 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacNet: An End-to-End Manifold-Constrained Adaptive Clustering Network for Interpretable Whole Slide Image Classification
Feb 16, 2026Whole slide images (WSIs) are the gold standard for pathological diagnosis and sub-typing. Current main-stream two-step frameworks employ offline feature encoders trained without domain-specific knowledge. Among them, attention-based multiple instance learning (MIL) methods are outcome-oriented and offer limited interpretability. Clustering-based approaches can provide explainable decision-making process but suffer from high dimension features and semantically ambiguous centroids. To this end, we propose an end-to-end MIL framework that integrates Grassmann re-embedding and manifold adaptive clustering, where the manifold geometric structure facilitates robust clustering results. Furthermore, we design a prior knowledge guiding proxy instance labeling and aggregation strategy to approximate patch labels and focus on pathologically relevant tumor regions. Experiments on multicentre WSI datasets demonstrate that: 1) our cluster-incorporated model achieves superior performance in both grading accuracy and interpretability; 2) end-to-end learning refines better feature representations and it requires acceptable computation resources.
Large Language Models for Multimodal Deformable Image Registration
Aug 20, 2024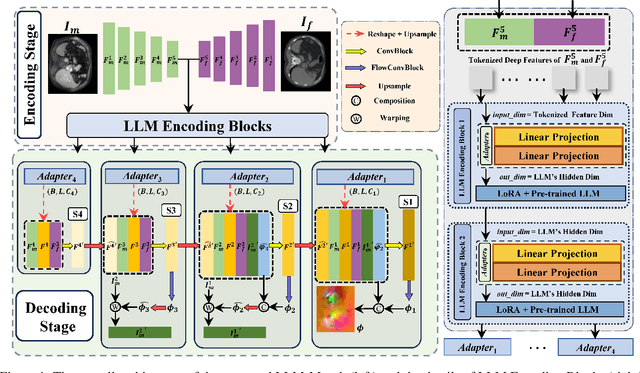
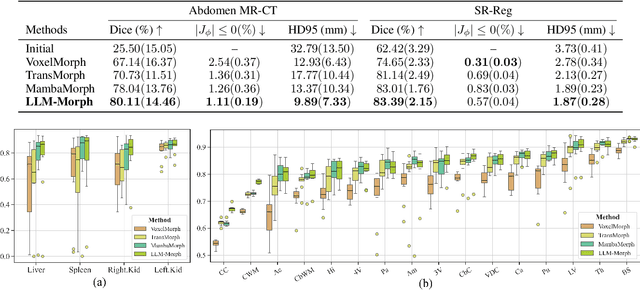
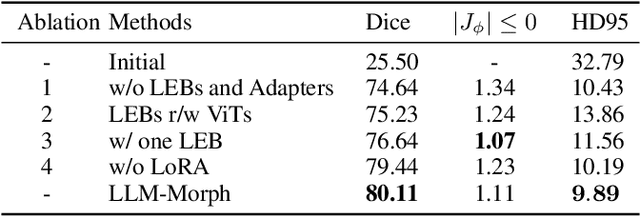
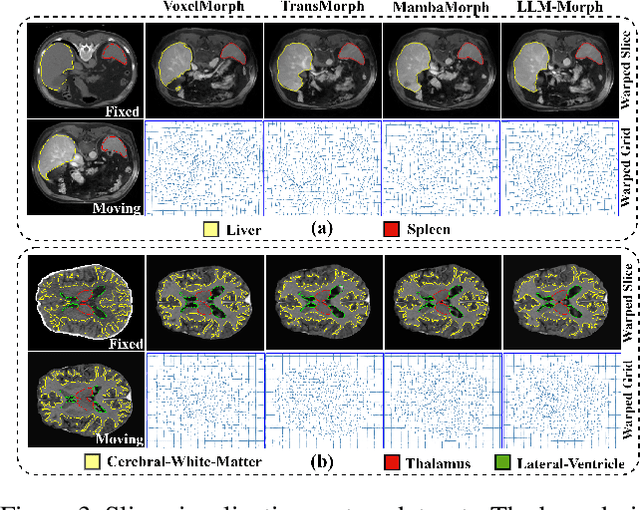
The challenge of Multimodal Deformable Image Registration (MDIR) lies in the conversion and alignment of features between images of different modalities. Generative models (GMs) cannot retain the necessary information enough from the source modality to the target one, while non-GMs struggle to align features across these two modalities. In this paper, we propose a novel coarse-to-fine MDIR framework,LLM-Morph, which is applicable to various pre-trained Large Language Models (LLMs) to solve these concerns by aligning the deep features from different modal medical images. Specifically, we first utilize a CNN encoder to extract deep visual features from cross-modal image pairs, then we use the first adapter to adjust these tokens, and use LoRA in pre-trained LLMs to fine-tune their weights, both aimed at eliminating the domain gap between the pre-trained LLMs and the MDIR task. Third, for the alignment of tokens, we utilize other four adapters to transform the LLM-encoded tokens into multi-scale visual features, generating multi-scale deformation fields and facilitating the coarse-to-fine MDIR task. Extensive experiments in MR-CT Abdomen and SR-Reg Brain datasets demonstrate the effectiveness of our framework and the potential of pre-trained LLMs for MDIR task. Our code is availabel at: https://github.com/ninjannn/LLM-Morph.
