 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cone Effect and Modality Gap in Medical Vision-Language Embeddings
Mar 18, 2026Vision-Language Models (VLMs) exhibit a characteristic "cone effect" in which nonlinear encoders map embeddings into highly concentrated regions of the representation space, contributing to cross-modal separation known as the modality gap. While this phenomenon has been widely observed, its practical impact on supervised multimodal learning -particularly in medical domains- remains unclear. In this work, we introduce a lightweight post-hoc mechanism that keeps pretrained VLM encoders frozen while continuously controlling cross-modal separation through a single hyperparameter {λ}. This enables systematic analysis of how the modality gap affects downstream multimodal performance without expensive retraining. We evaluate generalist (CLIP, SigLIP) and medically specialized (BioMedCLIP, MedSigLIP) models across diverse medical and natural datasets in a supervised multimodal settings. Results consistently show that reducing excessive modality gap improves downstream performance, with medical datasets exhibiting stronger sensitivity to gap modulation; however, fully collapsing the gap is not always optimal, and intermediate, task-dependent separation yields the best results. These findings position the modality gap as a tunable property of multimodal representations rather than a quantity that should be universally minimized.
Information Maximization for Long-Tailed Semi-Supervised Domain Generalization
Mar 09, 2026Semi-supervised domain generalization (SSDG) has recently emerged as an appealing alternative to tackle domain generalization when labeled data is scarce but unlabeled samples across domains are abundant. In this work, we identify an important limitation that hampers the deployment of state-of-the-art methods on more challenging but practical scenarios. In particular, state-of-the-art SSDG severely suffers in the presence of long-tailed class distributions, an arguably common situation in real-world settings. To alleviate this limitation, we propose IMaX, a simple yet effective objective based on the well-known InfoMax principle adapted to the SSDG scenario, where the Mutual Information (MI) between the learned features and latent labels is maximized, constrained by the supervision from the labeled samples. Our formulation integrates an α-entropic objective, which mitigates the class-balance bias encoded in the standard marginal entropy term of the MI, thereby better handling arbitrary class distributions. IMaX can be seamlessly plugged into recent state-of-the-art SSDG, consistently enhancing their performance, as demonstrated empirically across two different image modalities.
Mask-HybridGNet: Graph-based segmentation with emergent anatomical correspondence from pixel-level supervision
Feb 24, 2026Graph-based medical image segmentation represents anatomical structures using boundary graphs, providing fixed-topology landmarks and inherent population-level correspondences. However, their clinical adoption has been hindered by a major requirement: training datasets with manually annotated landmarks that maintain point-to-point correspondences across patients rarely exist in practice. We introduce Mask-HybridGNet, a framework that trains graph-based models directly using standard pixel-wise masks, eliminating the need for manual landmark annotations. Our approach aligns variable-length ground truth boundaries with fixed-length landmark predictions by combining Chamfer distance supervision and edge-based regularization to ensure local smoothness and regular landmark distribution, further refined via differentiable rasterization. A significant emergent property of this framework is that predicted landmark positions become consistently associated with specific anatomical locations across patients without explicit correspondence supervision. This implicit atlas learning enables temporal tracking, cross-slice reconstruction, and morphological population analyses. Beyond direct segmentation, Mask-HybridGNet can extract correspondences from existing segmentation masks, allowing it to generate stable anatomical atlases from any high-quality pixel-based model. Experiments across chest radiography, cardiac ultrasound, cardiac MRI, and fetal imaging demonstrate that our model achieves competitive results against state-of-the-art pixel-based methods, while ensuring anatomical plausibility by enforcing boundary connectivity through a fixed graph adjacency matrix. This framework leverages the vast availability of standard segmentation masks to build structured models that maintain topological integrity and provide implicit correspondences.
