 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating proton PBS treatment planning for head and neck cancers using policy gradient-based deep reinforcement learning
Sep 17, 2024

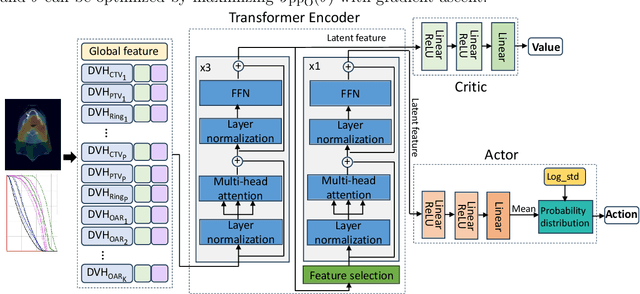

Proton pencil beam scanning (PBS) treatment planning for head and neck (H&N) cancers is a time-consuming and experience-demanding task where a large number of planning objectives are involved. Deep reinforcement learning (DRL) has recently been introduced to the planning processes of intensity-modulated radiation therapy and brachytherapy for prostate, lung, and cervical cancers. However, existing approaches are built upon the Q-learning framework and weighted linear combinations of clinical metrics, suffering from poor scalability and flexibility and only capable of adjusting a limited number of planning objectives in discrete action spaces. We propose an automatic treatment planning model using the proximal policy optimization (PPO) algorithm and a dose distribution-based reward function for proton PBS treatment planning of H&N cancers. Specifically, a set of empirical rules is used to create auxiliary planning structures from target volumes and organs-at-risk (OARs), along with their associated planning objectives. These planning objectives are fed into an in-house optimization engine to generate the spot monitor unit (MU) values. A decision-making policy network trained using PPO is developed to iteratively adjust the involved planning objective parameters in a continuous action space and refine the PBS treatment plans using a novel dose distribution-based reward function. Proton H&N treatment plans generated by the model show improved OAR sparing with equal or superior target coverage when compared with human-generated plans. Moreover, additional experiments on liver cancer demonstrate that the proposed method can be successfully generalized to other treatment sites. To the best of our knowledge, this is the first DRL-based automatic treatment planning model capable of achieving human-level performance for H&N cancers.
Adaptive Graph-Based Feature Normalization for Facial Expression Recognition
Jul 22, 2022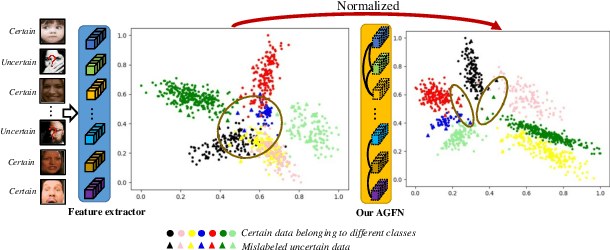
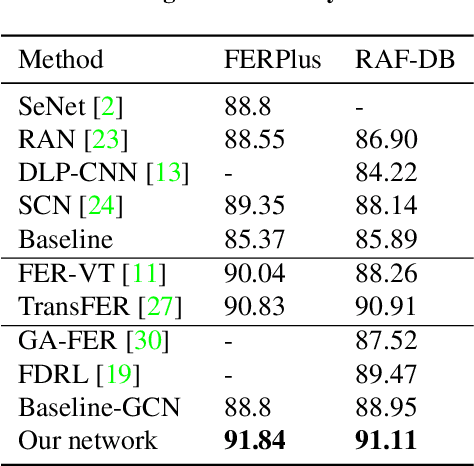
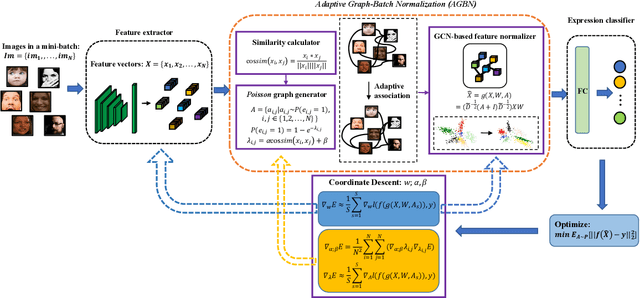
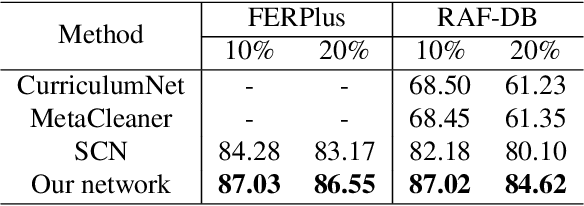
Facial Expression Recognition (FER) suffers from data uncertainties caused by ambiguous facial images and annotators' subjectiveness, resulting in excursive semantic and feature covariate shifting problem. Existing works usually correct mislabeled data by estimating noise distribution, or guide network training with knowledge learned from clean data, neglecting the associative relations of expressions. In this work, we propose an Adaptive Graph-based Feature Normalization (AGFN) method to protect FER models from data uncertainties by normalizing feature distributions with the association of expressions. Specifically, we propose a Poisson graph generator to adaptively construct topological graphs for samples in each mini-batches via a sampling process, and correspondingly design a coordinate descent strategy to optimize proposed network. Our method outperforms state-of-the-art works with accuracies of 91.84% and 91.11% on the benchmark datasets FERPlus and RAF-DB, respectively, and when the percentage of mislabeled data increases (e.g., to 20%), our network surpasses existing works significantly by 3.38% and 4.52%.
