 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Copyright of Medical Pre-trained Language Models: Training-Free Backdoor Watermarking
Sep 14, 2024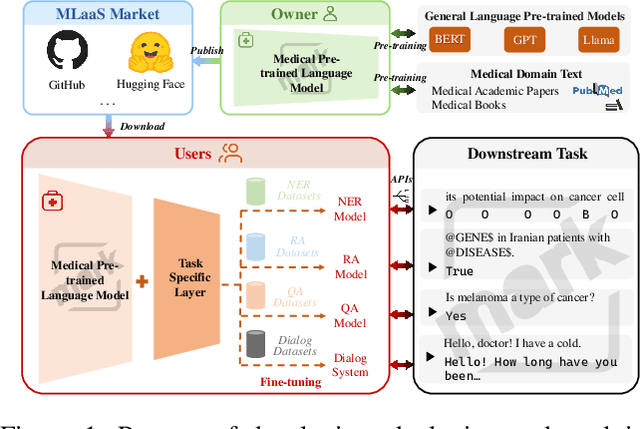



Pre-training language models followed by fine-tuning on specific tasks is standard in NLP, but traditional models often underperform when applied to the medical domain, leading to the development of specialized medical pre-trained language models (Med-PLMs). These models are valuable assets but are vulnerable to misuse and theft, requiring copyright protection. However, no existing watermarking methods are tailored for Med-PLMs, and adapting general PLMs watermarking techniques to the medical domain faces challenges such as task incompatibility, loss of fidelity, and inefficiency. To address these issues, we propose the first training-free backdoor watermarking method for Med-PLMs. Our method uses rare special symbols as trigger words, which do not impact downstream task performance, embedding watermarks by replacing their original embeddings with those of specific medical terms in the Med-PLMs' word embeddings layer. After fine-tuning the watermarked Med-PLMs on various medical downstream tasks, the final models (FMs) respond to the trigger words in the same way they would to the corresponding medical terms. This property can be utilized to extract the watermark. Experiments demonstrate that our method achieves high fidelity while effectively extracting watermarks across various medical downstream tasks. Additionally, our method demonstrates robustness against various attacks and significantly enhances the efficiency of watermark embedding, reducing the embedding time from 10 hours to 10 seconds.