 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMPose3D: monocular 3D pose estimation via flow matching
Feb 05, 2026Monocular 3D pose estimation is fundamentally ill-posed due to depth ambiguity and occlusions, thereby motivating probabilistic methods that generate multiple plausible 3D pose hypotheses. In particular, diffusion-based models have recently demonstrated strong performance, but their iterative denoising process typically requires many timesteps for each prediction, making inference computationally expensive. In contrast, we leverage Flow Matching (FM) to learn a velocity field defined by an Ordinary Differential Equation (ODE), enabling efficient generation of 3D pose samples with only a few integration steps. We propose a novel generative pose estimation framework, FMPose3D, that formulates 3D pose estimation as a conditional distribution transport problem. It continuously transports samples from a standard Gaussian prior to the distribution of plausible 3D poses conditioned only on 2D inputs. Although ODE trajectories are deterministic, FMPose3D naturally generates various pose hypotheses by sampling different noise seeds. To obtain a single accurate prediction from those hypotheses, we further introduce a Reprojection-based Posterior Expectation Aggregation (RPEA) module, which approximates the Bayesian posterior expectation over 3D hypotheses. FMPose3D surpasses existing methods on the widely used human pose estimation benchmarks Human3.6M and MPI-INF-3DHP, and further achieves state-of-the-art performance on the 3D animal pose datasets Animal3D and CtrlAni3D, demonstrating strong performance across both 3D pose domains. The code is available at https://github.com/AdaptiveMotorControlLab/FMPose3D.
Dual-Branch Graph Transformer Network for 3D Human Mesh Reconstruction from Video
Dec 02, 2024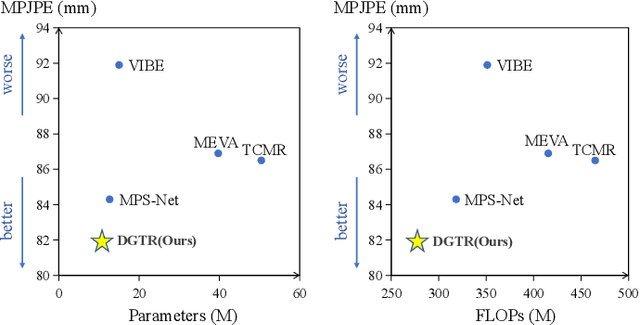
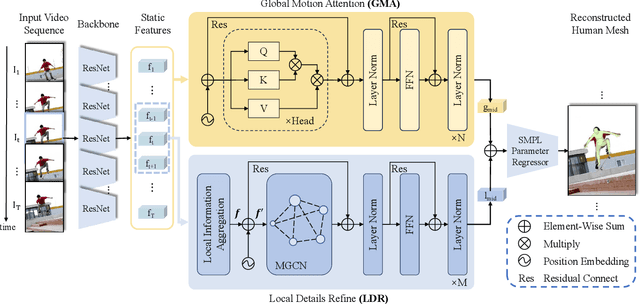

