 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRO-N3WS: Enhancing Generalization in Low-Resource ASR with Diverse Romanian Speech Benchmarks
Mar 02, 2026We introduce RO-N3WS, a benchmark Romanian speech dataset designed to improve generalization in automatic speech recognition (ASR), particularly in low-resource and out-of-distribution (OOD) conditions. RO-N3WS comprises over 126 hours of transcribed audio collected from broadcast news, literary audiobooks, film dialogue, children's stories, and conversational podcast speech. This diversity enables robust training and fine-tuning across stylistically distinct domains. We evaluate several state-of-the-art ASR systems (Whisper, Wav2Vec 2.0) in both zero-shot and fine-tuned settings, and conduct controlled comparisons using synthetic data generated with expressive TTS models. Our results show that even limited fine-tuning on real speech from RO-N3WS yields substantial WER improvements over zero-shot baselines. We will release all models, scripts, and data splits to support reproducible research in multilingual ASR, domain adaptation, and lightweight deployment.
Multi-Level Feature Distillation of Joint Teachers Trained on Distinct Image Datasets
Oct 29, 2024We propose a novel teacher-student framework to distill knowledge from multiple teachers trained on distinct datasets. Each teacher is first trained from scratch on its own dataset. Then, the teachers are combined into a joint architecture, which fuses the features of all teachers at multiple representation levels. The joint teacher architecture is fine-tuned on samples from all datasets, thus gathering useful generic information from all data samples. Finally, we employ a multi-level feature distillation procedure to transfer the knowledge to a student model for each of the considered datasets. We conduct image classification experiments on seven benchmarks, and action recognition experiments on three benchmarks. To illustrate the power of our feature distillation procedure, the student architectures are chosen to be identical to those of the individual teachers. To demonstrate the flexibility of our approach, we combine teachers with distinct architectures. We show that our novel Multi-Level Feature Distillation (MLFD) can significantly surpass equivalent architectures that are either trained on individual datasets, or jointly trained on all datasets at once. Furthermore, we confirm that each step of the proposed training procedure is well motivated by a comprehensive ablation study. We publicly release our code at https://github.com/AdrianIordache/MLFD.
Learning Diverse Features in Vision Transformers for Improved Generalization
Aug 30, 2023



Deep learning models often rely only on a small set of features even when there is a rich set of predictive signals in the training data. This makes models brittle and sensitive to distribution shifts. In this work, we first examine vision transformers (ViTs) and find that they tend to extract robust and spurious features with distinct attention heads. As a result of this modularity, their performance under distribution shifts can be significantly improved at test time by pruning heads corresponding to spurious features, which we demonstrate using an "oracle selection" on validation data. Second, we propose a method to further enhance the diversity and complementarity of the learned features by encouraging orthogonality of the attention heads' input gradients. We observe improved out-of-distribution performance on diagnostic benchmarks (MNIST-CIFAR, Waterbirds) as a consequence of the enhanced diversity of features and the pruning of undesirable heads.
JEDI: Joint Expert Distillation in a Semi-Supervised Multi-Dataset Student-Teacher Scenario for Video Action Recognition
Aug 09, 2023We propose JEDI, a multi-dataset semi-supervised learning method, which efficiently combines knowledge from multiple experts, learned on different datasets, to train and improve the performance of individual, per dataset, student models. Our approach achieves this by addressing two important problems in current machine learning research: generalization across datasets and limitations of supervised training due to scarcity of labeled data. We start with an arbitrary number of experts, pretrained on their own specific dataset, which form the initial set of student models. The teachers are immediately derived by concatenating the feature representations from the penultimate layers of the students. We then train all models in a student-teacher semi-supervised learning scenario until convergence. In our efficient approach, student-teacher training is carried out jointly and end-to-end, showing that both students and teachers improve their generalization capacity during training. We validate our approach on four video action recognition datasets. By simultaneously considering all datasets within a unified semi-supervised setting, we demonstrate significant improvements over the initial experts.
