy images with intensity inhomogeneity, which is a challenge in image segmentation. To solve the variational model, we derive the gradient flow and design scalar auxiliary variable (SAV) scheme coupled with fast Fourier transform (FFT), which can significantly improve the computational efficiency compared with the traditional semi-implicit and semi-explicit scheme. Numerical experiments show that the proposed method can generate smooth segmentation curves, retain fine segmentation targets and obtain robust segmentation results of small objects. Compared to existing level set methods, this model is state-of-the-art in both accuracy and efficiency.