 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection
Nov 16, 2021
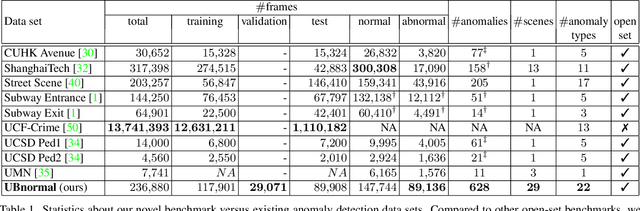
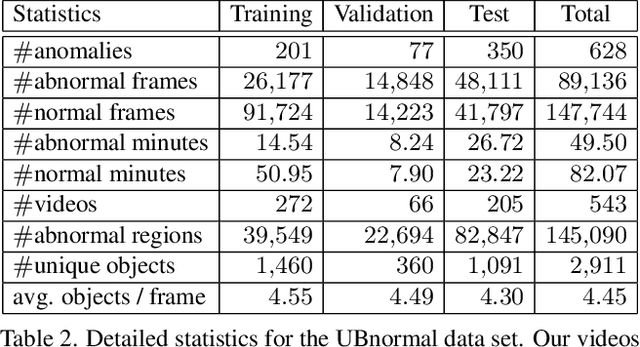

Detecting abnormal events in video is commonly framed as a one-class classification task, where training videos contain only normal events, while test videos encompass both normal and abnormal events. In this scenario, anomaly detection is an open-set problem. However, some studies assimilate anomaly detection to action recognition. This is a closed-set scenario that fails to test the capability of systems at detecting new anomaly types. To this end, we propose UBnormal, a new supervised open-set benchmark composed of multiple virtual scenes for video anomaly detection. Unlike existing data sets, we introduce abnormal events annotated at the pixel level at training time, for the first time enabling the use of fully-supervised learning methods for abnormal event detection. To preserve the typical open-set formulation, we make sure to include disjoint sets of anomaly types in our training and test collections of videos. To our knowledge, UBnormal is the first video anomaly detection benchmark to allow a fair head-to-head comparison between one-class open-set models and supervised closed-set models, as shown in our experiments. Moreover, we provide empirical evidence showing that UBnormal can enhance the performance of a state-of-the-art anomaly detection framework on two prominent data sets, Avenue and ShanghaiTech.
A realistic approach to generate masked faces applied on two novel masked face recognition data sets
Sep 03, 2021
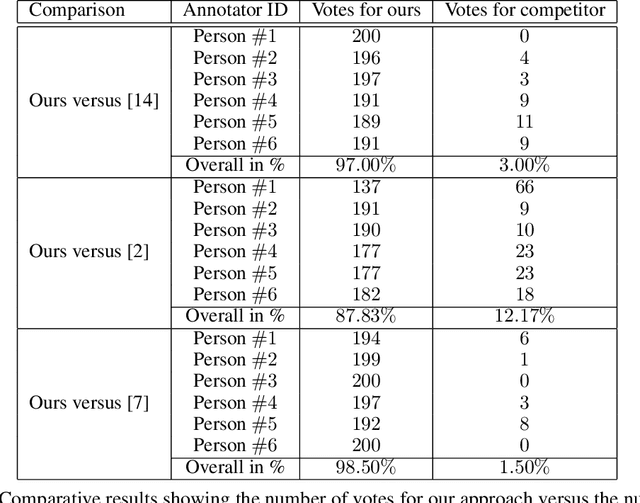

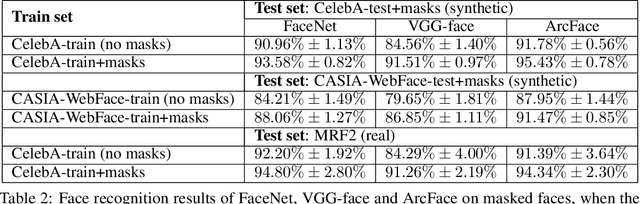
The COVID-19 pandemic raises the problem of adapting face recognition systems to the new reality, where people may wear surgical masks to cover their noses and mouths. Traditional data sets (e.g., CelebA, CASIA-WebFace) used for training these systems were released before the pandemic, so they now seem unsuited due to the lack of examples of people wearing masks. We propose a method for enhancing data sets containing faces without masks by creating synthetic masks and overlaying them on faces in the original images. Our method relies on Spark AR Studio, a developer program made by Facebook that is used to create Instagram face filters. In our approach, we use 9 masks of different colors, shapes and fabrics. We employ our method to generate a number of 445,446 (90%) samples of masks for the CASIA-WebFace data set and 196,254 (96.8%) masks for the CelebA data set, releasing the mask images at https://github.com/securifai/masked_faces. We show that our method produces significantly more realistic training examples of masks overlaid on faces by asking volunteers to qualitatively compare it to other methods or data sets designed for the same task. We also demonstrate the usefulness of our method by evaluating state-of-the-art face recognition systems (FaceNet, VGG-face, ArcFace) trained on the enhanced data sets and showing that they outperform equivalent systems trained on the original data sets (containing faces without masks), when the test benchmark contains masked faces.