A realistic approach to generate masked faces applied on two novel masked face recognition data sets
Sep 03, 2021
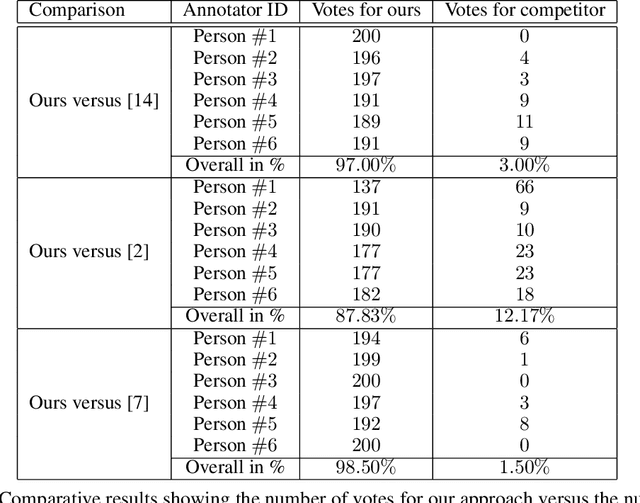

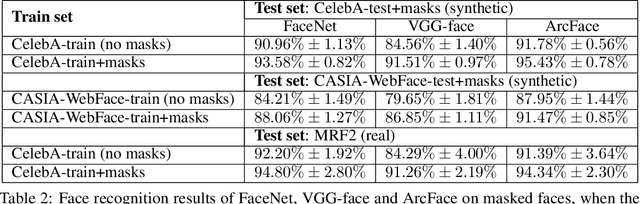
The COVID-19 pandemic raises the problem of adapting face recognition systems to the new reality, where people may wear surgical masks to cover their noses and mouths. Traditional data sets (e.g., CelebA, CASIA-WebFace) used for training these systems were released before the pandemic, so they now seem unsuited due to the lack of examples of people wearing masks. We propose a method for enhancing data sets containing faces without masks by creating synthetic masks and overlaying them on faces in the original images. Our method relies on Spark AR Studio, a developer program made by Facebook that is used to create Instagram face filters. In our approach, we use 9 masks of different colors, shapes and fabrics. We employ our method to generate a number of 445,446 (90%) samples of masks for the CASIA-WebFace data set and 196,254 (96.8%) masks for the CelebA data set, releasing the mask images at https://github.com/securifai/masked_faces. We show that our method produces significantly more realistic training examples of masks overlaid on faces by asking volunteers to qualitatively compare it to other methods or data sets designed for the same task. We also demonstrate the usefulness of our method by evaluating state-of-the-art face recognition systems (FaceNet, VGG-face, ArcFace) trained on the enhanced data sets and showing that they outperform equivalent systems trained on the original data sets (containing faces without masks), when the test benchmark contains masked faces.
Detecting abnormal events in video using Narrowed Motion Clusters
Jun 15, 2018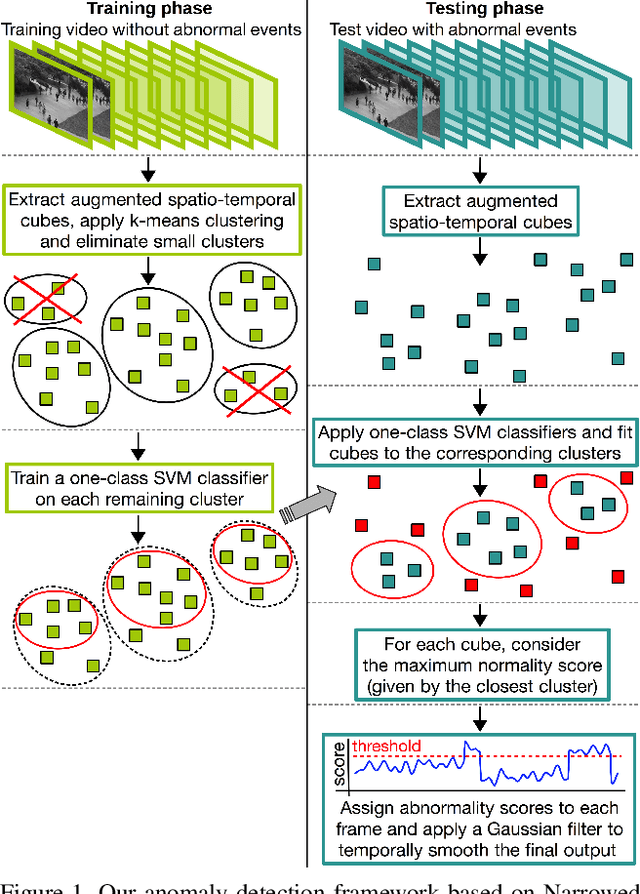
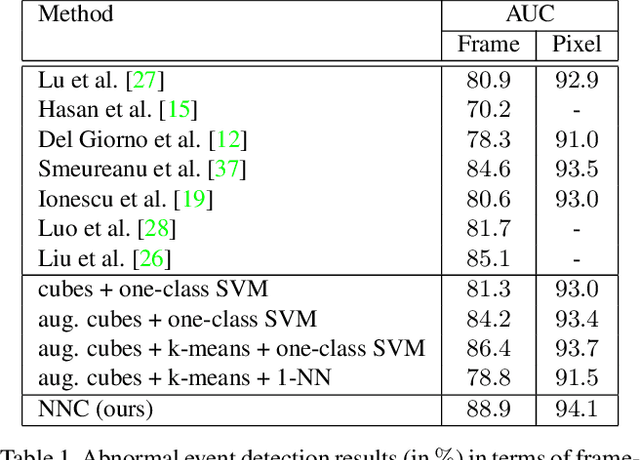
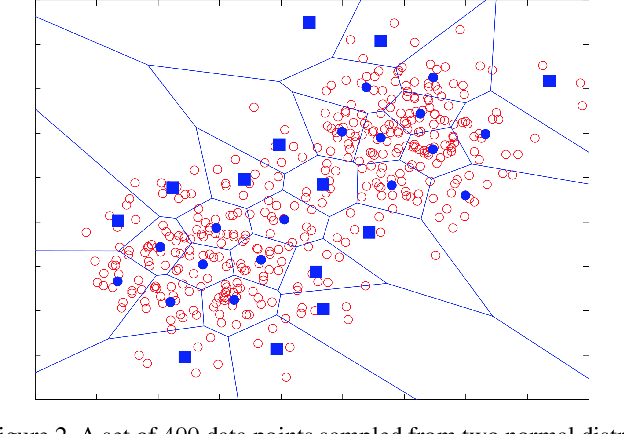
