 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Roles of Symbols in Neural-based AI: They are Not What You Think!
Apr 26, 2023



We propose that symbols are first and foremost external communication tools used between intelligent agents that allow knowledge to be transferred in a more efficient and effective manner than having to experience the world directly. But, they are also used internally within an agent through a form of self-communication to help formulate, describe and justify subsymbolic patterns of neural activity that truly implement thinking. Symbols, and our languages that make use of them, not only allow us to explain our thinking to others and ourselves, but also provide beneficial constraints (inductive bias) on learning about the world. In this paper we present relevant insights from neuroscience and cognitive science, about how the human brain represents symbols and the concepts they refer to, and how today's artificial neural networks can do the same. We then present a novel neuro-symbolic hypothesis and a plausible architecture for intelligent agents that combines subsymbolic representations for symbols and concepts for learning and reasoning. Our hypothesis and associated architecture imply that symbols will remain critical to the future of intelligent systems NOT because they are the fundamental building blocks of thought, but because they are characterizations of subsymbolic processes that constitute thought.
Forecasting COVID-19 Case Counts Based on 2020 Ontario Data
Mar 18, 2023



Objective: To develop machine learning models that can predict the number of COVID-19 cases per day given the last 14 days of environmental and mobility data. Approach: COVID-19 data from four counties around Toronto, Ontario, were used. Data were prepared into daily records containing the number of new COVID case counts, patient demographic data, outdoor weather variables, indoor environment factors, and human movement based on cell mobility and public health restrictions. This data was analyzed to determine the most important variables and their interactions. Predictive models were developed using CNN and LSTM deep neural network approaches. A 5-fold chronological cross-validation approach used these methods to develop predictive models using data from Mar 1 to Oct 14 2020, and test them on data covering Oct 15 to Dec 24 2020. Results: The best LSTM models forecasted tomorrow's daily COVID case counts with 90.7% accuracy, and the 7-day rolling average COVID case counts with 98.1% accuracy using independent test data. The best models to forecast the next 7 days of daily COVID case counts did so with 79.4% accuracy over all days. Models forecasting the 7-day rolling average case counts had a mean accuracy of 83.6% on the same test set. Conclusions: Our findings point to the importance of indoor humidity for the transmission of a virus such as COVID-19. During the coldest portions of the year, when humans spend greater amounts of time indoors or in vehicles, air quality drops within buildings, most significantly indoor relative humidity levels. Moderate to high indoor temperatures coupled with low IRH (below 20%) create conditions where viral transmission is more likely because water vapour ejected from an infected person's mouth can remain longer in the air because of evaporation and dry skin conditions, particularly in a recipient's airway, promotes transmission.
Estimating Grape Yield on the Vine from Multiple Images
Apr 08, 2020
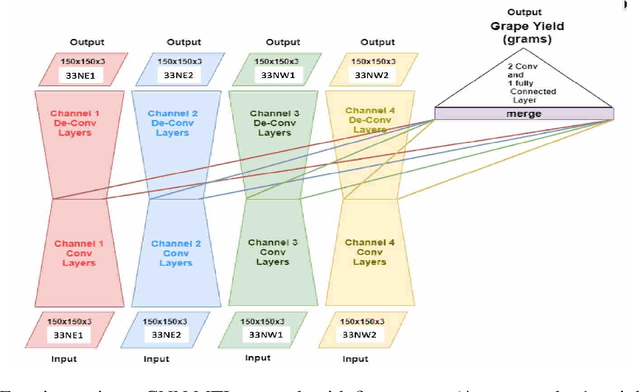
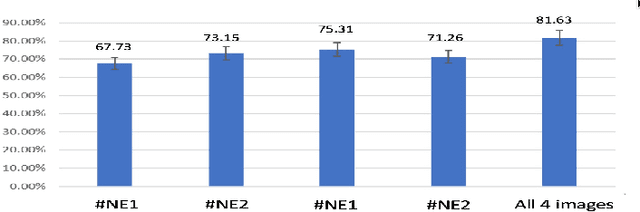

Estimating grape yield prior to harvest is important to commercial vineyard production as it informs many vineyard and winery decisions. Currently, the process of yield estimation is time consuming and varies in its accuracy from 75-90\% depending on the experience of the viticulturist. This paper proposes a multiple task learning (MTL) convolutional neural network (CNN) approach that uses images captured by inexpensive smart phones secured in a simple tripod arrangement. The CNN models use MTL transfer from autoencoders to achieve 85\% accuracy from image data captured 6 days prior to harvest.
AutoML @ NeurIPS 2018 challenge: Design and Results
Mar 14, 2019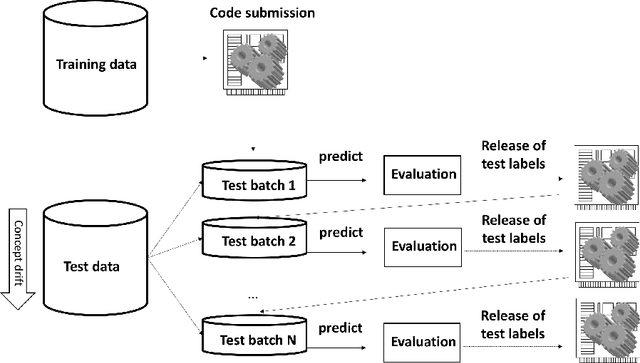
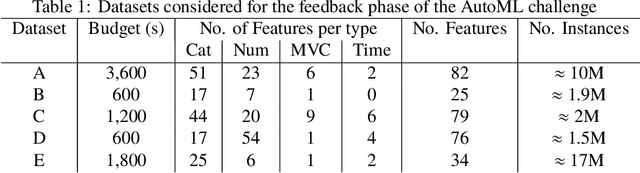