Human Mesh Reconstruction (HMR) from monocular video plays an important role in human-robot interaction and collaboration. However, existing video-based human mesh reconstruction methods face a trade-off between accurate reconstruction and smooth motion. These methods design networks based on either RNNs or attention mechanisms to extract local temporal correlations or global temporal dependencies, but the lack of complementary long-term information and local details limits their performance. To address this problem, we propose a \textbf{D}ual-branch \textbf{G}raph \textbf{T}ransformer network for 3D human mesh \textbf{R}econstruction from video, named DGTR. DGTR employs a dual-branch network including a Global Motion Attention (GMA) branch and a Local Details Refine (LDR) branch to parallelly extract long-term dependencies and local crucial information, helping model global human motion and local human details (e.g., local motion, tiny movement). Specifically, GMA utilizes a global transformer to model long-term human motion. LDR combines modulated graph convolutional networks and the transformer framework to aggregate local information in adjacent frames and extract crucial information of human details. Experiments demonstrate that our DGTR outperforms state-of-the-art video-based methods in reconstruction accuracy and maintains competitive motion smoothness. Moreover, DGTR utilizes fewer parameters and FLOPs, which validate the effectiveness and efficiency of the proposed DGTR. Code is publicly available at \href{https://github.com/TangTao-PKU/DGTR}{\textcolor{myBlue}{https://github.com/TangTao-PKU/DGTR}}.
ARTS: Semi-Analytical Regressor using Disentangled Skeletal Representations for Human Mesh Recovery from Videos
Oct 21, 2024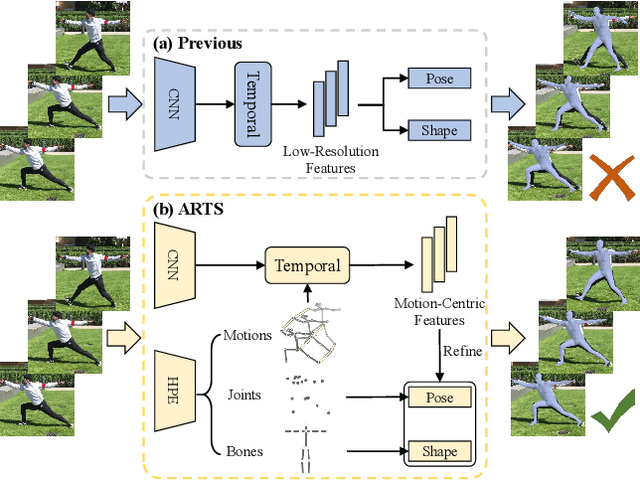
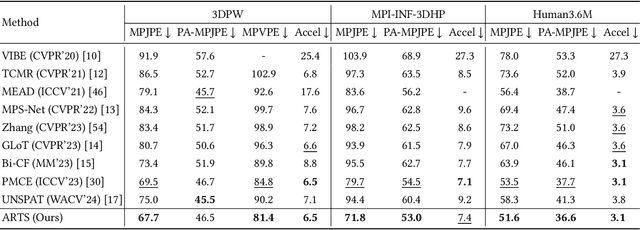
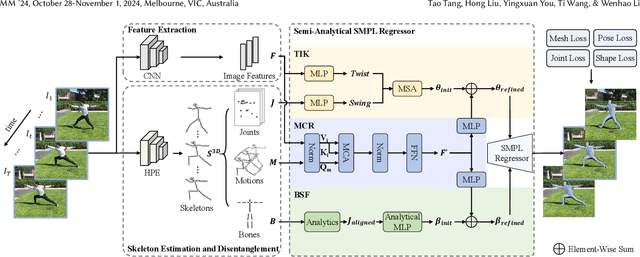

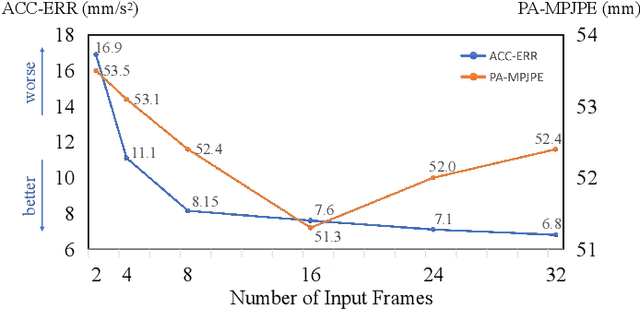
Although existing video-based 3D human mesh recovery methods have made significant progress, simultaneously estimating human pose and shape from low-resolution image features limits their performance. These image features lack sufficient spatial information about the human body and contain various noises (e.g., background, lighting, and clothing), which often results in inaccurate pose and inconsistent motion. Inspired by the rapid advance in human pose estimation, we discover that compared to image features, skeletons inherently contain accurate human pose and motion. Therefore, we propose a novel semiAnalytical Regressor using disenTangled Skeletal representations for human mesh recovery from videos, called ARTS. Specifically, a skeleton estimation and disentanglement module is proposed to estimate the 3D skeletons from a video and decouple them into disentangled skeletal representations (i.e., joint position, bone length, and human motion). Then, to fully utilize these representations, we introduce a semi-analytical regressor to estimate the parameters of the human mesh model. The regressor consists of three modules: Temporal Inverse Kinematics (TIK), Bone-guided Shape Fitting (BSF), and Motion-Centric Refinement (MCR). TIK utilizes joint position to estimate initial pose parameters and BSF leverages bone length to regress bone-aligned shape parameters. Finally, MCR combines human motion representation with image features to refine the initial human model parameters. Extensive experiments demonstrate that our ARTS surpasses existing state-of-the-art video-based methods in both per-frame accuracy and temporal consistency on popular benchmarks: 3DPW, MPI-INF-3DHP, and Human3.6M. Code is available at https://github.com/TangTao-PKU/ARTS.
TAMBRIDGE: Bridging Frame-Centered Tracking and 3D Gaussian Splatting for Enhanced SLAM
May 30, 2024



