 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaMMS: Model Merging for Heterogeneous Multimodal Large Language Models with Unsupervised Coefficient Optimization
Mar 31, 2025Recently, model merging methods have demonstrated powerful strengths in combining abilities on various tasks from multiple Large Language Models (LLMs). While previous model merging methods mainly focus on merging homogeneous models with identical architecture, they meet challenges when dealing with Multimodal Large Language Models (MLLMs) with inherent heterogeneous property, including differences in model architecture and the asymmetry in the parameter space. In this work, we propose AdaMMS, a novel model merging method tailored for heterogeneous MLLMs. Our method tackles the challenges in three steps: mapping, merging and searching. Specifically, we first design mapping function between models to apply model merging on MLLMs with different architecture. Then we apply linear interpolation on model weights to actively adapt the asymmetry in the heterogeneous MLLMs. Finally in the hyper-parameter searching step, we propose an unsupervised hyper-parameter selection method for model merging. As the first model merging method capable of merging heterogeneous MLLMs without labeled data, extensive experiments on various model combinations demonstrated that AdaMMS outperforms previous model merging methods on various vision-language benchmarks.
LangGas: Introducing Language in Selective Zero-Shot Background Subtraction for Semi-Transparent Gas Leak Detection with a New Dataset
Mar 06, 2025



Gas leakage poses a significant hazard that requires prevention. Traditionally, human inspection has been used for detection, a slow and labour-intensive process. Recent research has applied machine learning techniques to this problem, yet there remains a shortage of high-quality, publicly available datasets. This paper introduces a synthetic dataset featuring diverse backgrounds, interfering foreground objects, diverse leak locations, and precise segmentation ground truth. We propose a zero-shot method that combines background subtraction, zero-shot object detection, filtering, and segmentation to leverage this dataset. Experimental results indicate that our approach significantly outperforms baseline methods based solely on background subtraction and zero-shot object detection with segmentation, reaching an IoU of 69\% overall. We also present an analysis of various prompt configurations and threshold settings to provide deeper insights into the performance of our method. The code and dataset will be released after publication.
Model Composition for Multimodal Large Language Models
Feb 20, 2024



Recent developments in Multimodal Large Language Models (MLLMs) have shown rapid progress, moving towards the goal of creating versatile MLLMs that understand inputs from various modalities. However, existing methods typically rely on joint training with paired multimodal instruction data, which is resource-intensive and challenging to extend to new modalities. In this paper, we propose a new paradigm through the model composition of existing MLLMs to create a new model that retains the modal understanding capabilities of each original model. Our basic implementation, NaiveMC, demonstrates the effectiveness of this paradigm by reusing modality encoders and merging LLM parameters. Furthermore, we introduce DAMC to address parameter interference and mismatch issues during the merging process, thereby enhancing the model performance. To facilitate research in this area, we propose MCUB, a benchmark for assessing ability of MLLMs to understand inputs from diverse modalities. Experiments on this benchmark and four other multimodal understanding tasks show significant improvements over baselines, proving that model composition can create a versatile model capable of processing inputs from multiple modalities.
Unleashing Potential of Evidence in Knowledge-Intensive Dialogue Generation
Sep 15, 2023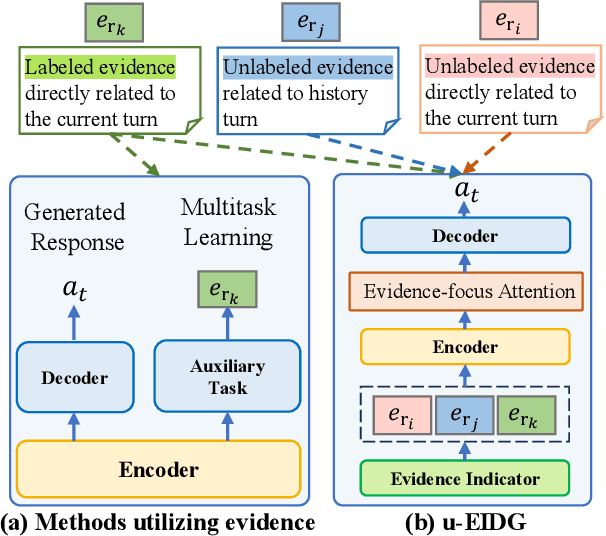



Incorporating external knowledge into dialogue generation (KIDG) is crucial for improving the correctness of response, where evidence fragments serve as knowledgeable snippets supporting the factual dialogue replies. However, introducing irrelevant content often adversely impacts reply quality and easily leads to hallucinated responses. Prior work on evidence retrieval and integration in dialogue systems falls short of fully leveraging existing evidence since the model fails to locate useful fragments accurately and overlooks hidden evidence labels within the KIDG dataset. To fully Unleash the potential of evidence, we propose a framework to effectively incorporate Evidence in knowledge-Intensive Dialogue Generation (u-EIDG). Specifically, we introduce an automatic evidence generation framework that harnesses the power of Large Language Models (LLMs) to mine reliable evidence veracity labels from unlabeled data. By utilizing these evidence labels, we train a reliable evidence indicator to effectively identify relevant evidence from retrieved passages. Furthermore, we propose an evidence-augmented generator with an evidence-focused attention mechanism, which allows the model to concentrate on evidenced segments. Experimental results on MultiDoc2Dial demonstrate the efficacy of evidential label augmentation and refined attention mechanisms in improving model performance. Further analysis confirms that the proposed method outperforms other baselines (+3~+5 points) regarding coherence and factual consistency.