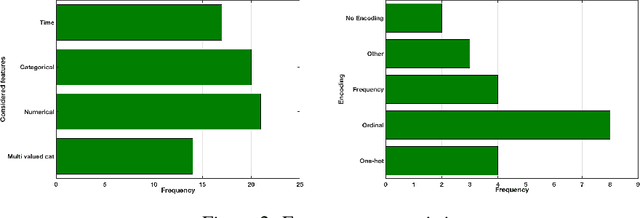
We organized a competition on Autonomous Lifelong Machine Learning with Drift that was part of the competition program of NeurIPS 2018. This data driven competition asked participants to develop computer programs capable of solving supervised learning problems where the i.i.d. assumption did not hold. Large data sets were arranged in a lifelong learning and evaluation scenario and CodaLab was used as the challenge platform. The challenge attracted more than 300 participants in its two month duration. This chapter describes the design of the challenge and summarizes its main results.
TrajectoryNet: An Embedded GPS Trajectory Representation for Point-based Classification Using Recurrent Neural Networks
Aug 30, 2017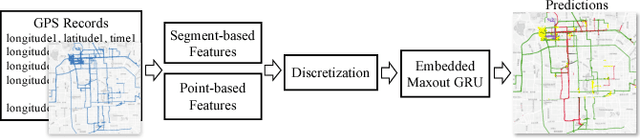


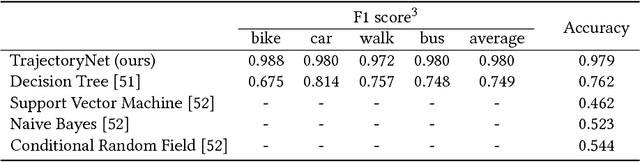
Understanding and discovering knowledge from GPS (Global Positioning System) traces of human activities is an essential topic in mobility-based urban computing. We propose TrajectoryNet-a neural network architecture for point-based trajectory classification to infer real world human transportation modes from GPS traces. To overcome the challenge of capturing the underlying latent factors in the low-dimensional and heterogeneous feature space imposed by GPS data, we develop a novel representation that embeds the original feature space into another space that can be understood as a form of basis expansion. We also enrich the feature space via segment-based information and use Maxout activations to improve the predictive power of Recurrent Neural Networks (RNNs). We achieve over 98% classification accuracy when detecting four types of transportation modes, outperforming existing models without additional sensory data or location-based prior knowledge.
Learning Paired-associate Images with An Unsupervised Deep Learning Architecture
Jan 10, 2014

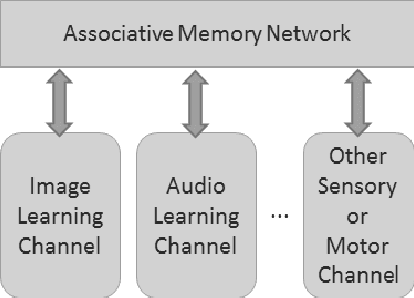
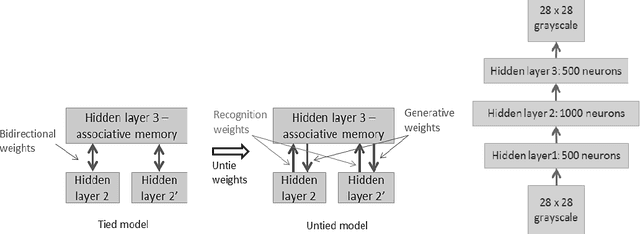
This paper presents an unsupervised multi-modal learning system that learns associative representation from two input modalities, or channels, such that input on one channel will correctly generate the associated response at the other and vice versa. In this way, the system develops a kind of supervised classification model meant to simulate aspects of human associative memory. The system uses a deep learning architecture (DLA) composed of two input/output channels formed from stacked Restricted Boltzmann Machines (RBM) and an associative memory network that combines the two channels. The DLA is trained on pairs of MNIST handwritten digit images to develop hierarchical features and associative representations that are able to reconstruct one image given its paired-associate. Experiments show that the multi-modal learning system generates models that are as accurate as back-propagation networks but with the advantage of a bi-directional network and unsupervised learning from either paired or non-paired training examples.