 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Transferability in Deep Denoising Models: Theoretical Insights and Robustness Enhancement via Out-of-Distribution Typical Set Sampling
Dec 08, 2024Deep learning-based image denoising models demonstrate remarkable performance, but their lack of robustness analysis remains a significant concern. A major issue is that these models are susceptible to adversarial attacks, where small, carefully crafted perturbations to input data can cause them to fail. Surprisingly, perturbations specifically crafted for one model can easily transfer across various models, including CNNs, Transformers, unfolding models, and plug-and-play models, leading to failures in those models as well. Such high adversarial transferability is not observed in classification models. We analyze the possible underlying reasons behind the high adversarial transferability through a series of hypotheses and validation experiments. By characterizing the manifolds of Gaussian noise and adversarial perturbations using the concept of typical set and the asymptotic equipartition property, we prove that adversarial samples deviate slightly from the typical set of the original input distribution, causing the models to fail. Based on these insights, we propose a novel adversarial defense method: the Out-of-Distribution Typical Set Sampling Training strategy (TS). TS not only significantly enhances the model's robustness but also marginally improves denoising performance compared to the original model.
Large Language Models for Multimodal Deformable Image Registration
Aug 20, 2024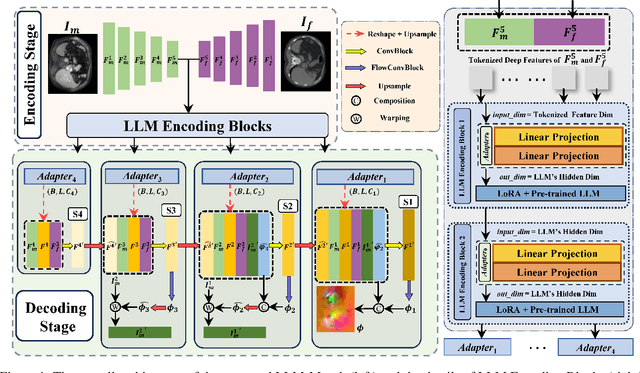
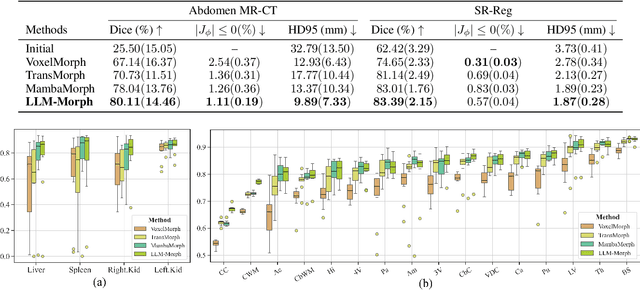
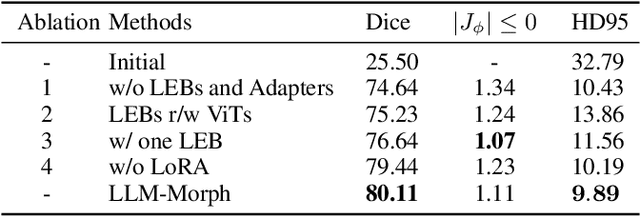
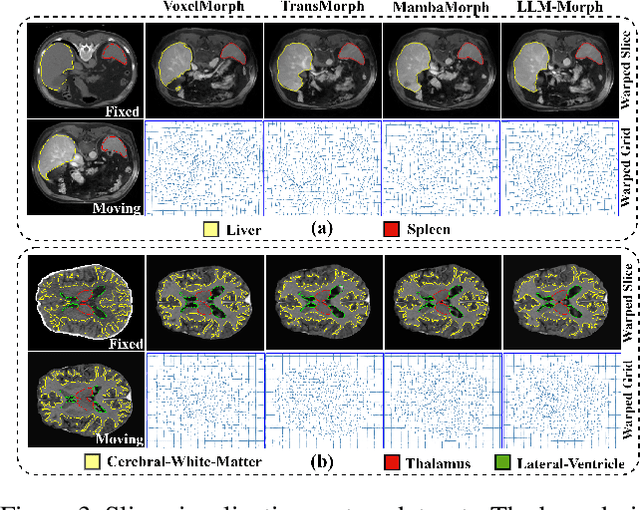
The challenge of Multimodal Deformable Image Registration (MDIR) lies in the conversion and alignment of features between images of different modalities. Generative models (GMs) cannot retain the necessary information enough from the source modality to the target one, while non-GMs struggle to align features across these two modalities. In this paper, we propose a novel coarse-to-fine MDIR framework,LLM-Morph, which is applicable to various pre-trained Large Language Models (LLMs) to solve these concerns by aligning the deep features from different modal medical images. Specifically, we first utilize a CNN encoder to extract deep visual features from cross-modal image pairs, then we use the first adapter to adjust these tokens, and use LoRA in pre-trained LLMs to fine-tune their weights, both aimed at eliminating the domain gap between the pre-trained LLMs and the MDIR task. Third, for the alignment of tokens, we utilize other four adapters to transform the LLM-encoded tokens into multi-scale visual features, generating multi-scale deformation fields and facilitating the coarse-to-fine MDIR task. Extensive experiments in MR-CT Abdomen and SR-Reg Brain datasets demonstrate the effectiveness of our framework and the potential of pre-trained LLMs for MDIR task. Our code is availabel at: https://github.com/ninjannn/LLM-Morph.
Evaluating Similitude and Robustness of Deep Image Denoising Models via Adversarial Attack
Jul 07, 2023



Deep neural networks (DNNs) have shown superior performance comparing to traditional image denoising algorithms. However, DNNs are inevitably vulnerable while facing adversarial attacks. In this paper, we propose an adversarial attack method named denoising-PGD which can successfully attack all the current deep denoising models while keep the noise distribution almost unchanged. We surprisingly find that the current mainstream non-blind denoising models (DnCNN, FFDNet, ECNDNet, BRDNet), blind denoising models (DnCNN-B, Noise2Noise, RDDCNN-B, FAN), plug-and-play (DPIR, CurvPnP) and unfolding denoising models (DeamNet) almost share the same adversarial sample set on both grayscale and color images, respectively. Shared adversarial sample set indicates that all these models are similar in term of local behaviors at the neighborhood of all the test samples. Thus, we further propose an indicator to measure the local similarity of models, called robustness similitude. Non-blind denoising models are found to have high robustness similitude across each other, while hybrid-driven models are also found to have high robustness similitude with pure data-driven non-blind denoising models. According to our robustness assessment, data-driven non-blind denoising models are the most robust. We use adversarial training to complement the vulnerability to adversarial attacks. Moreover, the model-driven image denoising BM3D shows resistance on adversarial attacks.