 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiga-SSL: Self-Supervised Learning for Gigapixel Images
Dec 06, 2022



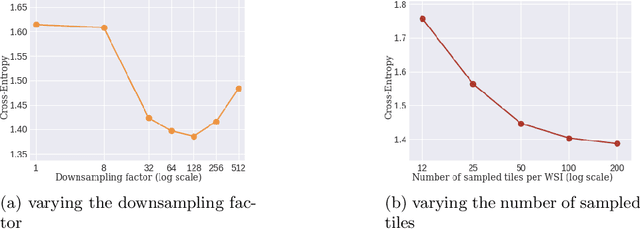
Whole slide images (WSI) are microscopy images of stained tissue slides routinely prepared for diagnosis and treatment selection in medical practice. WSI are very large (gigapixel size) and complex (made of up to millions of cells). The current state-of-the-art (SoTA) approach to classify WSI subdivides them into tiles, encodes them by pre-trained networks and applies Multiple Instance Learning (MIL) to train for specific downstream tasks. However, annotated datasets are often small, typically a few hundred to a few thousand WSI, which may cause overfitting and underperforming models. Conversely, the number of unannotated WSI is ever increasing, with datasets of tens of thousands (soon to be millions) of images available. While it has been previously proposed to use these unannotated data to identify suitable tile representations by self-supervised learning (SSL), downstream classification tasks still require full supervision because parts of the MIL architecture is not trained during tile level SSL pre-training. Here, we propose a strategy of slide level SSL to leverage the large number of WSI without annotations to infer powerful slide representations. Applying our method to The Cancer-Genome Atlas, one of the most widely used data resources in cancer research (16 TB image data), we are able to downsize the dataset to 23 MB without any loss in predictive power: we show that a linear classifier trained on top of these embeddings maintains or improves previous SoTA performances on various benchmark WSI classification tasks. Finally, we observe that training a classifier on these representations with tiny datasets (e.g. 50 slides) improved performances over SoTA by an average of +6.3 AUC points over all downstream tasks.
MICS : Multi-steps, Inverse Consistency and Symmetric deep learning registration network
Nov 23, 2021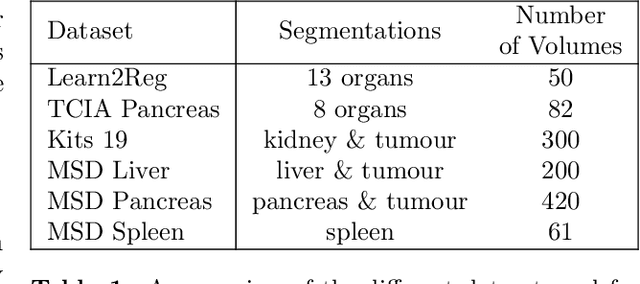
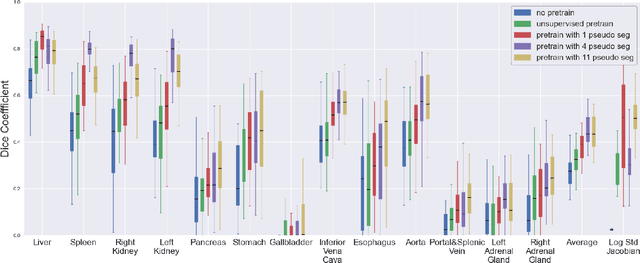
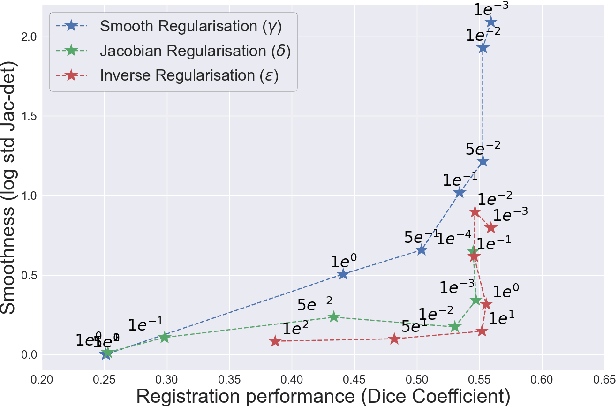

Deformable registration consists of finding the best dense correspondence between two different images. Many algorithms have been published, but the clinical application was made difficult by the high calculation time needed to solve the optimisation problem. Deep learning overtook this limitation by taking advantage of GPU calculation and the learning process. However, many deep learning methods do not take into account desirable properties respected by classical algorithms. In this paper, we present MICS, a novel deep learning algorithm for medical imaging registration. As registration is an ill-posed problem, we focused our algorithm on the respect of different properties: inverse consistency, symmetry and orientation conservation. We also combined our algorithm with a multi-step strategy to refine and improve the deformation grid. While many approaches applied registration to brain MRI, we explored a more challenging body localisation: abdominal CT. Finally, we evaluated our method on a dataset used during the Learn2Reg challenge, allowing a fair comparison with published methods.
