 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient reductions from a Gaussian source with applications to statistical-computational tradeoffs
Oct 08, 2025Given a single observation from a Gaussian distribution with unknown mean $\theta$, we design computationally efficient procedures that can approximately generate an observation from a different target distribution $Q_{\theta}$ uniformly for all $\theta$ in a parameter set. We leverage our technique to establish reduction-based computational lower bounds for several canonical high-dimensional statistical models under widely-believed conjectures in average-case complexity. In particular, we cover cases in which: 1. $Q_{\theta}$ is a general location model with non-Gaussian distribution, including both light-tailed examples (e.g., generalized normal distributions) and heavy-tailed ones (e.g., Student's $t$-distributions). As a consequence, we show that computational lower bounds proved for spiked tensor PCA with Gaussian noise are universal, in that they extend to other non-Gaussian noise distributions within our class. 2. $Q_{\theta}$ is a normal distribution with mean $f(\theta)$ for a general, smooth, and nonlinear link function $f:\mathbb{R} \rightarrow \mathbb{R}$. Using this reduction, we construct a reduction from symmetric mixtures of linear regressions to generalized linear models with link function $f$, and establish computational lower bounds for solving the $k$-sparse generalized linear model when $f$ is an even function. This result constitutes the first reduction-based confirmation of a $k$-to-$k^2$ statistical-to-computational gap in $k$-sparse phase retrieval, resolving a conjecture posed by Cai et al. (2016). As a second application, we construct a reduction from the sparse rank-1 submatrix model to the planted submatrix model, establishing a pointwise correspondence between the phase diagrams of the two models that faithfully preserves regions of computational hardness and tractability.
Efficient reductions between some statistical models
Feb 12, 2024We study the problem of approximately transforming a sample from a source statistical model to a sample from a target statistical model without knowing the parameters of the source model, and construct several computationally efficient such reductions between statistical experiments. In particular, we provide computationally efficient procedures that approximately reduce uniform, Erlang, and Laplace location models to general target families. We illustrate our methodology by establishing nonasymptotic reductions between some canonical high-dimensional problems, spanning mixtures of experts, phase retrieval, and signal denoising. Notably, the reductions are structure preserving and can accommodate missing data. We also point to a possible application in transforming one differentially private mechanism to another.
Hyperparameter tuning via trajectory predictions: Stochastic prox-linear methods in matrix sensing
Feb 02, 2024Motivated by the desire to understand stochastic algorithms for nonconvex optimization that are robust to their hyperparameter choices, we analyze a mini-batched prox-linear iterative algorithm for the problem of recovering an unknown rank-1 matrix from rank-1 Gaussian measurements corrupted by noise. We derive a deterministic recursion that predicts the error of this method and show, using a non-asymptotic framework, that this prediction is accurate for any batch-size and a large range of step-sizes. In particular, our analysis reveals that this method, though stochastic, converges linearly from a local initialization with a fixed step-size to a statistical error floor. Our analysis also exposes how the batch-size, step-size, and noise level affect the (linear) convergence rate and the eventual statistical estimation error, and we demonstrate how to use our deterministic predictions to perform hyperparameter tuning (e.g. step-size and batch-size selection) without ever running the method. On a technical level, our analysis is enabled in part by showing that the fluctuations of the empirical iterates around our deterministic predictions scale with the error of the previous iterate.
Do algorithms and barriers for sparse principal component analysis extend to other structured settings?
Jul 25, 2023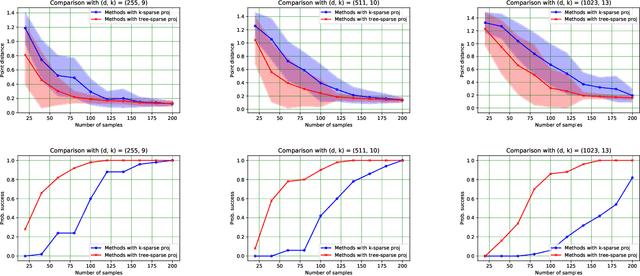
We study a principal component analysis problem under the spiked Wishart model in which the structure in the signal is captured by a class of union-of-subspace models. This general class includes vanilla sparse PCA as well as its variants with graph sparsity. With the goal of studying these problems under a unified statistical and computational lens, we establish fundamental limits that depend on the geometry of the problem instance, and show that a natural projected power method exhibits local convergence to the statistically near-optimal neighborhood of the solution. We complement these results with end-to-end analyses of two important special cases given by path and tree sparsity in a general basis, showing initialization methods and matching evidence of computational hardness. Overall, our results indicate that several of the phenomena observed for vanilla sparse PCA extend in a natural fashion to its structured counterparts.