The limited robustness of 3D Gaussian Splatting (3DGS) to motion blur and camera noise, along with its poor real-time performance, restricts its application in robotic SLAM tasks. Upon analysis, the primary causes of these issues are the density of views with motion blur and the cumulative errors in dense pose estimation from calculating losses based on noisy original images and rendering results, which increase the difficulty of 3DGS rendering convergence. Thus, a cutting-edge 3DGS-based SLAM system is introduced, leveraging the efficiency and flexibility of 3DGS to achieve real-time performance while remaining robust against sensor noise, motion blur, and the challenges posed by long-session SLAM. Central to this approach is the Fusion Bridge module, which seamlessly integrates tracking-centered ORB Visual Odometry with mapping-centered online 3DGS. Precise pose initialization is enabled by this module through joint optimization of re-projection and rendering loss, as well as strategic view selection, enhancing rendering convergence in large-scale scenes. Extensive experiments demonstrate state-of-the-art rendering quality and localization accuracy, positioning this system as a promising solution for real-world robotics applications that require stable, near-real-time performance. Our project is available at https://ZeldaFromHeaven.github.io/TAMBRIDGE/
SGRU: A High-Performance Structured Gated Recurrent Unit for Traffic Flow Prediction
Apr 18, 2024



Traffic flow prediction is an essential task in constructing smart cities and is a typical Multivariate Time Series (MTS) Problem. Recent research has abandoned Gated Recurrent Units (GRU) and utilized dilated convolutions or temporal slicing for feature extraction, and they have the following drawbacks: (1) Dilated convolutions fail to capture the features of adjacent time steps, resulting in the loss of crucial transitional data. (2) The connections within the same temporal slice are strong, while the connections between different temporal slices are too loose. In light of these limitations, we emphasize the importance of analyzing a complete time series repeatedly and the crucial role of GRU in MTS. Therefore, we propose SGRU: Structured Gated Recurrent Units, which involve structured GRU layers and non-linear units, along with multiple layers of time embedding to enhance the model's fitting performance. We evaluate our approach on four publicly available California traffic datasets: PeMS03, PeMS04, PeMS07, and PeMS08 for regression prediction. Experimental results demonstrate that our model outperforms baseline models with average improvements of 11.7%, 18.6%, 18.5%, and 12.0% respectively.
Uncertainty-Aware Testing-Time Optimization for 3D Human Pose Estimation
Feb 04, 2024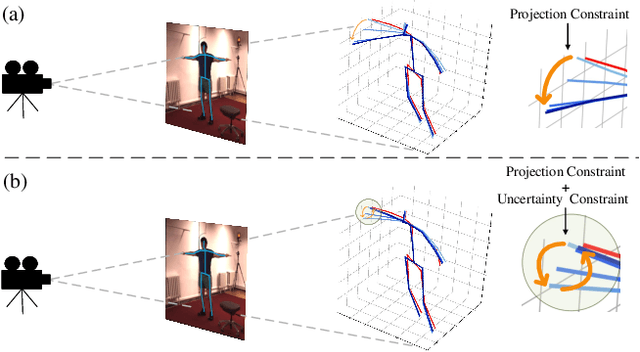