Exploring Deep Registration Latent Spaces
Jul 23, 2021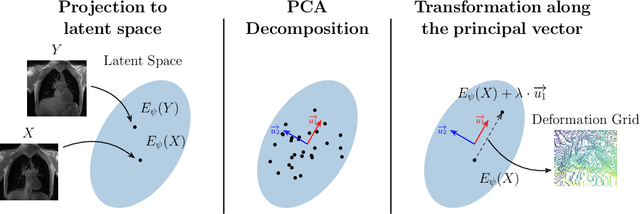
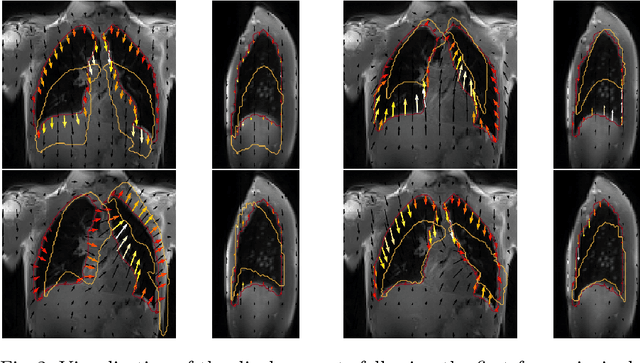
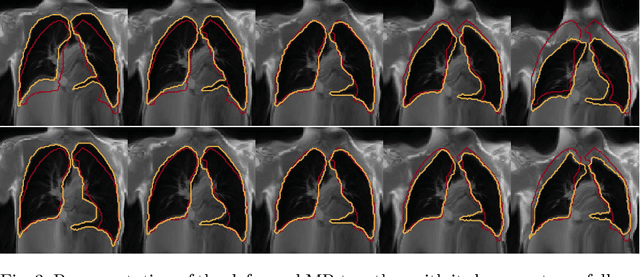
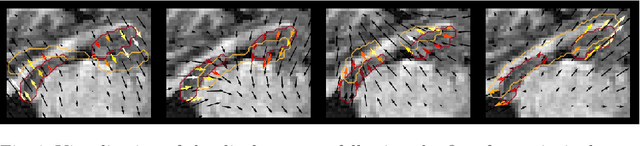
Explainability of deep neural networks is one of the most challenging and interesting problems in the field. In this study, we investigate the topic focusing on the interpretability of deep learning-based registration methods. In particular, with the appropriate model architecture and using a simple linear projection, we decompose the encoding space, generating a new basis, and we empirically show that this basis captures various decomposed anatomically aware geometrical transformations. We perform experiments using two different datasets focusing on lungs and hippocampus MRI. We show that such an approach can decompose the highly convoluted latent spaces of registration pipelines in an orthogonal space with several interesting properties. We hope that this work could shed some light on a better understanding of deep learning-based registration methods.
Weakly supervised pan-cancer segmentation tool
May 10, 2021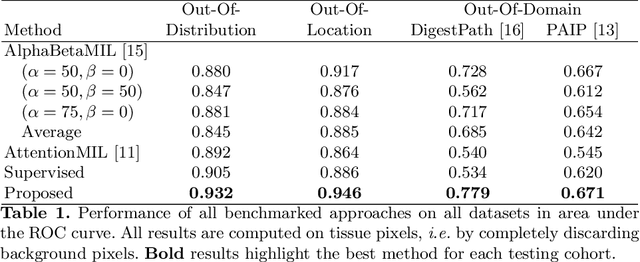
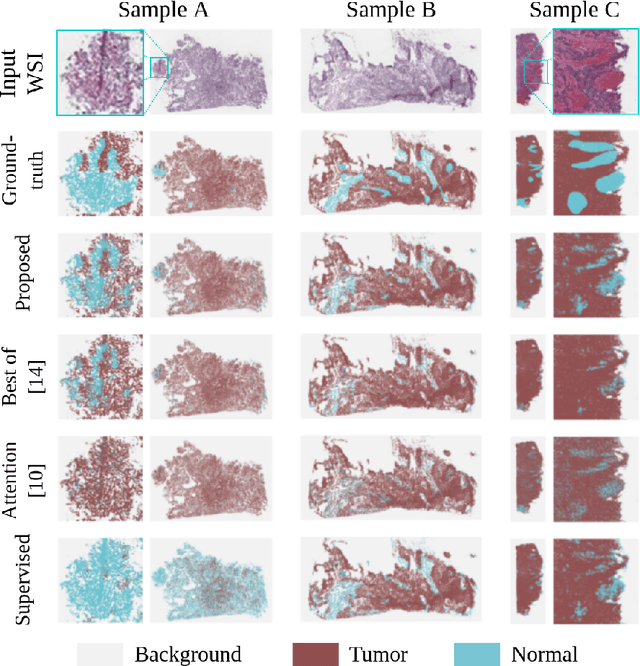
The vast majority of semantic segmentation approaches rely on pixel-level annotations that are tedious and time consuming to obtain and suffer from significant inter and intra-expert variability. To address these issues, recent approaches have leveraged categorical annotations at the slide-level, that in general suffer from robustness and generalization. In this paper, we propose a novel weakly supervised multi-instance learning approach that deciphers quantitative slide-level annotations which are fast to obtain and regularly present in clinical routine. The extreme potentials of the proposed approach are demonstrated for tumor segmentation of solid cancer subtypes. The proposed approach achieves superior performance in out-of-distribution, out-of-location, and out-of-domain testing sets.
