Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterventional Assays for the Latent Space of Autoencoders
Paper and Code


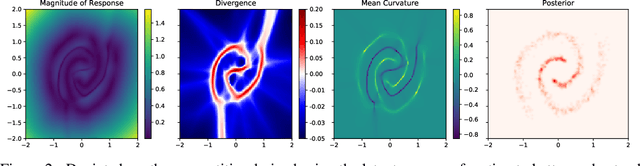

The encoders and decoders of autoencoders effectively project the input onto learned manifolds in the latent space and data space respectively. We propose a framework, called latent responses, for probing the learned data manifold using interventions in the latent space. Using this framework, we investigate "holes" in the representation to quantitatively ascertain to what extent the latent space of a trained VAE is consistent with the chosen prior. Furthermore, we use the identified structure to improve interpolation between latent vectors. We evaluate how our analyses improve the quality of the generated samples using the VAE on a variety of benchmark datasets.
* Under review for NeurIPS 2021
View paper on