 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive White-Box Watermarking with Self-Mutual Check Parameters in Deep Neural Networks
Aug 22, 2023



Artificial Intelligence (AI) has found wide application, but also poses risks due to unintentional or malicious tampering during deployment. Regular checks are therefore necessary to detect and prevent such risks. Fragile watermarking is a technique used to identify tampering in AI models. However, previous methods have faced challenges including risks of omission, additional information transmission, and inability to locate tampering precisely. In this paper, we propose a method for detecting tampered parameters and bits, which can be used to detect, locate, and restore parameters that have been tampered with. We also propose an adaptive embedding method that maximizes information capacity while maintaining model accuracy. Our approach was tested on multiple neural networks subjected to attacks that modified weight parameters, and our results demonstrate that our method achieved great recovery performance when the modification rate was below 20%. Furthermore, for models where watermarking significantly affected accuracy, we utilized an adaptive bit technique to recover more than 15% of the accuracy loss of the model.
AdvFAS: A robust face anti-spoofing framework against adversarial examples
Aug 04, 2023Ensuring the reliability of face recognition systems against presentation attacks necessitates the deployment of face anti-spoofing techniques. Despite considerable advancements in this domain, the ability of even the most state-of-the-art methods to defend against adversarial examples remains elusive. While several adversarial defense strategies have been proposed, they typically suffer from constrained practicability due to inevitable trade-offs between universality, effectiveness, and efficiency. To overcome these challenges, we thoroughly delve into the coupled relationship between adversarial detection and face anti-spoofing. Based on this, we propose a robust face anti-spoofing framework, namely AdvFAS, that leverages two coupled scores to accurately distinguish between correctly detected and wrongly detected face images. Extensive experiments demonstrate the effectiveness of our framework in a variety of settings, including different attacks, datasets, and backbones, meanwhile enjoying high accuracy on clean examples. Moreover, we successfully apply the proposed method to detect real-world adversarial examples.
Augmenting Greybox Fuzzing with Generative AI
Jun 11, 2023Real-world programs expecting structured inputs often has a format-parsing stage gating the deeper program space. Neither a mutation-based approach nor a generative approach can provide a solution that is effective and scalable. Large language models (LLM) pre-trained with an enormous amount of natural language corpus have proved to be effective for understanding the implicit format syntax and generating format-conforming inputs. In this paper, propose ChatFuzz, a greybox fuzzer augmented by generative AI. More specifically, we pick a seed in the fuzzer's seed pool and prompt ChatGPT generative models to variations, which are more likely to be format-conforming and thus of high quality. We conduct extensive experiments to explore the best practice for harvesting the power of generative LLM models. The experiment results show that our approach improves the edge coverage by 12.77\% over the SOTA greybox fuzzer (AFL++) on 12 target programs from three well-tested benchmarks. As for vulnerability detection, \sys is able to perform similar to or better than AFL++ for programs with explicit syntax rules but not for programs with non-trivial syntax.
Decision-based iterative fragile watermarking for model integrity verification
May 13, 2023



Typically, foundation models are hosted on cloud servers to meet the high demand for their services. However, this exposes them to security risks, as attackers can modify them after uploading to the cloud or transferring from a local system. To address this issue, we propose an iterative decision-based fragile watermarking algorithm that transforms normal training samples into fragile samples that are sensitive to model changes. We then compare the output of sensitive samples from the original model to that of the compromised model during validation to assess the model's completeness.The proposed fragile watermarking algorithm is an optimization problem that aims to minimize the variance of the predicted probability distribution outputed by the target model when fed with the converted sample.We convert normal samples to fragile samples through multiple iterations. Our method has some advantages: (1) the iterative update of samples is done in a decision-based black-box manner, relying solely on the predicted probability distribution of the target model, which reduces the risk of exposure to adversarial attacks, (2) the small-amplitude multiple iterations approach allows the fragile samples to perform well visually, with a PSNR of 55 dB in TinyImageNet compared to the original samples, (3) even with changes in the overall parameters of the model of magnitude 1e-4, the fragile samples can detect such changes, and (4) the method is independent of the specific model structure and dataset. We demonstrate the effectiveness of our method on multiple models and datasets, and show that it outperforms the current state-of-the-art.
