 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphMLP: A Graph MLP-Like Architecture for 3D Human Pose Estimation
Paper and Code
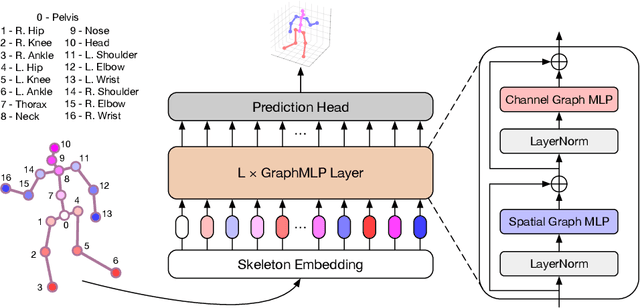
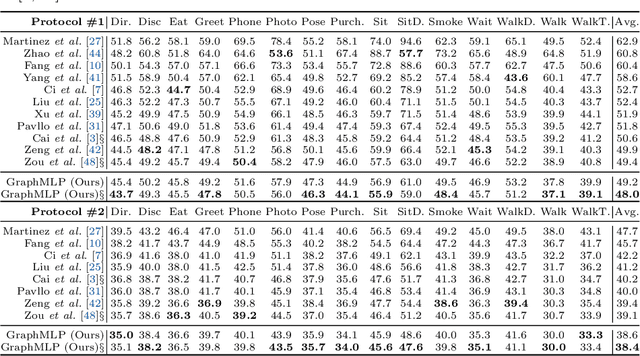
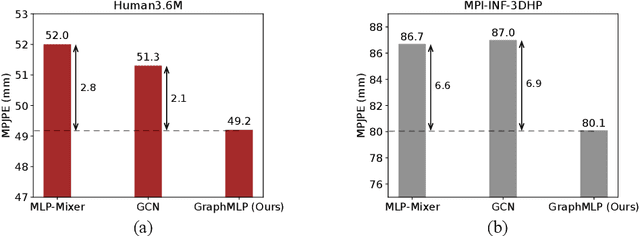
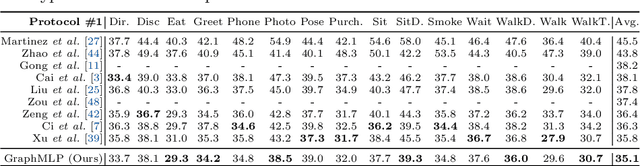
Modern multi-layer perceptron (MLP) models have shown competitive results in learning visual representations without self-attention. However, existing MLP models are not good at capturing local details and lack prior knowledge of human configurations, which limits their modeling power for skeletal representation learning. To address these issues, we propose a simple yet effective graph-reinforced MLP-Like architecture, named GraphMLP, that combines MLPs and graph convolutional networks (GCNs) in a global-local-graphical unified architecture for 3D human pose estimation. GraphMLP incorporates the graph structure of human bodies into an MLP model to meet the domain-specific demand while also allowing for both local and global spatial interactions. Extensive experiments show that the proposed GraphMLP achieves state-of-the-art performance on two datasets, i.e., Human3.6M and MPI-INF-3DHP. Our source code and pretrained models will be publicly available.