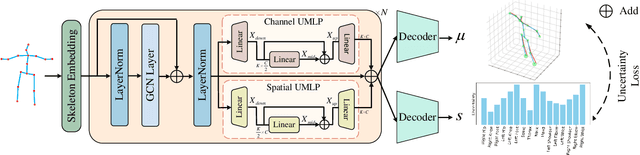

Although data-driven methods have achieved success in 3D human pose estimation, they often suffer from domain gaps and exhibit limited generalization. In contrast, optimization-based methods excel in fine-tuning for specific cases but are generally inferior to data-driven methods in overall performance. We observe that previous optimization-based methods commonly rely on projection constraint, which only ensures alignment in 2D space, potentially leading to the overfitting problem. To address this, we propose an Uncertainty-Aware testing-time Optimization (UAO) framework, which keeps the prior information of pre-trained model and alleviates the overfitting problem using the uncertainty of joints. Specifically, during the training phase, we design an effective 2D-to-3D network for estimating the corresponding 3D pose while quantifying the uncertainty of each 3D joint. For optimization during testing, the proposed optimization framework freezes the pre-trained model and optimizes only a latent state. Projection loss is then employed to ensure the generated poses are well aligned in 2D space for high-quality optimization. Furthermore, we utilize the uncertainty of each joint to determine how much each joint is allowed for optimization. The effectiveness and superiority of the proposed framework are validated through extensive experiments on two challenging datasets: Human3.6M and MPI-INF-3DHP. Notably, our approach outperforms the previous best result by a large margin of 4.5% on Human3.6M. Our source code will be open-sourced.
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
Aug 20, 2023Despite significant progress in single image-based 3D human mesh recovery, accurately and smoothly recovering 3D human motion from a video remains challenging. Existing video-based methods generally recover human mesh by estimating the complex pose and shape parameters from coupled image features, whose high complexity and low representation ability often result in inconsistent pose motion and limited shape patterns. To alleviate this issue, we introduce 3D pose as the intermediary and propose a Pose and Mesh Co-Evolution network (PMCE) that decouples this task into two parts: 1) video-based 3D human pose estimation and 2) mesh vertices regression from the estimated 3D pose and temporal image feature. Specifically, we propose a two-stream encoder that estimates mid-frame 3D pose and extracts a temporal image feature from the input image sequence. In addition, we design a co-evolution decoder that performs pose and mesh interactions with the image-guided Adaptive Layer Normalization (AdaLN) to make pose and mesh fit the human body shape. Extensive experiments demonstrate that the proposed PMCE outperforms previous state-of-the-art methods in terms of both per-frame accuracy and temporal consistency on three benchmark datasets: 3DPW, Human3.6M, and MPI-INF-3DHP. Our code is available at https://github.com/kasvii/PMCE.
Interweaved Graph and Attention Network for 3D Human Pose Estimation
Apr 27, 2023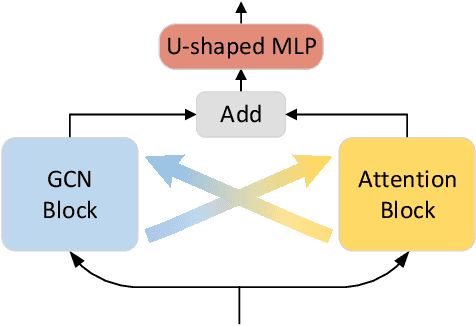
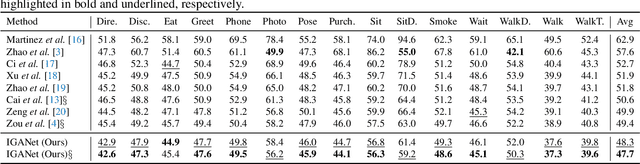
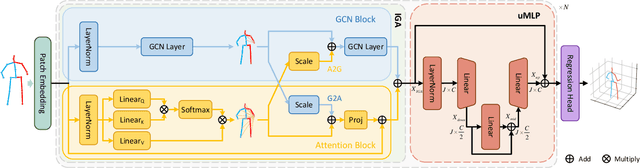

