 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalised Insulin Adjustment with Reinforcement Learning: An In-Silico Validation for People with Diabetes on Intensive Insulin Treatment
May 20, 2025Despite recent advances in insulin preparations and technology, adjusting insulin remains an ongoing challenge for the majority of people with type 1 diabetes (T1D) and longstanding type 2 diabetes (T2D). In this study, we propose the Adaptive Basal-Bolus Advisor (ABBA), a personalised insulin treatment recommendation approach based on reinforcement learning for individuals with T1D and T2D, performing self-monitoring blood glucose measurements and multiple daily insulin injection therapy. We developed and evaluated the ability of ABBA to achieve better time-in-range (TIR) for individuals with T1D and T2D, compared to a standard basal-bolus advisor (BBA). The in-silico test was performed using an FDA-accepted population, including 101 simulated adults with T1D and 101 with T2D. An in-silico evaluation shows that ABBA significantly improved TIR and significantly reduced both times below- and above-range, compared to BBA. ABBA's performance continued to improve over two months, whereas BBA exhibited only modest changes. This personalised method for adjusting insulin has the potential to further optimise glycaemic control and support people with T1D and T2D in their daily self-management. Our results warrant ABBA to be trialed for the first time in humans.
Benchmarking Post-Hoc Unknown-Category Detection in Food Recognition
Mar 24, 2025
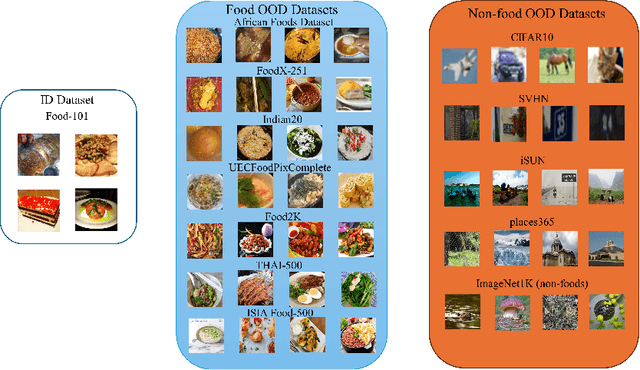

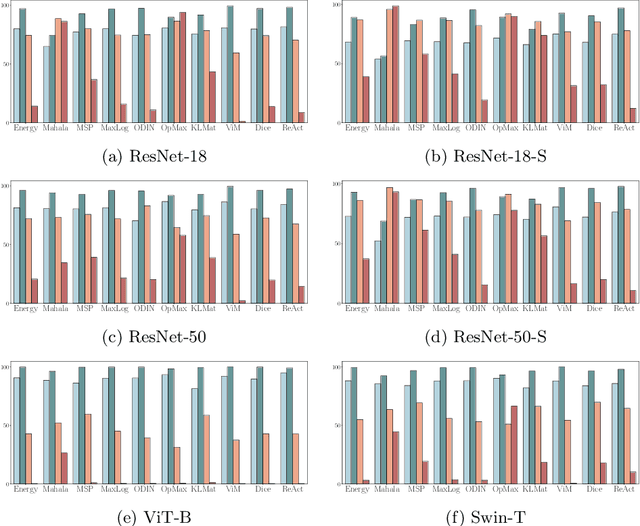
Food recognition models often struggle to distinguish between seen and unseen samples, frequently misclassifying samples from unseen categories by assigning them an in-distribution (ID) label. This misclassification presents significant challenges when deploying these models in real-world applications, particularly within automatic dietary assessment systems, where incorrect labels can lead to cascading errors throughout the system. Ideally, such models should prompt the user when an unknown sample is encountered, allowing for corrective action. Given no prior research exploring food recognition in real-world settings, in this work we conduct an empirical analysis of various post-hoc out-of-distribution (OOD) detection methods for fine-grained food recognition. Our findings indicate that virtual logit matching (ViM) performed the best overall, likely due to its combination of logits and feature-space representations. Additionally, our work reinforces prior notions in the OOD domain, noting that models with higher ID accuracy performed better across the evaluated OOD detection methods. Furthermore, transformer-based architectures consistently outperformed convolution-based models in detecting OOD samples across various methods.
Position: There are no Champions in Long-Term Time Series Forecasting
Feb 19, 2025



