 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoML @ NeurIPS 2018 challenge: Design and Results
Mar 14, 2019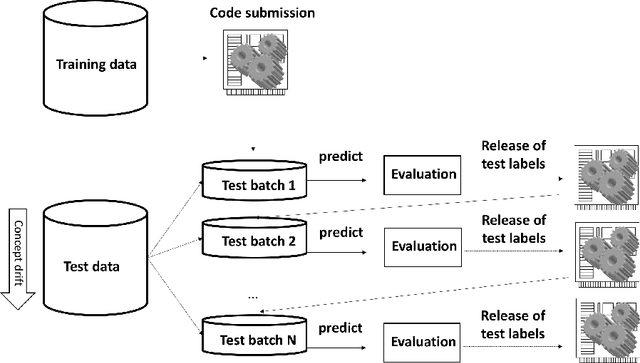
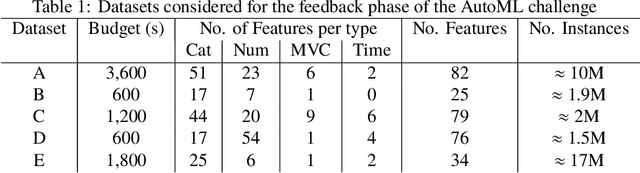

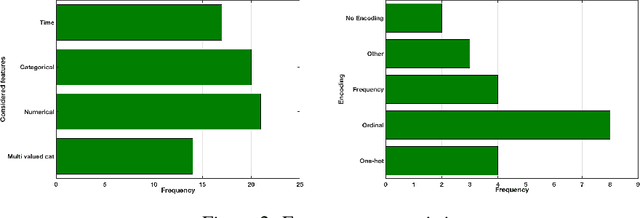
We organized a competition on Autonomous Lifelong Machine Learning with Drift that was part of the competition program of NeurIPS 2018. This data driven competition asked participants to develop computer programs capable of solving supervised learning problems where the i.i.d. assumption did not hold. Large data sets were arranged in a lifelong learning and evaluation scenario and CodaLab was used as the challenge platform. The challenge attracted more than 300 participants in its two month duration. This chapter describes the design of the challenge and summarizes its main results.
Explaining First Impressions: Modeling, Recognizing, and Explaining Apparent Personality from Videos
Oct 15, 2018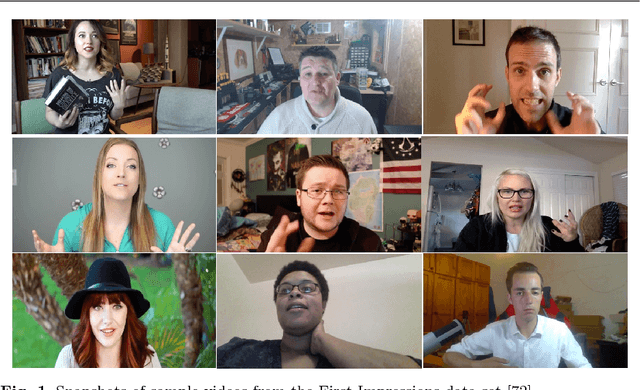
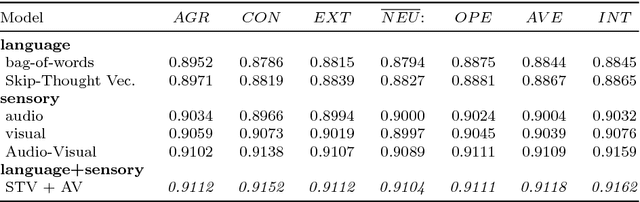
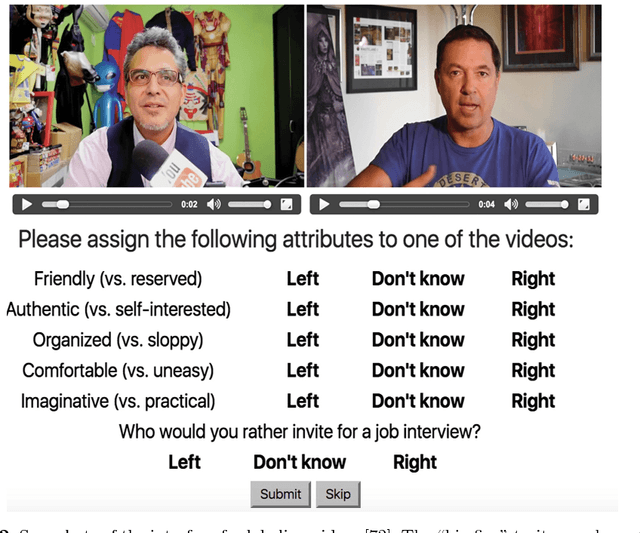
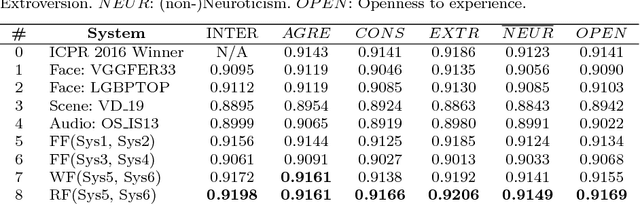
Explainability and interpretability are two critical aspects of decision support systems. Within computer vision, they are critical in certain tasks related to human behavior analysis such as in health care applications. Despite their importance, it is only recently that researchers are starting to explore these aspects. This paper provides an introduction to explainability and interpretability in the context of computer vision with an emphasis on looking at people tasks. Specifically, we review and study those mechanisms in the context of first impressions analysis. To the best of our knowledge, this is the first effort in this direction. Additionally, we describe a challenge we organized on explainability in first impressions analysis from video. We analyze in detail the newly introduced data set, the evaluation protocol, and summarize the results of the challenge. Finally, derived from our study, we outline research opportunities that we foresee will be decisive in the near future for the development of the explainable computer vision field.
