 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fair Post-Processing Method based on the MADD Metric for Predictive Student Models
Jul 07, 2024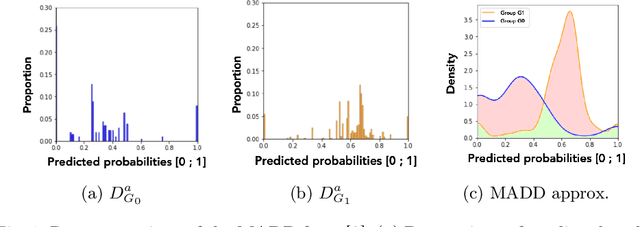

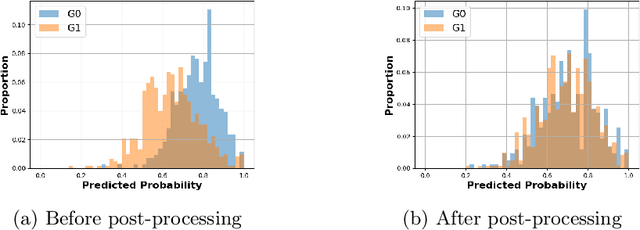
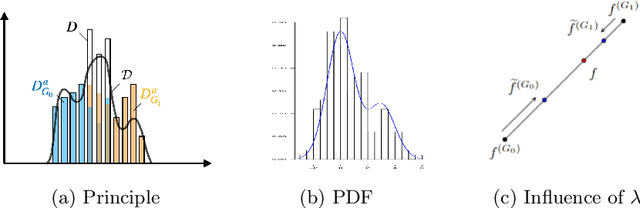
Predictive student models are increasingly used in learning environments. However, due to the rising social impact of their usage, it is now all the more important for these models to be both sufficiently accurate and fair in their predictions. To evaluate algorithmic fairness, a new metric has been developed in education, namely the Model Absolute Density Distance (MADD). This metric enables us to measure how different a predictive model behaves regarding two groups of students, in order to quantify its algorithmic unfairness. In this paper, we thus develop a post-processing method based on this metric, that aims at improving the fairness while preserving the accuracy of relevant predictive models' results. We experiment with our approach on the task of predicting student success in an online course, using both simulated and real-world educational data, and obtain successful results. Our source code and data are in open access at https://github.com/melinaverger/MADD .
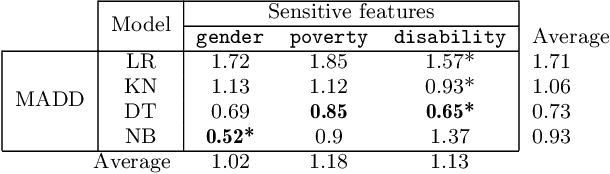
Is Your Model "MADD"? A Novel Metric to Evaluate Algorithmic Fairness for Predictive Student Models
May 24, 2023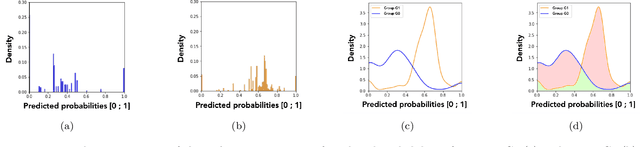

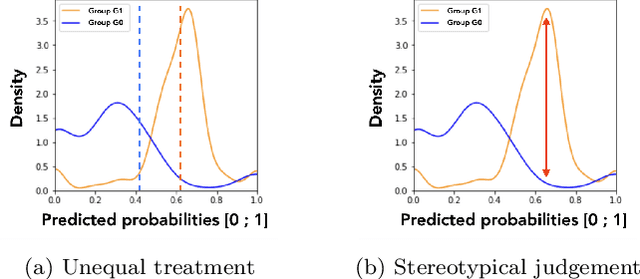
Predictive student models are increasingly used in learning environments due to their ability to enhance educational outcomes and support stakeholders in making informed decisions. However, predictive models can be biased and produce unfair outcomes, leading to potential discrimination against some students and possible harmful long-term implications. This has prompted research on fairness metrics meant to capture and quantify such biases. Nonetheless, so far, existing fairness metrics used in education are predictive performance-oriented, focusing on assessing biased outcomes across groups of students, without considering the behaviors of the models nor the severity of the biases in the outcomes. Therefore, we propose a novel metric, the Model Absolute Density Distance (MADD), to analyze models' discriminatory behaviors independently from their predictive performance. We also provide a complementary visualization-based analysis to enable fine-grained human assessment of how the models discriminate between groups of students. We evaluate our approach on the common task of predicting student success in online courses, using several common predictive classification models on an open educational dataset. We also compare our metric to the only predictive performance-oriented fairness metric developed in education, ABROCA. Results on this dataset show that: (1) fair predictive performance does not guarantee fair models' behaviors and thus fair outcomes, (2) there is no direct relationship between data bias and predictive performance bias nor discriminatory behaviors bias, and (3) trained on the same data, models exhibit different discriminatory behaviors, according to different sensitive features too. We thus recommend using the MADD on models that show satisfying predictive performance, to gain a finer-grained understanding on how they behave and to refine models selection and their usage.