 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view 3D Reconstruction with Transformer
Paper and Code
Mar 24, 2021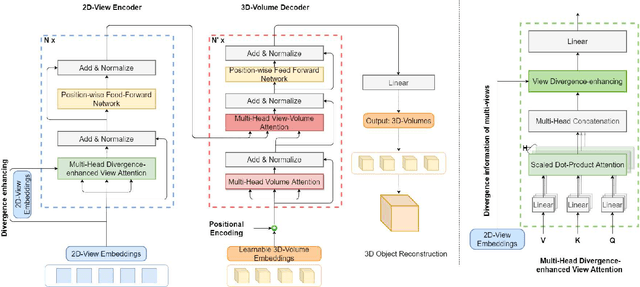



Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. Despite the considerable progress, the two core modules of these methods - multi-view feature extraction and fusion, are usually investigated separately, and the object relations in different views are rarely explored. In this paper, inspired by the recent great success in self-attention-based Transformer models, we reformulate the multi-view 3D reconstruction as a sequence-to-sequence prediction problem and propose a new framework named 3D Volume Transformer (VolT) for such a task. Unlike previous CNN-based methods using a separate design, we unify the feature extraction and view fusion in a single Transformer network. A natural advantage of our design lies in the exploration of view-to-view relationships using self-attention among multiple unordered inputs. On ShapeNet - a large-scale 3D reconstruction benchmark dataset, our method achieves a new state-of-the-art accuracy in multi-view reconstruction with fewer parameters ($70\%$ less) than other CNN-based methods. Experimental results also suggest the strong scaling capability of our method. Our code will be made publicly available.