From Submit to Submitted via Submission: On Lexical Rules in Large-Scale Lexicon Acquisition
Jul 08, 1996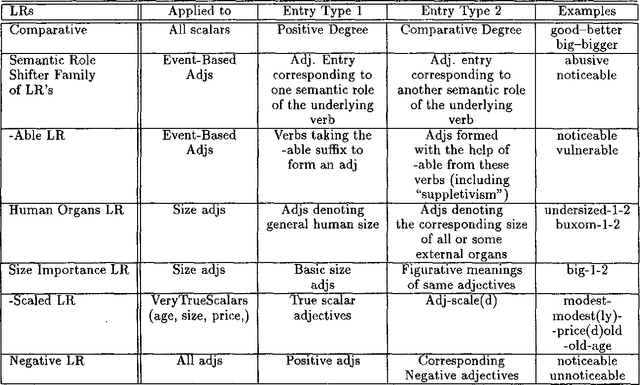
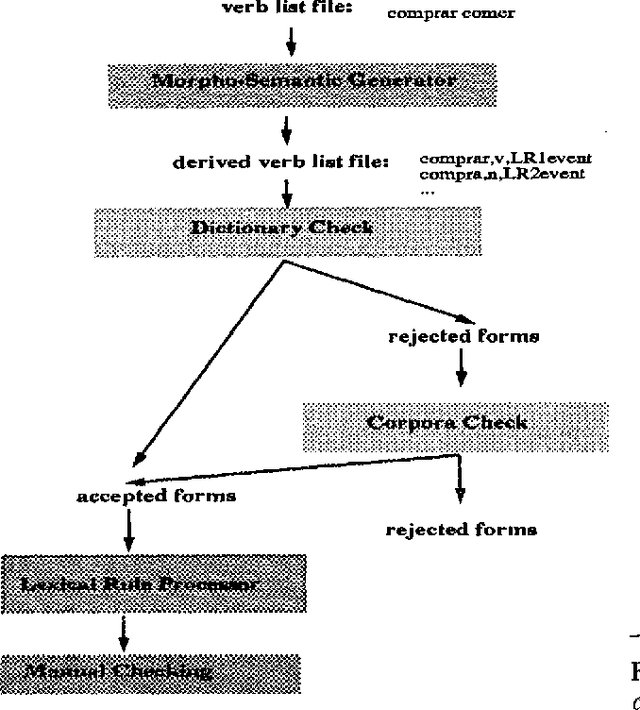

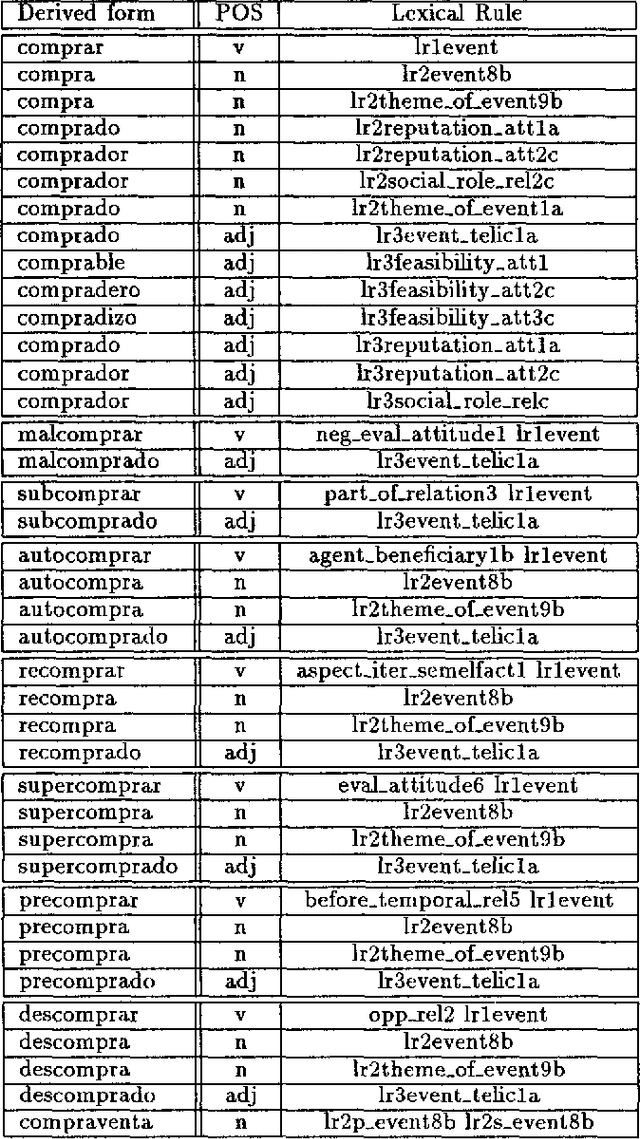
This paper deals with the discovery, representation, and use of lexical rules (LRs) during large-scale semi-automatic computational lexicon acquisition. The analysis is based on a set of LRs implemented and tested on the basis of Spanish and English business- and finance-related corpora. We show that, though the use of LRs is justified, they do not come cost-free. Semi-automatic output checking is required, even with blocking and preemtion procedures built in. Nevertheless, large-scope LRs are justified because they facilitate the unavoidable process of large-scale semi-automatic lexical acquisition. We also argue that the place of LRs in the computational process is a complex issue.