Sparse convolutional context-aware multiple instance learning for whole slide image classification
May 06, 2021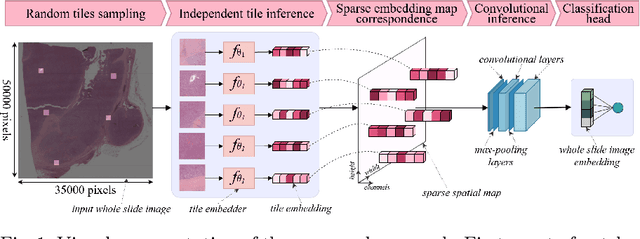
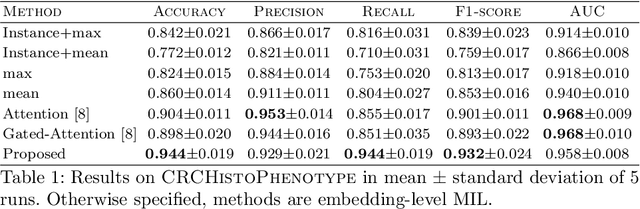
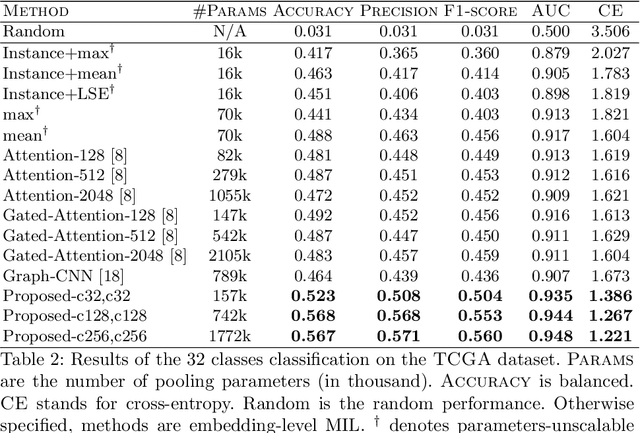
Whole slide microscopic slides display many cues about the underlying tissue guiding diagnostic and the choice of therapy for many diseases. However, their enormous size often in gigapixels hampers the use of traditional neural network architectures. To tackle this issue, multiple instance learning (MIL) classifies bags of patches instead of whole slide images. Most MIL strategies consider that patches are independent and identically distributed. Our approach presents a paradigm shift through the integration of spatial information of patches with a sparse-input convolutional-based MIL strategy. The formulated framework is generic, flexible, scalable and is the first to introduce contextual dependencies between decisions taken at the patch level. It achieved state-of-the-art performance in pan-cancer subtype classification. The code of this work will be made available.
Design and implementation of an environment for Learning to Run a Power Network (L2RPN)
Apr 06, 2021



This report summarizes work performed as part of an internship at INRIA, in partial requirement for the completion of a master degree in math and informatics. The goal of the internship was to develop a software environment to simulate electricity transmission in a power grid and actions performed by operators to maintain this grid in security. Our environment lends itself to automate the control of the power grid with reinforcement learning agents, assisting human operators. It is amenable to organizing benchmarks, including a challenge in machine learning planned by INRIA and RTE for 2019. Our framework, built on top of open-source libraries, is available at https://github.com/MarvinLer/pypownet. In this report we present intermediary results and its usage in the context of a reinforcement learning game.
