 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Multimodal Deformable Image Registration
Paper and Code
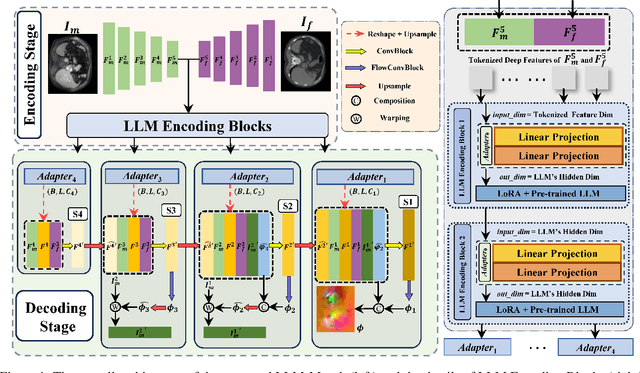
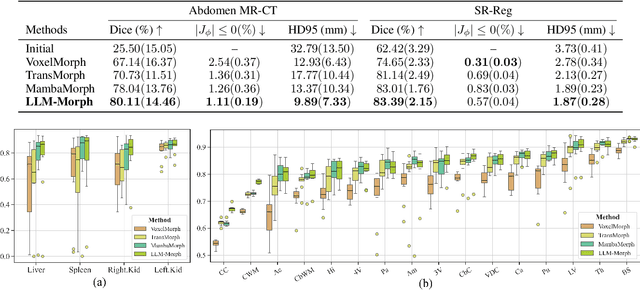
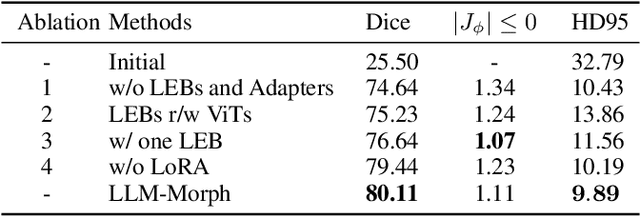
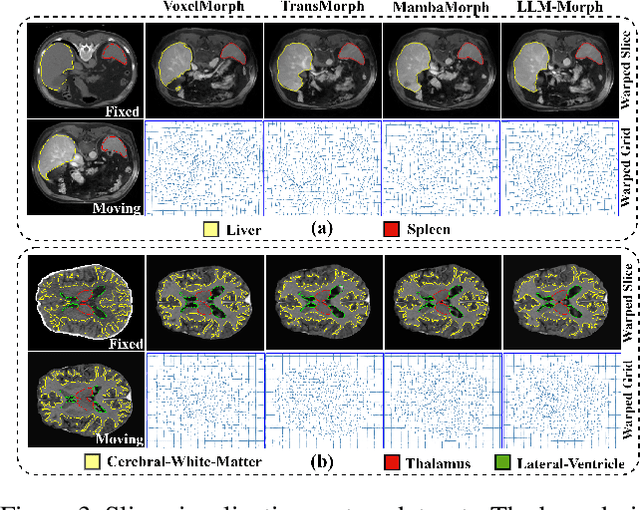
The challenge of Multimodal Deformable Image Registration (MDIR) lies in the conversion and alignment of features between images of different modalities. Generative models (GMs) cannot retain the necessary information enough from the source modality to the target one, while non-GMs struggle to align features across these two modalities. In this paper, we propose a novel coarse-to-fine MDIR framework,LLM-Morph, which is applicable to various pre-trained Large Language Models (LLMs) to solve these concerns by aligning the deep features from different modal medical images. Specifically, we first utilize a CNN encoder to extract deep visual features from cross-modal image pairs, then we use the first adapter to adjust these tokens, and use LoRA in pre-trained LLMs to fine-tune their weights, both aimed at eliminating the domain gap between the pre-trained LLMs and the MDIR task. Third, for the alignment of tokens, we utilize other four adapters to transform the LLM-encoded tokens into multi-scale visual features, generating multi-scale deformation fields and facilitating the coarse-to-fine MDIR task. Extensive experiments in MR-CT Abdomen and SR-Reg Brain datasets demonstrate the effectiveness of our framework and the potential of pre-trained LLMs for MDIR task. Our code is availabel at: https://github.com/ninjannn/LLM-Morph.