Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Submit to Submitted via Submission: On Lexical Rules in Large-Scale Lexicon Acquisition
Jul 08, 1996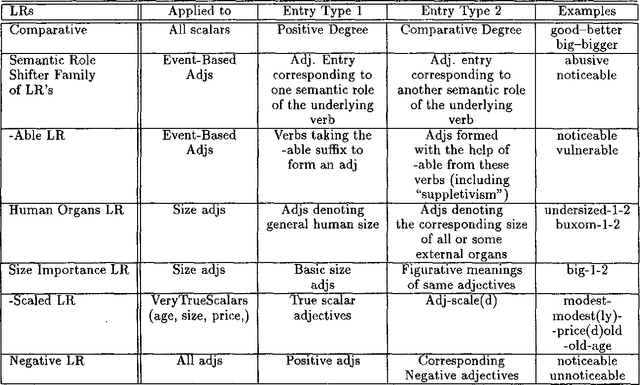
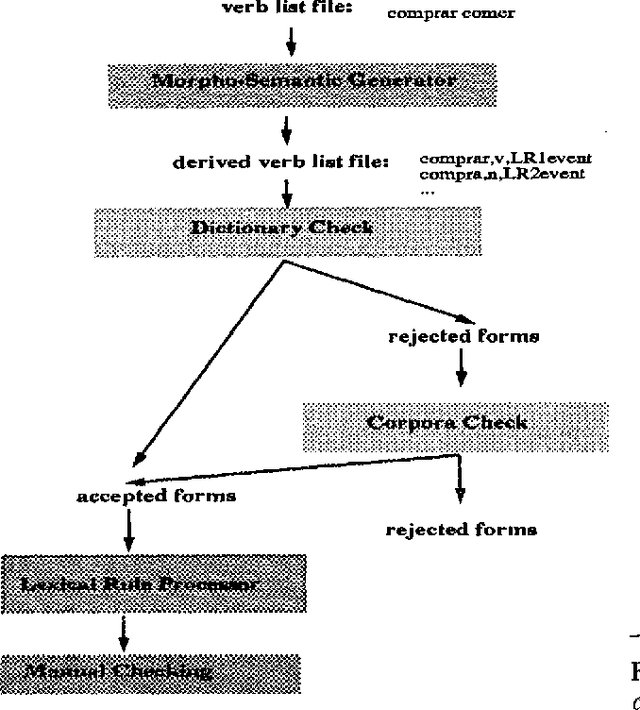

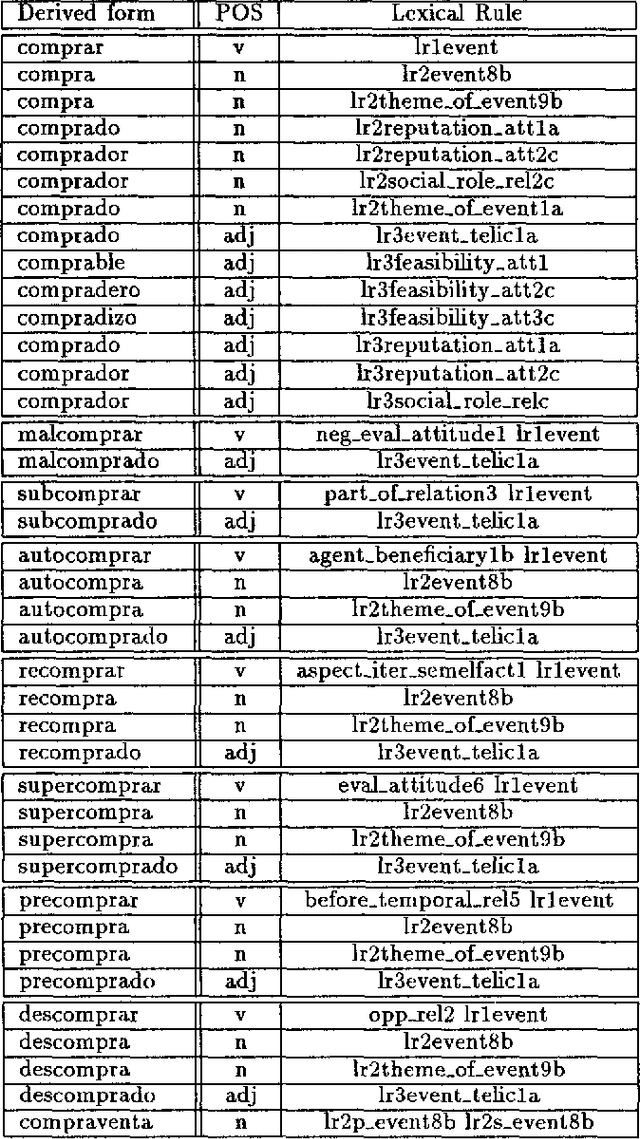
This paper deals with the discovery, representation, and use of lexical rules (LRs) during large-scale semi-automatic computational lexicon acquisition. The analysis is based on a set of LRs implemented and tested on the basis of Spanish and English business- and finance-related corpora. We show that, though the use of LRs is justified, they do not come cost-free. Semi-automatic output checking is required, even with blocking and preemtion procedures built in. Nevertheless, large-scope LRs are justified because they facilitate the unavoidable process of large-scale semi-automatic lexical acquisition. We also argue that the place of LRs in the computational process is a complex issue.
* Compressed and encoded postscript file
Via