Cancer Gene Profiling through Unsupervised Discovery
Feb 11, 2021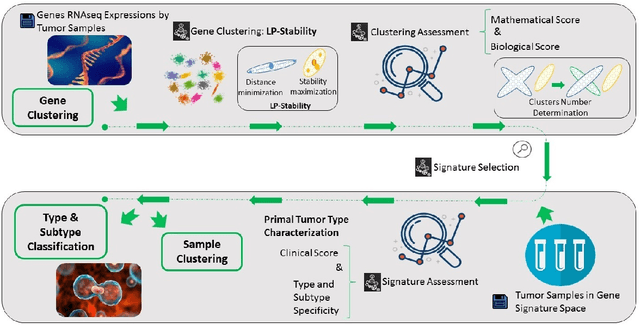
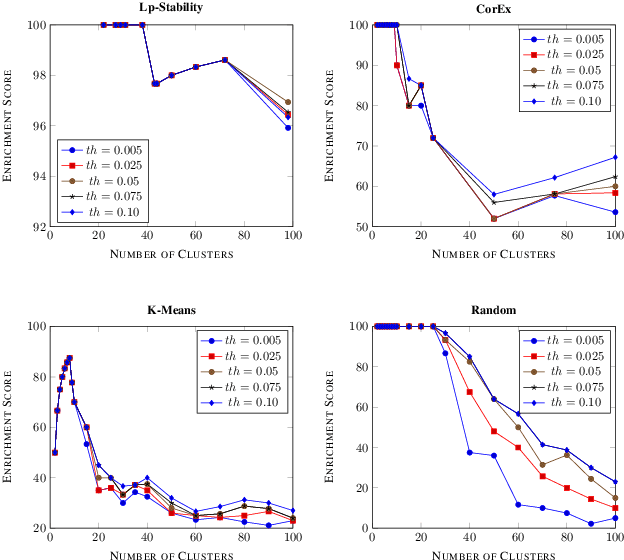
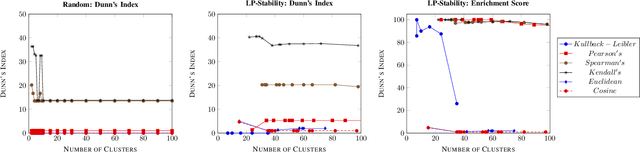
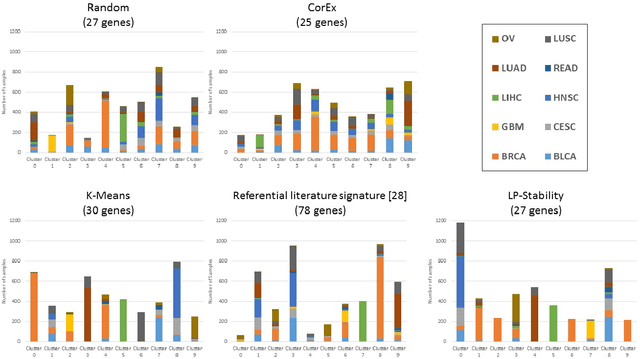
Precision medicine is a paradigm shift in healthcare relying heavily on genomics data. However, the complexity of biological interactions, the large number of genes as well as the lack of comparisons on the analysis of data, remain a tremendous bottleneck regarding clinical adoption. In this paper, we introduce a novel, automatic and unsupervised framework to discover low-dimensional gene biomarkers. Our method is based on the LP-Stability algorithm, a high dimensional center-based unsupervised clustering algorithm, that offers modularity as concerns metric functions and scalability, while being able to automatically determine the best number of clusters. Our evaluation includes both mathematical and biological criteria. The recovered signature is applied to a variety of biological tasks, including screening of biological pathways and functions, and characterization relevance on tumor types and subtypes. Quantitative comparisons among different distance metrics, commonly used clustering methods and a referential gene signature used in the literature, confirm state of the art performance of our approach. In particular, our signature, that is based on 27 genes, reports at least $30$ times better mathematical significance (average Dunn's Index) and 25% better biological significance (average Enrichment in Protein-Protein Interaction) than those produced by other referential clustering methods. Finally, our signature reports promising results on distinguishing immune inflammatory and immune desert tumors, while reporting a high balanced accuracy of 92% on tumor types classification and averaged balanced accuracy of 68% on tumor subtypes classification, which represents, respectively 7% and 9% higher performance compared to the referential signature.