OCTOPUS: Enhancing the Spatial-Awareness of Vision SSMs with Multi-Dimensional Scans and Traversal Selection
Jan 31, 2026State space models (SSMs) have recently emerged as an alternative to transformers due to their unique ability of modeling global relationships in text with linear complexity. However, their success in vision tasks has been limited due to their causal formulation, which is suitable for sequential text but detrimental in the spatial domain where causality breaks the inherent spatial relationships among pixels or patches. As a result, standard SSMs fail to capture local spatial coherence, often linking non-adjacent patches while ignoring neighboring ones that are visually correlated. To address these limitations, we introduce OCTOPUS , a novel architecture that preserves both global context and local spatial structure within images, while maintaining the linear complexity of SSMs. OCTOPUS performs discrete reoccurrence along eight principal orientations, going forward or backward in the horizontal, vertical, and diagonal directions, allowing effective information exchange across all spatially connected regions while maintaining independence among unrelated patches. This design enables multi-directional recurrence, capturing both global context and local spatial structure with SSM-level efficiency. In our classification and segmentation benchmarks, OCTOPUS demonstrates notable improvements in boundary preservation and region consistency, as evident from the segmentation results, while maintaining relatively better classification accuracy compared to existing V-SSM based models. These results suggest that OCTOPUS appears as a foundation method for multi-directional recurrence as a scalable and effective mechanism for building spatially aware and computationally efficient vision architectures.
Class Adaptive Conformal Training
Jan 14, 2026Deep neural networks have achieved remarkable success across a variety of tasks, yet they often suffer from unreliable probability estimates. As a result, they can be overconfident in their predictions. Conformal Prediction (CP) offers a principled framework for uncertainty quantification, yielding prediction sets with rigorous coverage guarantees. Existing conformal training methods optimize for overall set size, but shaping the prediction sets in a class-conditional manner is not straightforward and typically requires prior knowledge of the data distribution. In this work, we introduce Class Adaptive Conformal Training (CaCT), which formulates conformal training as an augmented Lagrangian optimization problem that adaptively learns to shape prediction sets class-conditionally without making any distributional assumptions. Experiments on multiple benchmark datasets, including standard and long-tailed image recognition as well as text classification, demonstrate that CaCT consistently outperforms prior conformal training methods, producing significantly smaller and more informative prediction sets while maintaining the desired coverage guarantees.
SoC: Semantic Orthogonal Calibration for Test-Time Prompt Tuning
Jan 13, 2026With the increasing adoption of vision-language models (VLMs) in critical decision-making systems such as healthcare or autonomous driving, the calibration of their uncertainty estimates becomes paramount. Yet, this dimension has been largely underexplored in the VLM test-time prompt-tuning (TPT) literature, which has predominantly focused on improving their discriminative performance. Recent state-of-the-art advocates for enforcing full orthogonality over pairs of text prompt embeddings to enhance separability, and therefore calibration. Nevertheless, as we theoretically show in this work, the inherent gradients from fully orthogonal constraints will strongly push semantically related classes away, ultimately making the model overconfident. Based on our findings, we propose Semantic Orthogonal Calibration (SoC), a Huber-based regularizer that enforces smooth prototype separation while preserving semantic proximity, thereby improving calibration compared to prior orthogonality-based approaches. Across a comprehensive empirical validation, we demonstrate that SoC consistently improves calibration performance, while also maintaining competitive discriminative capabilities.