See More Than Once -- Kernel-Sharing Atrous Convolution for Semantic Segmentation
Sep 09, 2019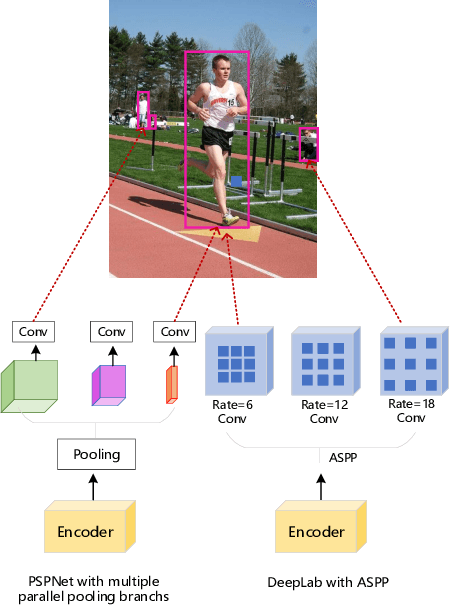
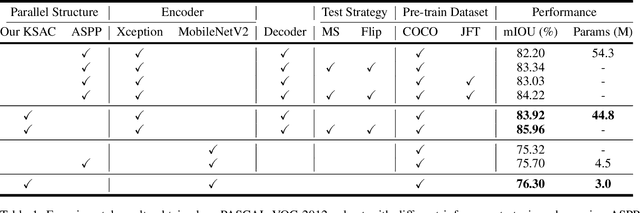
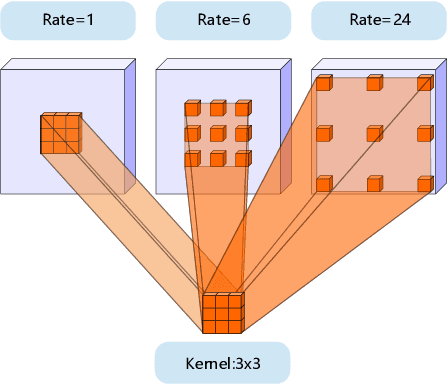
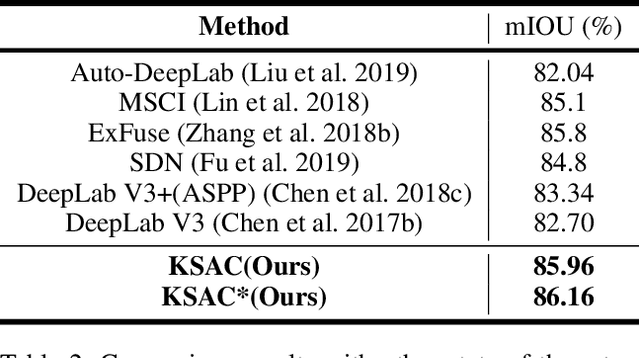
The state-of-the-art semantic segmentation solutions usually leverage different receptive fields via multiple parallel branches to handle objects with different sizes. However, employing separate kernels for individual branches degrades the generalization and representation abilities of the network, and the amount of parameters increases by the times of the number of branches. To tackle this problem, we propose a novel network structure namely Kernel-Sharing Atrous Convolution (KSAC), where branches of different receptive fields share the same kernel, i.e., let a single kernel `see' the input feature maps more than once with different receptive fields, to facilitate communication among branches and perform `feature augmentation' inside the network. Experiments conducted on the benchmark VOC 2012 dataset show that the proposed sharing strategy can not only boost network's generalization and representation abilities but also reduce the model complexity significantly. Specifically, when compared with DeepLabV3+ equipped with MobileNetv2 backbone, 33% parameters are reduced together with an mIOU improvement of 0.6%. When Xception is used as the backbone, the mIOU is elevated from 83.34% to 85.96% with about 10M parameters saved. In addition, different from the widely used ASPP structure, our proposed KSAC is able to further improve the mIOU by taking benefit of wider context with larger atrous rates.
