 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis for Zero-Shot Multi-Label Classification on COVID-19 CT Scans and Uncurated Reports
Sep 06, 2023The pandemic resulted in vast repositories of unstructured data, including radiology reports, due to increased medical examinations. Previous research on automated diagnosis of COVID-19 primarily focuses on X-ray images, despite their lower precision compared to computed tomography (CT) scans. In this work, we leverage unstructured data from a hospital and harness the fine-grained details offered by CT scans to perform zero-shot multi-label classification based on contrastive visual language learning. In collaboration with human experts, we investigate the effectiveness of multiple zero-shot models that aid radiologists in detecting pulmonary embolisms and identifying intricate lung details like ground glass opacities and consolidations. Our empirical analysis provides an overview of the possible solutions to target such fine-grained tasks, so far overlooked in the medical multimodal pretraining literature. Our investigation promises future advancements in the medical image analysis community by addressing some challenges associated with unstructured data and fine-grained multi-label classification.
Self-Attention and Ingredient-Attention Based Model for Recipe Retrieval from Image Queries
Nov 05, 2019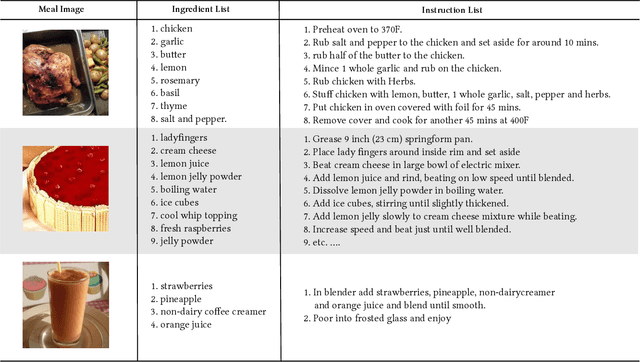
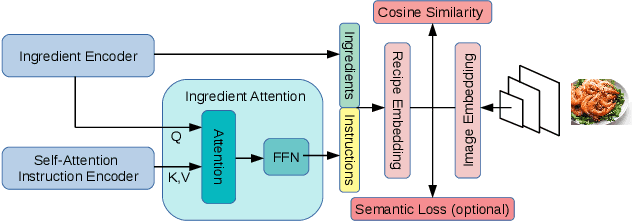
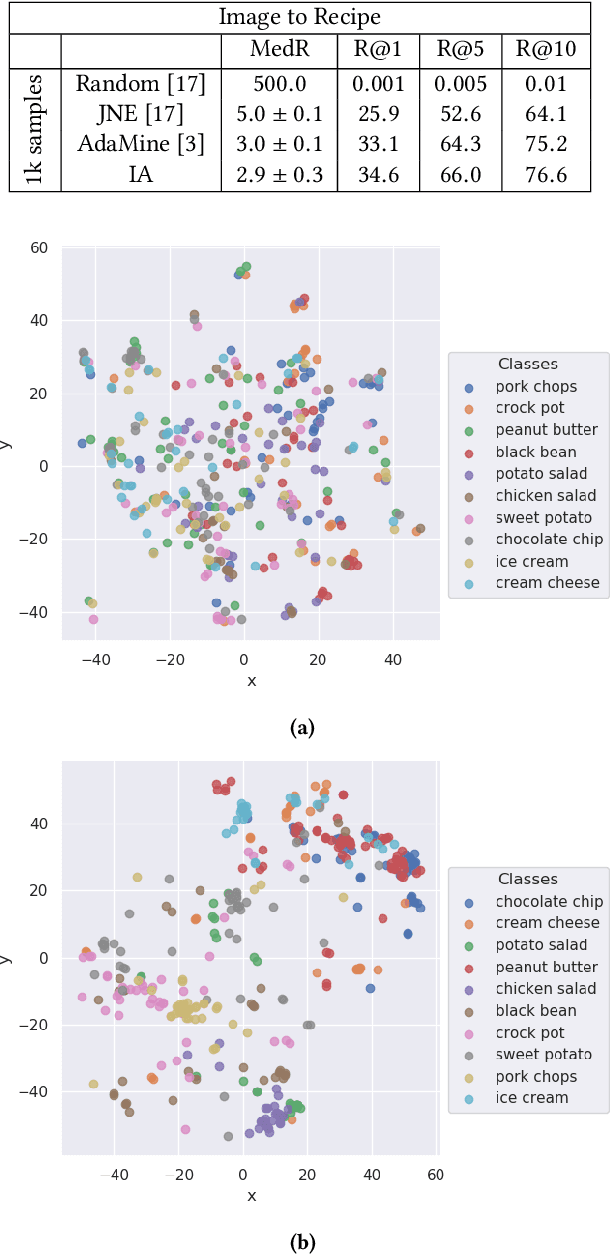

Direct computer vision based-nutrient content estimation is a demanding task, due to deformation and occlusions of ingredients, as well as high intra-class and low inter-class variability between meal classes. In order to tackle these issues, we propose a system for recipe retrieval from images. The recipe information can subsequently be used to estimate the nutrient content of the meal. In this study, we utilize the multi-modal Recipe1M dataset, which contains over 1 million recipes accompanied by over 13 million images. The proposed model can operate as a first step in an automatic pipeline for the estimation of nutrition content by supporting hints related to ingredient and instruction. Through self-attention, our model can directly process raw recipe text, making the upstream instruction sentence embedding process redundant and thus reducing training time, while providing desirable retrieval results. Furthermore, we propose the use of an ingredient attention mechanism, in order to gain insight into which instructions, parts of instructions or single instruction words are of importance for processing a single ingredient within a certain recipe. Attention-based recipe text encoding contributes to solving the issue of high intra-class/low inter-class variability by focusing on preparation steps specific to the meal. The experimental results demonstrate the potential of such a system for recipe retrieval from images. A comparison with respect to two baseline methods is also presented.