CAPRMIL: Context-Aware Patch Representations for Multiple Instance Learning
Dec 16, 2025
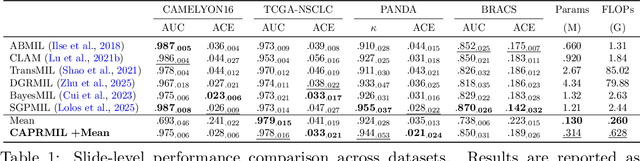
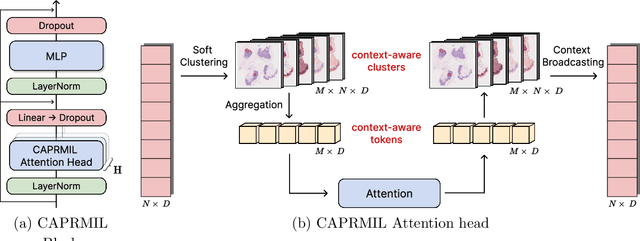

In computational pathology, weak supervision has become the standard for deep learning due to the gigapixel scale of WSIs and the scarcity of pixel-level annotations, with Multiple Instance Learning (MIL) established as the principal framework for slide-level model training. In this paper, we introduce a novel setting for MIL methods, inspired by proceedings in Neural Partial Differential Equation (PDE) Solvers. Instead of relying on complex attention-based aggregation, we propose an efficient, aggregator-agnostic framework that removes the complexity of correlation learning from the MIL aggregator. CAPRMIL produces rich context-aware patch embeddings that promote effective correlation learning on downstream tasks. By projecting patch features -- extracted using a frozen patch encoder -- into a small set of global context/morphology-aware tokens and utilizing multi-head self-attention, CAPRMIL injects global context with linear computational complexity with respect to the bag size. Paired with a simple Mean MIL aggregator, CAPRMIL matches state-of-the-art slide-level performance across multiple public pathology benchmarks, while reducing the total number of trainable parameters by 48%-92.8% versus SOTA MILs, lowering FLOPs during inference by 52%-99%, and ranking among the best models on GPU memory efficiency and training time. Our results indicate that learning rich, context-aware instance representations before aggregation is an effective and scalable alternative to complex pooling for whole-slide analysis. Our code is available at https://github.com/mandlos/CAPRMIL
PVeRA: Probabilistic Vector-Based Random Matrix Adaptation
Dec 08, 2025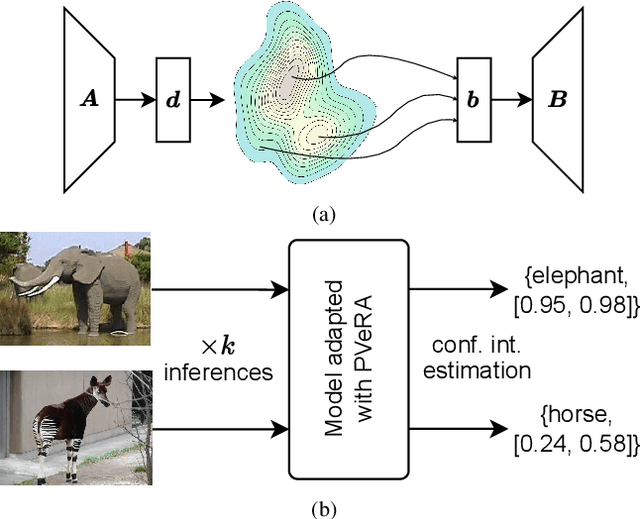
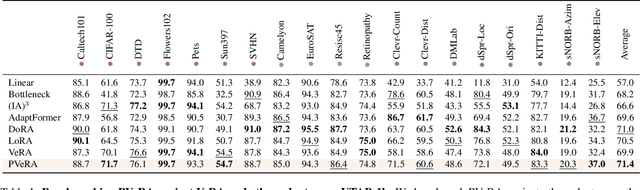
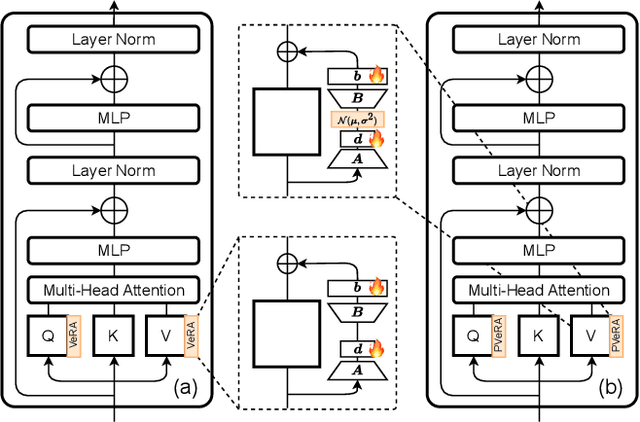

Large foundation models have emerged in the last years and are pushing performance boundaries for a variety of tasks. Training or even finetuning such models demands vast datasets and computational resources, which are often scarce and costly. Adaptation methods provide a computationally efficient solution to address these limitations by allowing such models to be finetuned on small amounts of data and computing power. This is achieved by appending new trainable modules to frozen backbones with only a fraction of the trainable parameters and fitting only these modules on novel tasks. Recently, the VeRA adapter was shown to excel in parameter-efficient adaptations by utilizing a pair of frozen random low-rank matrices shared across all layers. In this paper, we propose PVeRA, a probabilistic version of the VeRA adapter, which modifies the low-rank matrices of VeRA in a probabilistic manner. This modification naturally allows handling inherent ambiguities in the input and allows for different sampling configurations during training and testing. A comprehensive evaluation was performed on the VTAB-1k benchmark and seven adapters, with PVeRA outperforming VeRA and other adapters. Our code for training models with PVeRA and benchmarking all adapters is available https://github.com/leofillioux/pvera.