Neural network fragile watermarking with no model performance degradation
Aug 16, 2022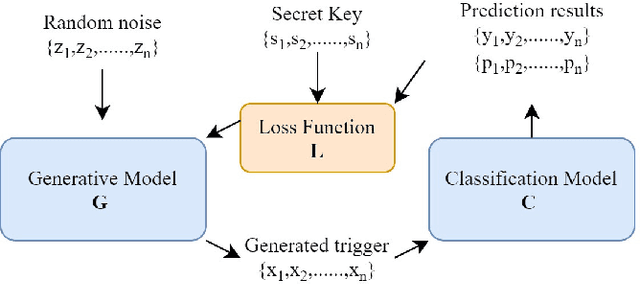



Deep neural networks are vulnerable to malicious fine-tuning attacks such as data poisoning and backdoor attacks. Therefore, in recent research, it is proposed how to detect malicious fine-tuning of neural network models. However, it usually negatively affects the performance of the protected model. Thus, we propose a novel neural network fragile watermarking with no model performance degradation. In the process of watermarking, we train a generative model with the specific loss function and secret key to generate triggers that are sensitive to the fine-tuning of the target classifier. In the process of verifying, we adopt the watermarked classifier to get labels of each fragile trigger. Then, malicious fine-tuning can be detected by comparing secret keys and labels. Experiments on classic datasets and classifiers show that the proposed method can effectively detect model malicious fine-tuning with no model performance degradation.
Improving the Transferability of Adversarial Examples with the Adam Optimizer
Dec 01, 2020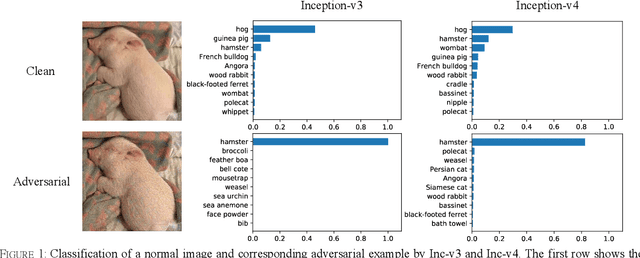
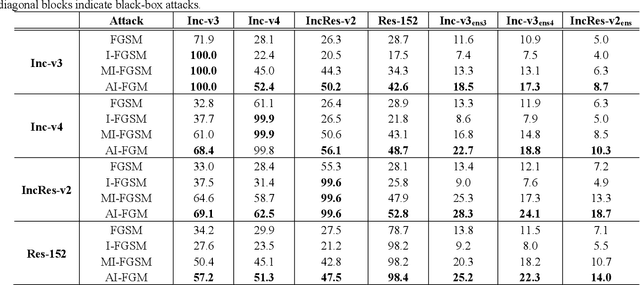
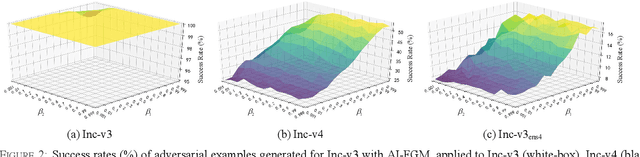
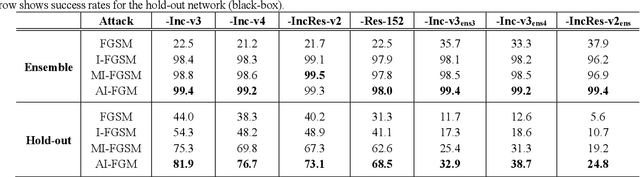
Convolutional neural networks have outperformed humans in image recognition tasks, but they remain vulnerable to attacks from adversarial examples. Since these data are produced by adding imperceptible noise to normal images, their existence poses potential security threats to deep learning systems. Sophisticated adversarial examples with strong attack performance can also be used as a tool to evaluate the robustness of a model. However, the success rate of adversarial attacks remains to be further improved in black-box environments. Therefore, this study combines an improved Adam gradient descent algorithm with the iterative gradient-based attack method. The resulting Adam Iterative Fast Gradient Method is then used to improve the transferability of adversarial examples. Extensive experiments on ImageNet showed that the proposed method offers a higher attack success rate than existing iterative methods. Our best black-box attack achieved a success rate of 81.9% on a normally trained network and 38.7% on an adversarially trained network.
Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection
Jul 27, 2018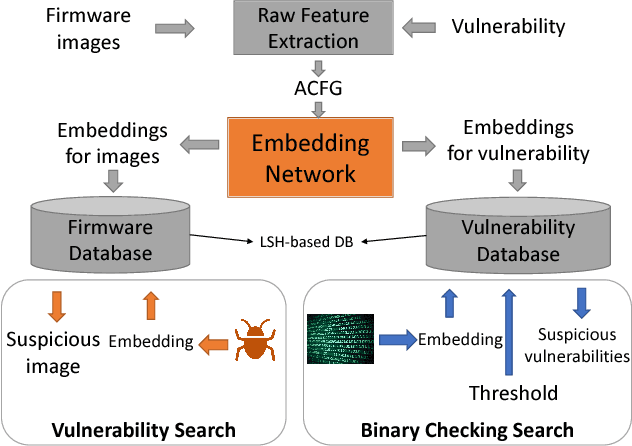
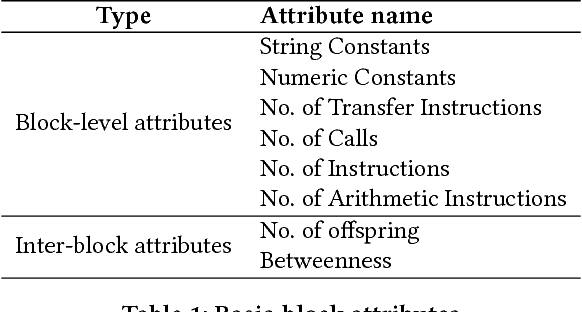
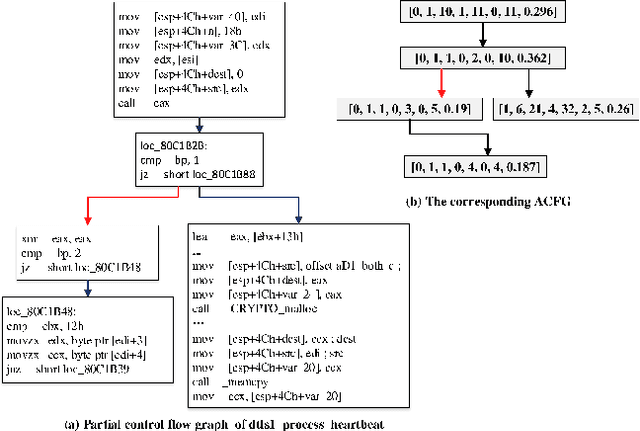
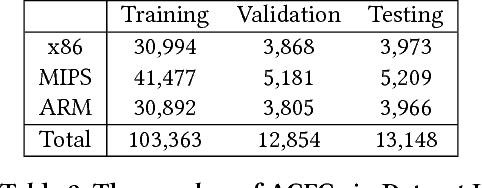
The problem of cross-platform binary code similarity detection aims at detecting whether two binary functions coming from different platforms are similar or not. It has many security applications, including plagiarism detection, malware detection, vulnerability search, etc. Existing approaches rely on approximate graph matching algorithms, which are inevitably slow and sometimes inaccurate, and hard to adapt to a new task. To address these issues, in this work, we propose a novel neural network-based approach to compute the embedding, i.e., a numeric vector, based on the control flow graph of each binary function, then the similarity detection can be done efficiently by measuring the distance between the embeddings for two functions. We implement a prototype called Gemini. Our extensive evaluation shows that Gemini outperforms the state-of-the-art approaches by large margins with respect to similarity detection accuracy. Further, Gemini can speed up prior art's embedding generation time by 3 to 4 orders of magnitude and reduce the required training time from more than 1 week down to 30 minutes to 10 hours. Our real world case studies demonstrate that Gemini can identify significantly more vulnerable firmware images than the state-of-the-art, i.e., Genius. Our research showcases a successful application of deep learning on computer security problems.