 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fair Post-Processing Method based on the MADD Metric for Predictive Student Models
Jul 07, 2024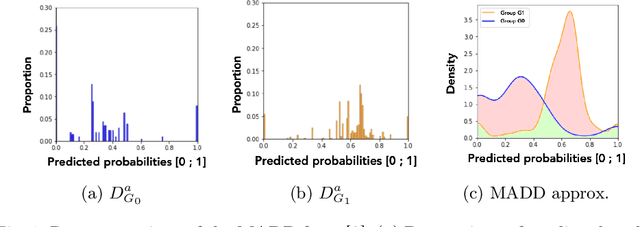

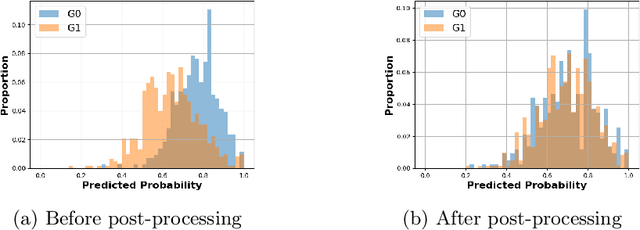
Predictive student models are increasingly used in learning environments. However, due to the rising social impact of their usage, it is now all the more important for these models to be both sufficiently accurate and fair in their predictions. To evaluate algorithmic fairness, a new metric has been developed in education, namely the Model Absolute Density Distance (MADD). This metric enables us to measure how different a predictive model behaves regarding two groups of students, in order to quantify its algorithmic unfairness. In this paper, we thus develop a post-processing method based on this metric, that aims at improving the fairness while preserving the accuracy of relevant predictive models' results. We experiment with our approach on the task of predicting student success in an online course, using both simulated and real-world educational data, and obtain successful results. Our source code and data are in open access at https://github.com/melinaverger/MADD .
Evaluating Algorithmic Bias in Models for Predicting Academic Performance of Filipino Students
May 16, 2024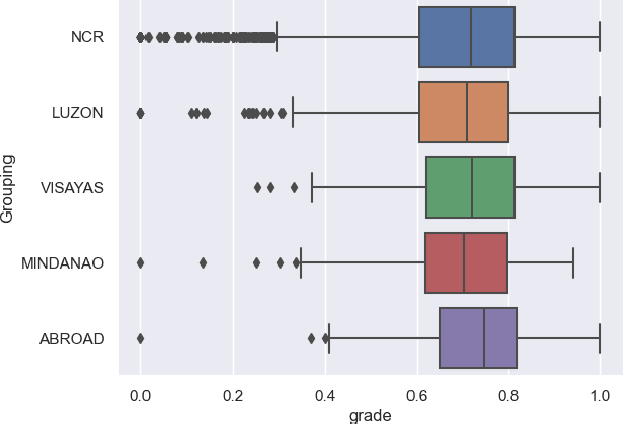
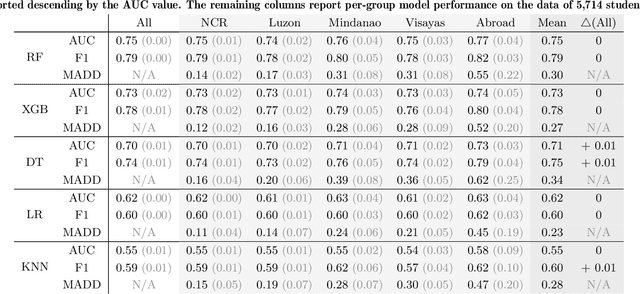
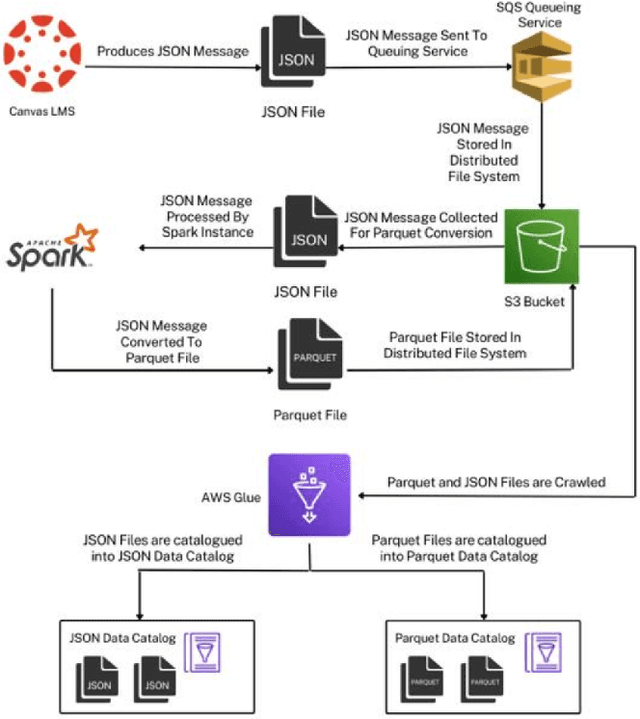
Algorithmic bias is a major issue in machine learning models in educational contexts. However, it has not yet been studied thoroughly in Asian learning contexts, and only limited work has considered algorithmic bias based on regional (sub-national) background. As a step towards addressing this gap, this paper examines the population of 5,986 students at a large university in the Philippines, investigating algorithmic bias based on students' regional background. The university used the Canvas learning management system (LMS) in its online courses across a broad range of domains. Over the period of three semesters, we collected 48.7 million log records of the students' activity in Canvas. We used these logs to train binary classification models that predict student grades from the LMS activity. The best-performing model reached AUC of 0.75 and weighted F1-score of 0.79. Subsequently, we examined the data for bias based on students' region. Evaluation using three metrics: AUC, weighted F1-score, and MADD showed consistent results across all demographic groups. Thus, no unfairness was observed against a particular student group in the grade predictions.
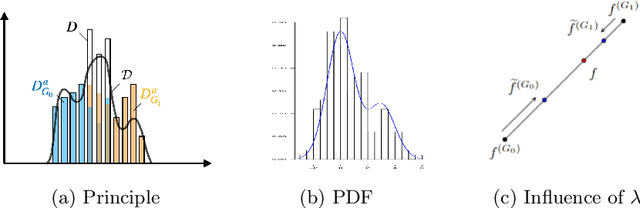
Is Your Model "MADD"? A Novel Metric to Evaluate Algorithmic Fairness for Predictive Student Models
May 24, 2023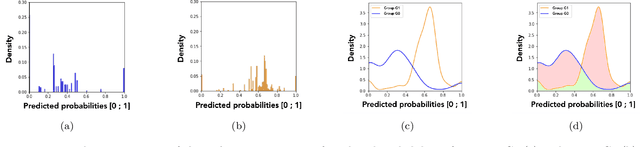