LLaMA-Reg: Using LLaMA 2 for Unsupervised Medical Image Registration
May 29, 2024



Medical image registration is an essential topic in medical image analysis. In this paper, we propose a method for medical image registration using a pretrained large language model. We find that using the pretrained large language model to encode deep features of the medical images in the registration model can effectively improve image registration accuracy, indicating the great potential of the large language model in medical image registration tasks. We use dual encoders to perform deep feature extraction on image pairs and then input the features into the pretrained large language model. To adapt the large language model to our registration task, the weights of the large language model are frozen in the registration model, and an adapter is utilized to fine-tune the large language model, which aims at (a) mapping the visual tokens to the language space before the large language model computing, (b) project the modeled language tokens output from the large language model to the visual space. Our method combines output features from the fine-tuned large language model with the features output from each encoder layer to gradually generate the deformation fields required for registration in the decoder. To demonstrate the effectiveness of the large prediction model in registration tasks, we conducted experiments on knee and brain MRI and achieved state-of-the-art results.
Research and application of artificial intelligence based webshell detection model: A literature review
Apr 28, 2024Webshell, as the "culprit" behind numerous network attacks, is one of the research hotspots in the field of cybersecurity. However, the complexity, stealthiness, and confusing nature of webshells pose significant challenges to the corresponding detection schemes. With the rise of Artificial Intelligence (AI) technology, researchers have started to apply different intelligent algorithms and neural network architectures to the task of webshell detection. However, the related research still lacks a systematic and standardized methodological process, which is confusing and redundant. Therefore, following the development timeline, we carefully summarize the progress of relevant research in this field, dividing it into three stages: Start Stage, Initial Development Stage, and In-depth Development Stage. We further elaborate on the main characteristics and core algorithms of each stage. In addition, we analyze the pain points and challenges that still exist in this field and predict the future development trend of this field from our point of view. To the best of our knowledge, this is the first review that details the research related to AI-based webshell detection. It is also hoped that this paper can provide detailed technical information for more researchers interested in AI-based webshell detection tasks.
Research and application of Transformer based anomaly detection model: A literature review
Feb 14, 2024Transformer, as one of the most advanced neural network models in Natural Language Processing (NLP), exhibits diverse applications in the field of anomaly detection. To inspire research on Transformer-based anomaly detection, this review offers a fresh perspective on the concept of anomaly detection. We explore the current challenges of anomaly detection and provide detailed insights into the operating principles of Transformer and its variants in anomaly detection tasks. Additionally, we delineate various application scenarios for Transformer-based anomaly detection models and discuss the datasets and evaluation metrics employed. Furthermore, this review highlights the key challenges in Transformer-based anomaly detection research and conducts a comprehensive analysis of future research trends in this domain. The review includes an extensive compilation of over 100 core references related to Transformer-based anomaly detection. To the best of our knowledge, this is the first comprehensive review that focuses on the research related to Transformer in the context of anomaly detection. We hope that this paper can provide detailed technical information to researchers interested in Transformer-based anomaly detection tasks.
Large Language Models are Few-shot Generators: Proposing Hybrid Prompt Algorithm To Generate Webshell Escape Samples
Feb 12, 2024



The frequent occurrence of cyber-attacks has made webshell attacks and defense gradually become a research hotspot in the field of network security. However, the lack of publicly available benchmark datasets and the over-reliance on manually defined rules for webshell escape sample generation have slowed down the progress of research related to webshell escape sample generation strategies and artificial intelligence-based webshell detection algorithms. To address the drawbacks of weak webshell sample escape capabilities, the lack of webshell datasets with complex malicious features, and to promote the development of webshell detection technology, we propose the Hybrid Prompt algorithm for webshell escape sample generation with the help of large language models. As a prompt algorithm specifically developed for webshell sample generation, the Hybrid Prompt algorithm not only combines various prompt ideas including Chain of Thought, Tree of Thought, but also incorporates various components such as webshell hierarchical module and few-shot example to facilitate the LLM in learning and reasoning webshell escape strategies. Experimental results show that the Hybrid Prompt algorithm can work with multiple LLMs with excellent code reasoning ability to generate high-quality webshell samples with high Escape Rate (88.61% with GPT-4 model on VIRUSTOTAL detection engine) and Survival Rate (54.98% with GPT-4 model).