Despite substantial progress in 3D human pose estimation from a single-view image, prior works rarely explore global and local correlations, leading to insufficient learning of human skeleton representations. To address this issue, we propose a novel Interweaved Graph and Attention Network (IGANet) that allows bidirectional communications between graph convolutional networks (GCNs) and attentions. Specifically, we introduce an IGA module, where attentions are provided with local information from GCNs and GCNs are injected with global information from attentions. Additionally, we design a simple yet effective U-shaped multi-layer perceptron (uMLP), which can capture multi-granularity information for body joints. Extensive experiments on two popular benchmark datasets (i.e. Human3.6M and MPI-INF-3DHP) are conducted to evaluate our proposed method.The results show that IGANet achieves state-of-the-art performance on both datasets. Code is available at https://github.com/xiu-cs/IGANet.
GATOR: Graph-Aware Transformer with Motion-Disentangled Regression for Human Mesh Recovery from a 2D Pose
Mar 10, 2023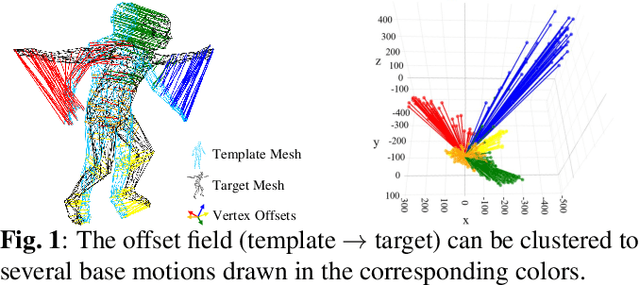
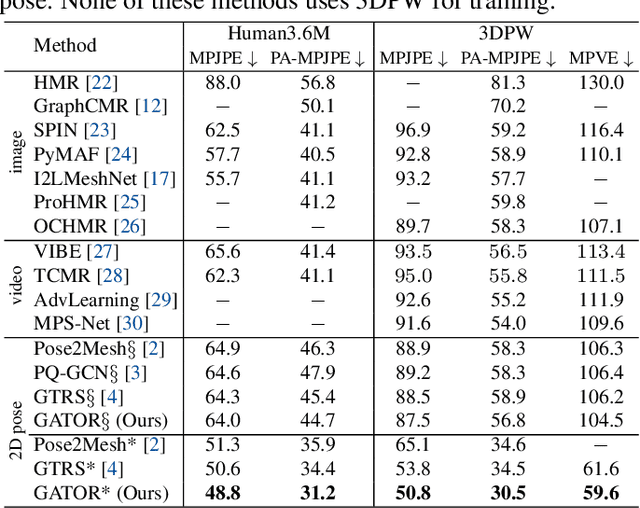
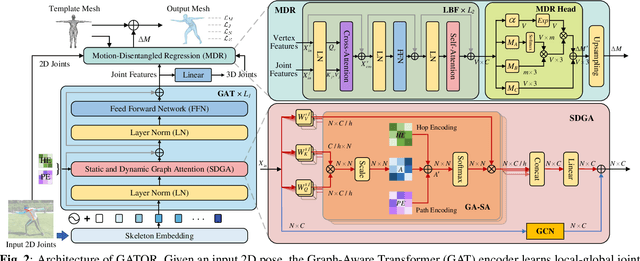

3D human mesh recovery from a 2D pose plays an important role in various applications. However, it is hard for existing methods to simultaneously capture the multiple relations during the evolution from skeleton to mesh, including joint-joint, joint-vertex and vertex-vertex relations, which often leads to implausible results. To address this issue, we propose a novel solution, called GATOR, that contains an encoder of Graph-Aware Transformer (GAT) and a decoder with Motion-Disentangled Regression (MDR) to explore these multiple relations. Specifically, GAT combines a GCN and a graph-aware self-attention in parallel to capture physical and hidden joint-joint relations. Furthermore, MDR models joint-vertex and vertex-vertex interactions to explore joint and vertex relations. Based on the clustering characteristics of vertex offset fields, MDR regresses the vertices by composing the predicted base motions. Extensive experiments show that GATOR achieves state-of-the-art performance on two challenging benchmarks.
Learning Paired-associate Images with An Unsupervised Deep Learning Architecture
Jan 10, 2014

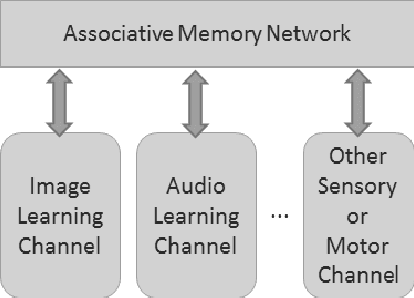
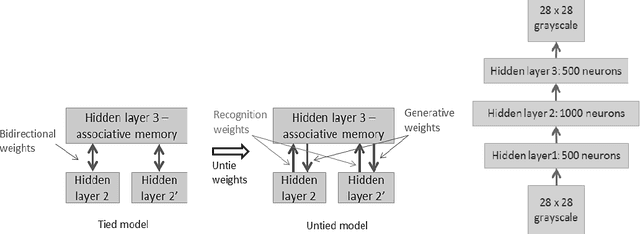
This paper presents an unsupervised multi-modal learning system that learns associative representation from two input modalities, or channels, such that input on one channel will correctly generate the associated response at the other and vice versa. In this way, the system develops a kind of supervised classification model meant to simulate aspects of human associative memory. The system uses a deep learning architecture (DLA) composed of two input/output channels formed from stacked Restricted Boltzmann Machines (RBM) and an associative memory network that combines the two channels. The DLA is trained on pairs of MNIST handwritten digit images to develop hierarchical features and associative representations that are able to reconstruct one image given its paired-associate. Experiments show that the multi-modal learning system generates models that are as accurate as back-propagation networks but with the advantage of a bi-directional network and unsupervised learning from either paired or non-paired training examples.