Controllable Latent Space Augmentation for Digital Pathology
Aug 20, 2025Whole slide image (WSI) analysis in digital pathology presents unique challenges due to the gigapixel resolution of WSIs and the scarcity of dense supervision signals. While Multiple Instance Learning (MIL) is a natural fit for slide-level tasks, training robust models requires large and diverse datasets. Even though image augmentation techniques could be utilized to increase data variability and reduce overfitting, implementing them effectively is not a trivial task. Traditional patch-level augmentation is prohibitively expensive due to the large number of patches extracted from each WSI, and existing feature-level augmentation methods lack control over transformation semantics. We introduce HistAug, a fast and efficient generative model for controllable augmentations in the latent space for digital pathology. By conditioning on explicit patch-level transformations (e.g., hue, erosion), HistAug generates realistic augmented embeddings while preserving initial semantic information. Our method allows the processing of a large number of patches in a single forward pass efficiently, while at the same time consistently improving MIL model performance. Experiments across multiple slide-level tasks and diverse organs show that HistAug outperforms existing methods, particularly in low-data regimes. Ablation studies confirm the benefits of learned transformations over noise-based perturbations and highlight the importance of uniform WSI-wise augmentation. Code is available at https://github.com/MICS-Lab/HistAug.
On the Risk of Misleading Reports: Diagnosing Textual Biases in Multimodal Clinical AI
Jul 31, 2025



Clinical decision-making relies on the integrated analysis of medical images and the associated clinical reports. While Vision-Language Models (VLMs) can offer a unified framework for such tasks, they can exhibit strong biases toward one modality, frequently overlooking critical visual cues in favor of textual information. In this work, we introduce Selective Modality Shifting (SMS), a perturbation-based approach to quantify a model's reliance on each modality in binary classification tasks. By systematically swapping images or text between samples with opposing labels, we expose modality-specific biases. We assess six open-source VLMs-four generalist models and two fine-tuned for medical data-on two medical imaging datasets with distinct modalities: MIMIC-CXR (chest X-ray) and FairVLMed (scanning laser ophthalmoscopy). By assessing model performance and the calibration of every model in both unperturbed and perturbed settings, we reveal a marked dependency on text input, which persists despite the presence of complementary visual information. We also perform a qualitative attention-based analysis which further confirms that image content is often overshadowed by text details. Our findings highlight the importance of designing and evaluating multimodal medical models that genuinely integrate visual and textual cues, rather than relying on single-modality signals.