 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Paper and Code
Jun 05, 2024
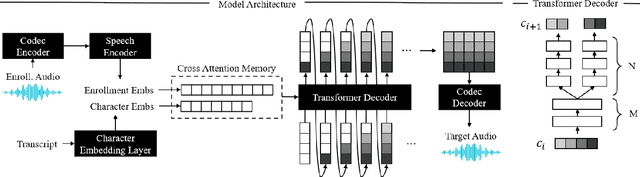
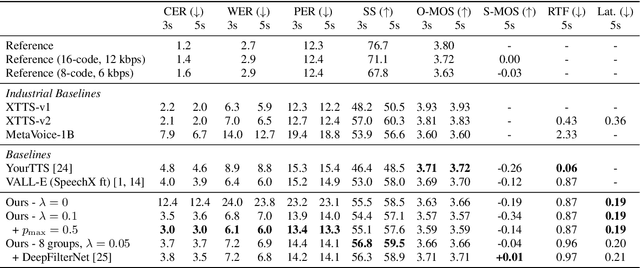
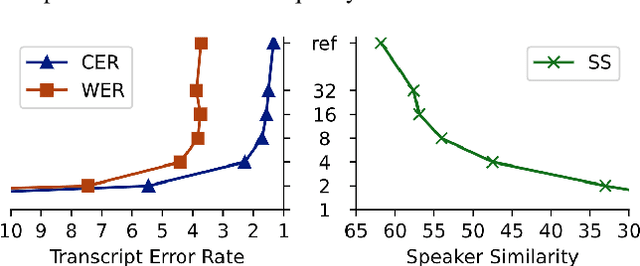
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.