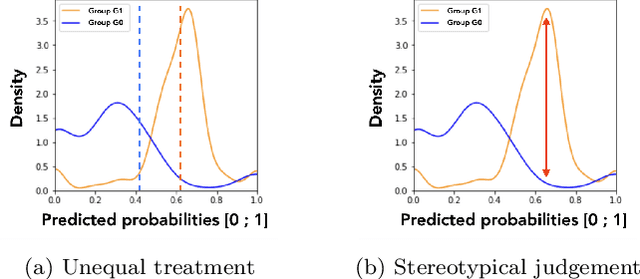
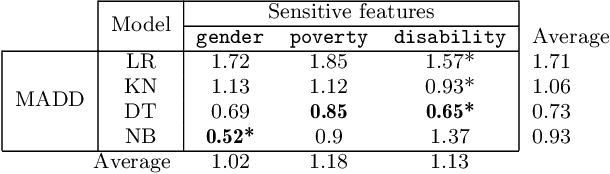
Predictive student models are increasingly used in learning environments due to their ability to enhance educational outcomes and support stakeholders in making informed decisions. However, predictive models can be biased and produce unfair outcomes, leading to potential discrimination against some students and possible harmful long-term implications. This has prompted research on fairness metrics meant to capture and quantify such biases. Nonetheless, so far, existing fairness metrics used in education are predictive performance-oriented, focusing on assessing biased outcomes across groups of students, without considering the behaviors of the models nor the severity of the biases in the outcomes. Therefore, we propose a novel metric, the Model Absolute Density Distance (MADD), to analyze models' discriminatory behaviors independently from their predictive performance. We also provide a complementary visualization-based analysis to enable fine-grained human assessment of how the models discriminate between groups of students. We evaluate our approach on the common task of predicting student success in online courses, using several common predictive classification models on an open educational dataset. We also compare our metric to the only predictive performance-oriented fairness metric developed in education, ABROCA. Results on this dataset show that: (1) fair predictive performance does not guarantee fair models' behaviors and thus fair outcomes, (2) there is no direct relationship between data bias and predictive performance bias nor discriminatory behaviors bias, and (3) trained on the same data, models exhibit different discriminatory behaviors, according to different sensitive features too. We thus recommend using the MADD on models that show satisfying predictive performance, to gain a finer-grained understanding on how they behave and to refine models selection and their usage.
A Framework to Counteract Suboptimal User-Behaviors in Exploratory Learning Environments: an Application to MOOCs
Jun 14, 2021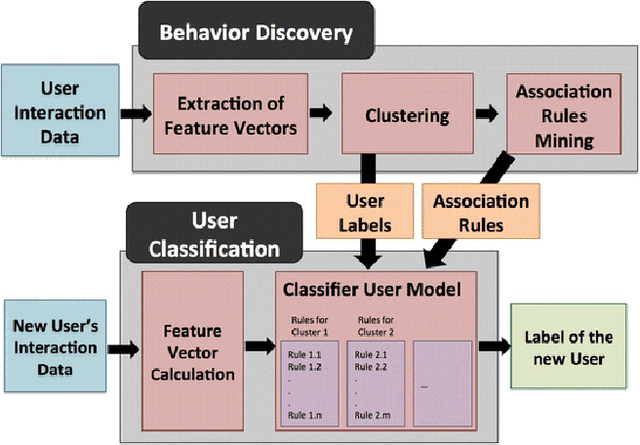

While there is evidence that user-adaptive support can greatly enhance the effectiveness of educational systems, designing such support for exploratory learning environments (e.g., simulations) is still challenging due to the open-ended nature of their interaction. In particular, there is little a priori knowledge of which student's behaviors can be detrimental to learning in such environments. To address this problem, we focus on a data-driven user-modeling framework that uses logged interaction data to learn which behavioral or activity patterns should trigger help during interaction with a specific learning environment. This framework has been successfully used to provide adaptive support in interactive learning simulations. Here we present a novel application of this framework we are working on, namely to Massive Open Online Courses (MOOCs), a form of exploratory environment that could greatly benefit from adaptive support due to the large diversity of their users, but typically lack of such adaptation. We describe an experiment aimed at investigating the value of our framework to identify student's behaviors that can justify adapting to, and report some preliminary results.