We formulate the abnormal event detection problem as an outlier detection task and we propose a two-stage algorithm based on k-means clustering and one-class Support Vector Machines (SVM) to eliminate outliers. After extracting motion features from the training video containing only normal events, we apply k-means clustering to find clusters representing different types of motion. In the first stage, we consider that clusters with fewer samples (with respect to a given threshold) contain only outliers and we eliminate these clusters altogether. In the second stage, we shrink the borders of the remaining clusters by training a one-class SVM model on each cluster. To detected abnormal events in the test video, we analyze each test sample and consider its maximum normality score provided by the trained one-class SVM models, based on the intuition that a test sample can belong to only one cluster of normal motion. If the test sample does not fit well in any narrowed cluster, than it is labeled as abnormal. We also combine our approach based on motion features with a recent approach based on deep appearance features extracted with pre-trained convolutional neural networks (CNN). We combine our two-stage algorithm with the deep framework using a late fusion strategy, keeping the pipelines of the two approaches independent. We compare our method with several state-of-the-art supervised and unsupervised methods on four benchmark data sets. The empirical results indicate that our abnormal event detection framework can achieve better results in most cases, while processing the test video in real-time at 32 frames per second on CPU.
Unmasking the abnormal events in video
Jul 25, 2017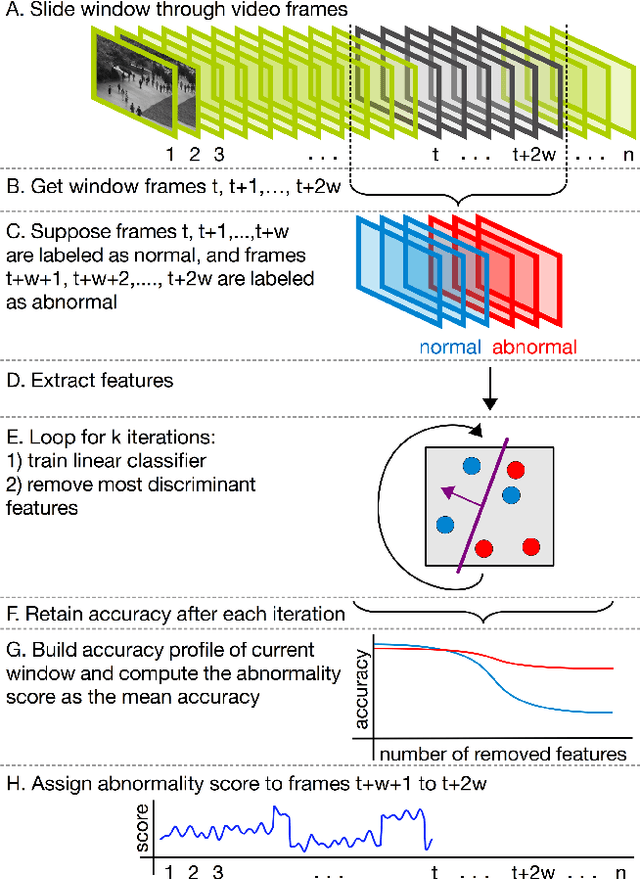
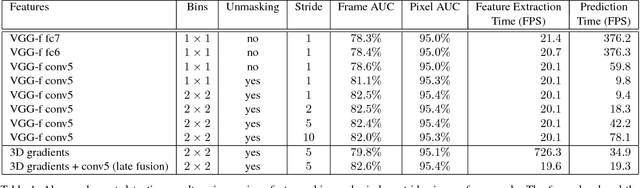
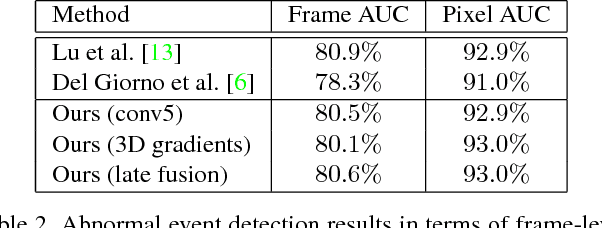
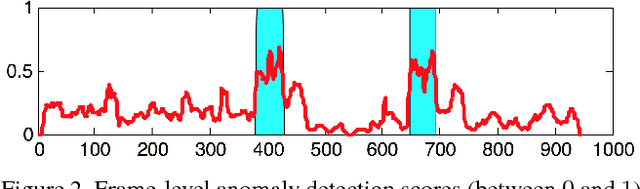
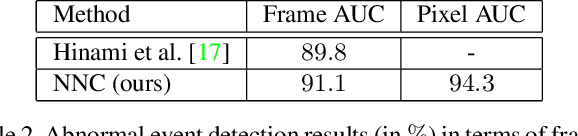