FACLSTM: ConvLSTM with Focused Attention for Scene Text Recognition
Apr 20, 2019



Scene text recognition has recently been widely treated as a sequence-to-sequence prediction problem, where traditional fully-connected-LSTM (FC-LSTM) has played a critical role. Due to the limitation of FC-LSTM, existing methods have to convert 2-D feature maps into 1-D sequential feature vectors, resulting in severe damages of the valuable spatial and structural information of text images. In this paper, we argue that scene text recognition is essentially a spatiotemporal prediction problem for its 2-D image inputs, and propose a convolution LSTM (ConvLSTM)-based scene text recognizer, namely, FACLSTM, i.e., Focused Attention ConvLSTM, where the spatial correlation of pixels is fully leveraged when performing sequential prediction with LSTM. Particularly, the attention mechanism is properly incorporated into an efficient ConvLSTM structure via the convolutional operations and additional character center masks are generated to help focus attention on right feature areas. The experimental results on benchmark datasets IIIT5K, SVT and CUTE demonstrate that our proposed FACLSTM performs competitively on the regular, low-resolution and noisy text images, and outperforms the state-of-the-art approaches on the curved text with large margins.
Handwritten digit string recognition by combination of residual network and RNN-CTC
Oct 09, 2017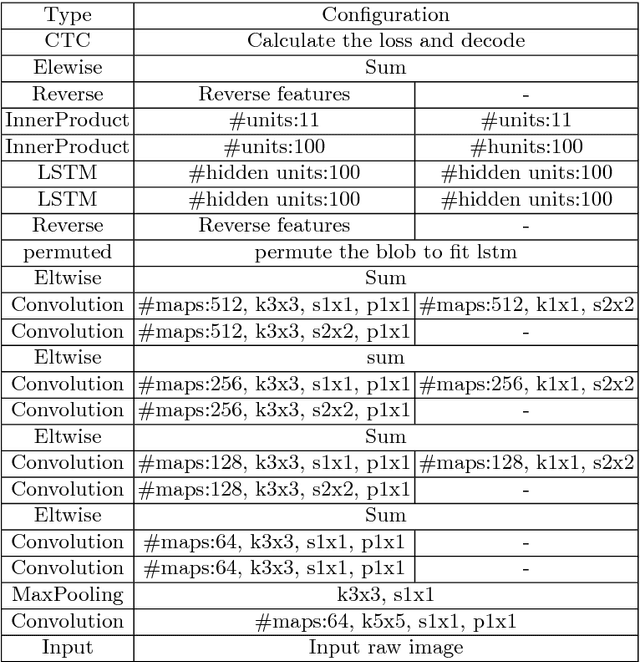
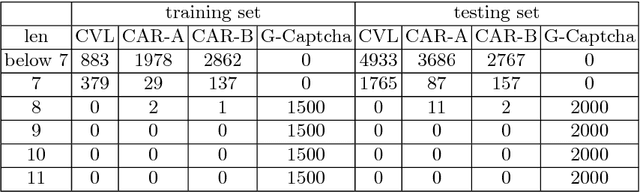
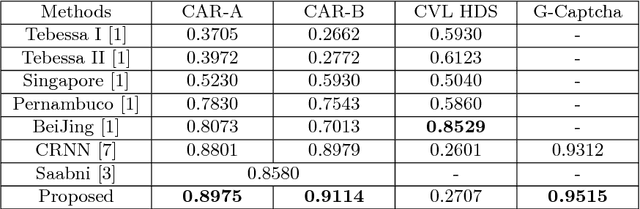
Recurrent neural network (RNN) and connectionist temporal classification (CTC) have showed successes in many sequence labeling tasks with the strong ability of dealing with the problems where the alignment between the inputs and the target labels is unknown. Residual network is a new structure of convolutional neural network and works well in various computer vision tasks. In this paper, we take advantage of the architectures mentioned above to create a new network for handwritten digit string recognition. First we design a residual network to extract features from input images, then we employ a RNN to model the contextual information within feature sequences and predict recognition results. At the top of this network, a standard CTC is applied to calculate the loss and yield the final results. These three parts compose an end-to-end trainable network. The proposed new architecture achieves the highest performances on ORAND-CAR-A and ORAND-CAR-B with recognition rates 89.75% and 91.14%, respectively. In addition, the experiments on a generated captcha dataset which has much longer string length show the potential of the proposed network to handle long strings.