Alternating minimization for generalized rank one matrix sensing: Sharp predictions from a random initialization
Jul 20, 2022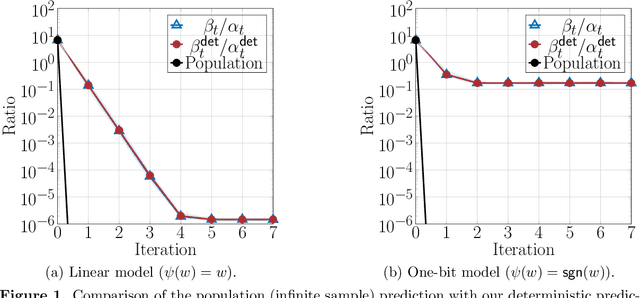
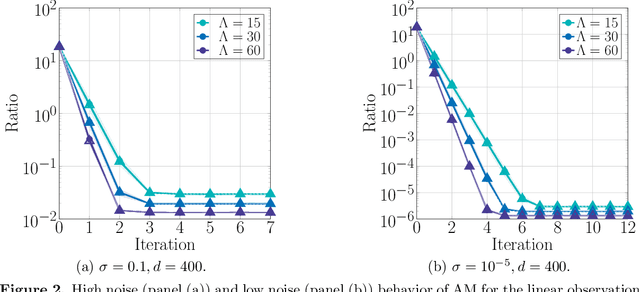
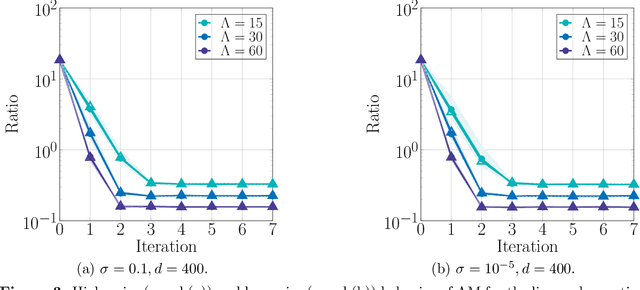
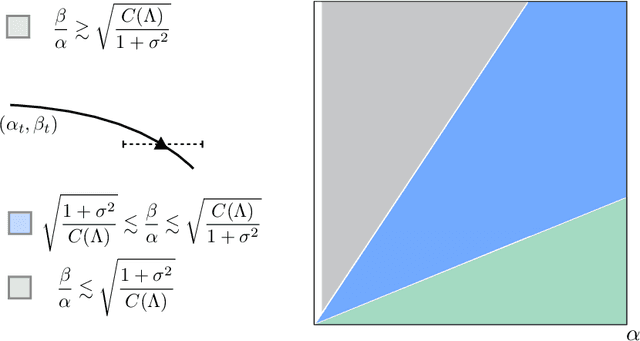
We consider the problem of estimating the factors of a rank-$1$ matrix with i.i.d. Gaussian, rank-$1$ measurements that are nonlinearly transformed and corrupted by noise. Considering two prototypical choices for the nonlinearity, we study the convergence properties of a natural alternating update rule for this nonconvex optimization problem starting from a random initialization. We show sharp convergence guarantees for a sample-split version of the algorithm by deriving a deterministic recursion that is accurate even in high-dimensional problems. Notably, while the infinite-sample population update is uninformative and suggests exact recovery in a single step, the algorithm -- and our deterministic prediction -- converges geometrically fast from a random initialization. Our sharp, non-asymptotic analysis also exposes several other fine-grained properties of this problem, including how the nonlinearity and noise level affect convergence behavior. On a technical level, our results are enabled by showing that the empirical error recursion can be predicted by our deterministic sequence within fluctuations of the order $n^{-1/2}$ when each iteration is run with $n$ observations. Our technique leverages leave-one-out tools originating in the literature on high-dimensional $M$-estimation and provides an avenue for sharply analyzing higher-order iterative algorithms from a random initialization in other high-dimensional optimization problems with random data.