We propose a novel framework for abnormal event detection in video that requires no training sequences. Our framework is based on unmasking, a technique previously used for authorship verification in text documents, which we adapt to our task. We iteratively train a binary classifier to distinguish between two consecutive video sequences while removing at each step the most discriminant features. Higher training accuracy rates of the intermediately obtained classifiers represent abnormal events. To the best of our knowledge, this is the first work to apply unmasking for a computer vision task. We compare our method with several state-of-the-art supervised and unsupervised methods on four benchmark data sets. The empirical results indicate that our abnormal event detection framework can achieve state-of-the-art results, while running in real-time at 20 frames per second.
How hard can it be? Estimating the difficulty of visual search in an image
May 23, 2017
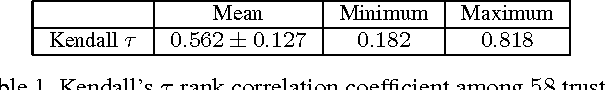
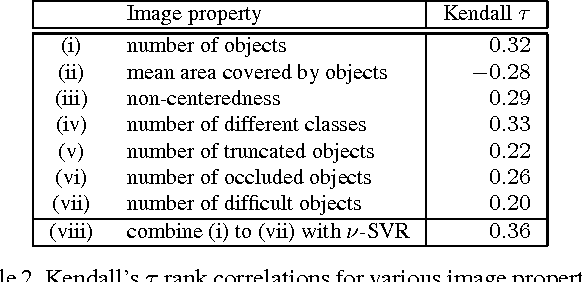
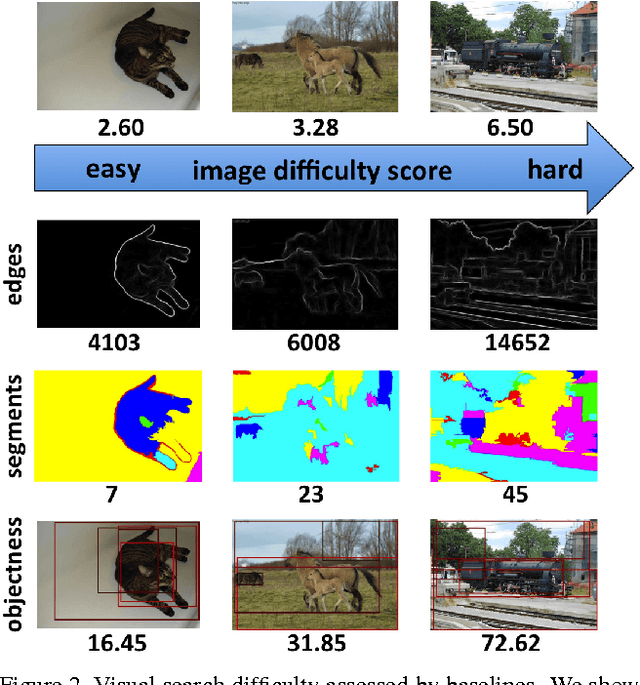
We address the problem of estimating image difficulty defined as the human response time for solving a visual search task. We collect human annotations of image difficulty for the PASCAL VOC 2012 data set through a crowd-sourcing platform. We then analyze what human interpretable image properties can have an impact on visual search difficulty, and how accurate are those properties for predicting difficulty. Next, we build a regression model based on deep features learned with state of the art convolutional neural networks and show better results for predicting the ground-truth visual search difficulty scores produced by human annotators. Our model is able to correctly rank about 75% image pairs according to their difficulty score. We also show that our difficulty predictor generalizes well to new classes not seen during training. Finally, we demonstrate that our predicted difficulty scores are useful for weakly supervised object localization (8% improvement) and semi-supervised object classification (1% improvement).
* Published at CVPR 2016