Top 10 BraTS 2020 challenge solution: Brain tumor segmentation with self-ensembled, deeply-supervised 3D-Unet like neural networks
Oct 30, 2020

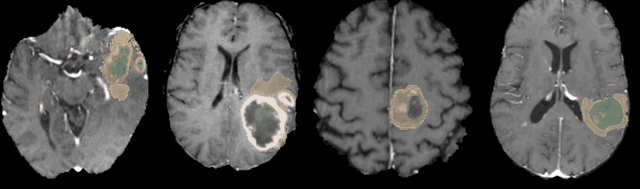

Brain tumor segmentation is a critical task for patient's disease management. To this end, we trained multiple U-net like neural networks, mainly with deep supervision and stochastic weight averaging, on the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2020 training dataset, in a cross-validated fashion. Final brain tumor segmentations were produced by first averaging independently two sets of models, and then custom merging the labelmaps to account for individual performance of each set. Our performance on the online validation dataset with test time augmentation were as follows: Dice of 0.81, 0.91 and 0.85; Hausdorff (95%) of 20.6, 4,3, 5.7 mm for the enhancing tumor, whole tumor and tumor core, respectively. Similarly, our ensemble achieved a Dice of 0.79, 0.89 and 0.84, as well as Hausdorff (95%) of 20.4, 6.7 and 19.5mm on the final test dataset. More complicated training schemes and neural network architectures were investigated, without significant performance gain, at the cost of greatly increased training time. While relatively straightforward, our approach yielded good and balanced performance for each tumor subregions. Our solution is open sourced at https://github.com/lescientifik/xxxxx.
Deep learning based registration using spatial gradients and noisy segmentation labels
Oct 21, 2020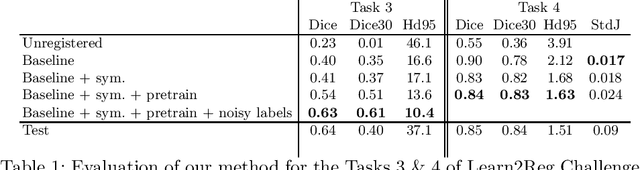
Image registration is one of the most challenging problems in medical image analysis. In the recent years, deep learning based approaches became quite popular, providing fast and performing registration strategies. In this short paper, we summarise our work presented on Learn2Reg challenge 2020. The main contributions of our work rely on (i) a symmetric formulation, predicting the transformations from source to target and from target to source simultaneously, enforcing the trained representations to be similar and (ii) integration of variety of publicly available datasets used both for pretraining and for augmenting segmentation labels. Our method reports a mean dice of $0.64$ for task 3 and $0.85$ for task 4 on the test sets, taking third place on the challenge. Our code and models are publicly available at https://github.com/TheoEst/abdominal_registration and \https://github.com/TheoEst/hippocampus_registration.
Multimodal brain tumor classification
Sep 03, 2020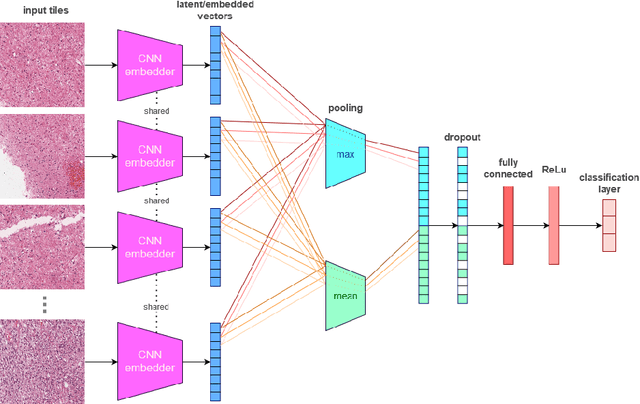
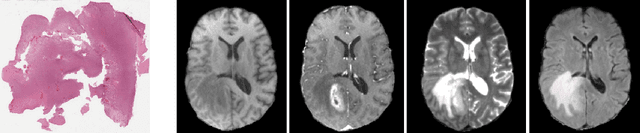
Cancer is a complex disease that provides various types of information depending on the scale of observation. While most tumor diagnostics are performed by observing histopathological slides, radiology images should yield additional knowledge towards the efficacy of cancer diagnostics. This work investigates a deep learning method combining whole slide images and magnetic resonance images to classify tumors. Experiments are prospectively conducted on the 2020 Computational Precision Medicine challenge, in a 3-classes unbalanced classification task. We report cross-validation (resp. validation) balanced-accuracy, kappa and f1 of 0.913, 0.897 and 0.951 (resp. 0.91, 0.90 and 0.94). The complete code of the method is open-source at XXXX. Those include histopathological data pre-processing, and can therefore be used off-the-shelf for other histopathological and/or radiological classification.