 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural network fragile watermarking with no model performance degradation
Paper and Code
Aug 16, 2022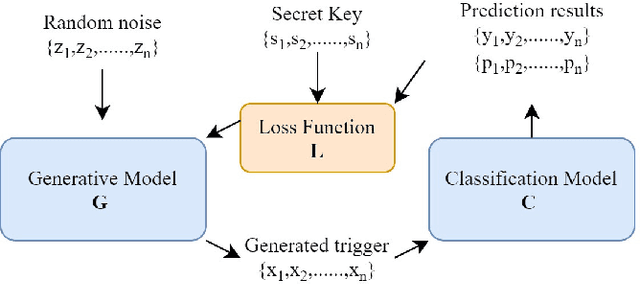



Deep neural networks are vulnerable to malicious fine-tuning attacks such as data poisoning and backdoor attacks. Therefore, in recent research, it is proposed how to detect malicious fine-tuning of neural network models. However, it usually negatively affects the performance of the protected model. Thus, we propose a novel neural network fragile watermarking with no model performance degradation. In the process of watermarking, we train a generative model with the specific loss function and secret key to generate triggers that are sensitive to the fine-tuning of the target classifier. In the process of verifying, we adopt the watermarked classifier to get labels of each fragile trigger. Then, malicious fine-tuning can be detected by comparing secret keys and labels. Experiments on classic datasets and classifiers show that the proposed method can effectively detect model malicious fine-tuning with no model performance degradation.