RFR-WWANet: Weighted Window Attention-Based Recovery Feature Resolution Network for Unsupervised Image Registration
May 07, 2023The Swin transformer has recently attracted attention in medical image analysis due to its computational efficiency and long-range modeling capability, which enables the establishment of more distant relationships between corresponding voxels. However, transformer-based models split images into tokens, which results in transformers that can only model and output coarse-grained spatial information representations. To address this issue, we propose Recovery Feature Resolution Network (RFRNet), which enables the transformer to contribute with fine-grained spatial information and rich semantic correspondences. Furthermore, shifted window partitioning operations are inflexible, indicating that they cannot perceive the semantic information over uncertain distances and automatically bridge the global connections between windows. Therefore, we present a Weighted Window Attention (WWA) to automatically build global interactions between windows after the regular and cyclic shifted window partitioning operations for Swin transformer blocks. The proposed unsupervised deformable image registration model, named RFR-WWANet, senses the long-range correlations, thereby facilitating meaningful semantic relevance of anatomical structures. Qualitative and quantitative results show that RFR-WWANet achieves significant performance improvements over baseline methods. Ablation experiments demonstrate the effectiveness of the RFRNet and WWA designs.
Symmetric Transformer-based Network for Unsupervised Image Registration
Apr 28, 2022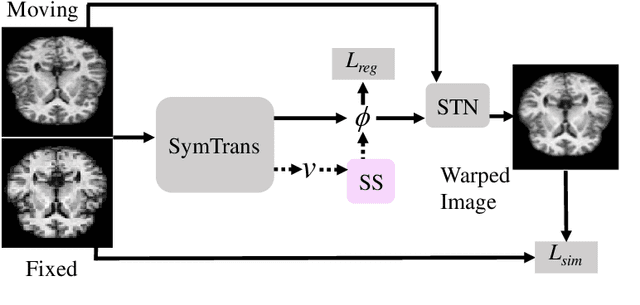
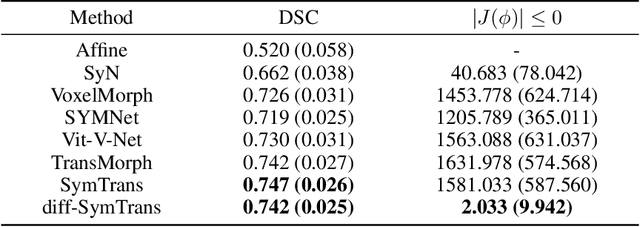
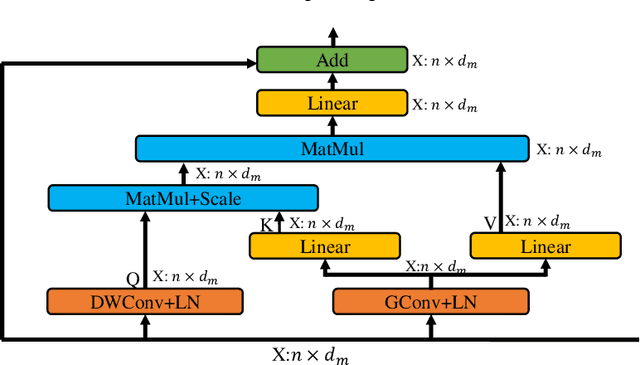

Medical image registration is a fundamental and critical task in medical image analysis. With the rapid development of deep learning, convolutional neural networks (CNN) have dominated the medical image registration field. Due to the disadvantage of the local receptive field of CNN, some recent registration methods have focused on using transformers for non-local registration. However, the standard Transformer has a vast number of parameters and high computational complexity, which causes Transformer can only be applied at the bottom of the registration models. As a result, only coarse information is available at the lowest resolution, limiting the contribution of Transformer in their models. To address these challenges, we propose a convolution-based efficient multi-head self-attention (CEMSA) block, which reduces the parameters of the traditional Transformer and captures local spatial context information for reducing semantic ambiguity in the attention mechanism. Based on the proposed CEMSA, we present a novel Symmetric Transformer-based model (SymTrans). SymTrans employs the Transformer blocks in the encoder and the decoder respectively to model the long-range spatial cross-image relevance. We apply SymTrans to the displacement field and diffeomorphic registration. Experimental results show that our proposed method achieves state-of-the-art performance in image registration. Our code is publicly available at \url{https://github.com/MingR-Ma/SymTrans}.