Recent advances in long-term time series forecasting have introduced numerous complex prediction models that consistently outperform previously published architectures. However, this rapid progression raises concerns regarding inconsistent benchmarking and reporting practices, which may undermine the reliability of these comparisons. Our position emphasizes the need to shift focus away from pursuing ever-more complex models and towards enhancing benchmarking practices through rigorous and standardized evaluation methods. To support our claim, we first perform a broad, thorough, and reproducible evaluation of the top-performing models on the most popular benchmark by training 3,500+ networks over 14 datasets. Then, through a comprehensive analysis, we find that slight changes to experimental setups or current evaluation metrics drastically shift the common belief that newly published results are advancing the state of the art. Our findings suggest the need for rigorous and standardized evaluation methods that enable more substantiated claims, including reproducible hyperparameter setups and statistical testing.
Tune without Validation: Searching for Learning Rate and Weight Decay on Training Sets
Mar 08, 2024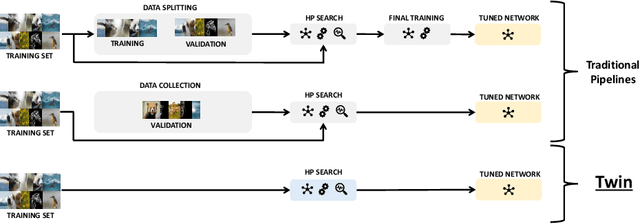
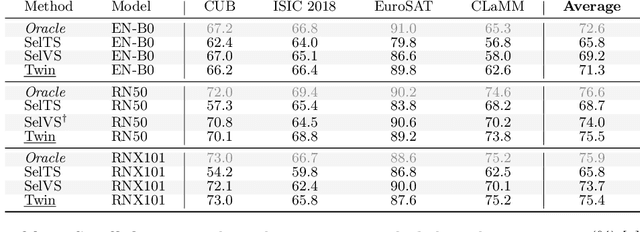
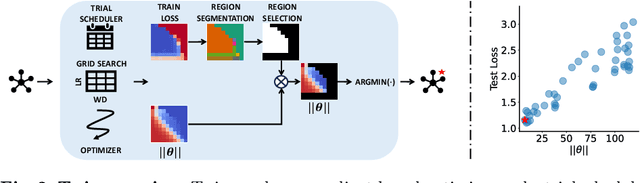
We introduce Tune without Validation (Twin), a pipeline for tuning learning rate and weight decay without validation sets. We leverage a recent theoretical framework concerning learning phases in hypothesis space to devise a heuristic that predicts what hyper-parameter (HP) combinations yield better generalization. Twin performs a grid search of trials according to an early-/non-early-stopping scheduler and then segments the region that provides the best results in terms of training loss. Among these trials, the weight norm strongly correlates with predicting generalization. To assess the effectiveness of Twin, we run extensive experiments on 20 image classification datasets and train several families of deep networks, including convolutional, transformer, and feed-forward models. We demonstrate proper HP selection when training from scratch and fine-tuning, emphasizing small-sample scenarios.
An Empirical Analysis for Zero-Shot Multi-Label Classification on COVID-19 CT Scans and Uncurated Reports
Sep 06, 2023The pandemic resulted in vast repositories of unstructured data, including radiology reports, due to increased medical examinations. Previous research on automated diagnosis of COVID-19 primarily focuses on X-ray images, despite their lower precision compared to computed tomography (CT) scans. In this work, we leverage unstructured data from a hospital and harness the fine-grained details offered by CT scans to perform zero-shot multi-label classification based on contrastive visual language learning. In collaboration with human experts, we investigate the effectiveness of multiple zero-shot models that aid radiologists in detecting pulmonary embolisms and identifying intricate lung details like ground glass opacities and consolidations. Our empirical analysis provides an overview of the possible solutions to target such fine-grained tasks, so far overlooked in the medical multimodal pretraining literature. Our investigation promises future advancements in the medical image analysis community by addressing some challenges associated with unstructured data and fine-grained multi-label classification.
No Data Augmentation? Alternative Regularizations for Effective Training on Small Datasets
Sep 04, 2023



Solving image classification tasks given small training datasets remains an open challenge for modern computer vision. Aggressive data augmentation and generative models are among the most straightforward approaches to overcoming the lack of data. However, the first fails to be agnostic to varying image domains, while the latter requires additional compute and careful design. In this work, we study alternative regularization strategies to push the limits of supervised learning on small image classification datasets. In particular, along with the model size and training schedule scaling, we employ a heuristic to select (semi) optimal learning rate and weight decay couples via the norm of model parameters. By training on only 1% of the original CIFAR-10 training set (i.e., 50 images per class) and testing on ciFAIR-10, a variant of the original CIFAR without duplicated images, we reach a test accuracy of 66.5%, on par with the best state-of-the-art methods.
Food Recognition and Nutritional Apps
Jun 20, 2023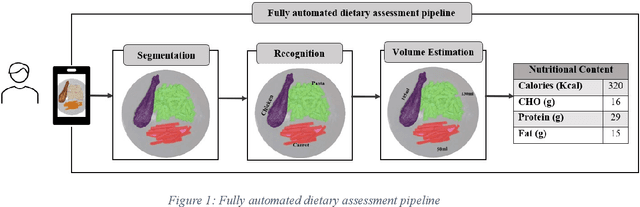


Food recognition and nutritional apps are trending technologies that may revolutionise the way people with diabetes manage their diet. Such apps can monitor food intake as a digital diary and even employ artificial intelligence to assess the diet automatically. Although these apps offer a promising solution for managing diabetes, they are rarely used by patients. This chapter aims to provide an in-depth assessment of the current status of apps for food recognition and nutrition, to identify factors that may inhibit or facilitate their use, while it is accompanied by an outline of relevant research and development.
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Jul 15, 2020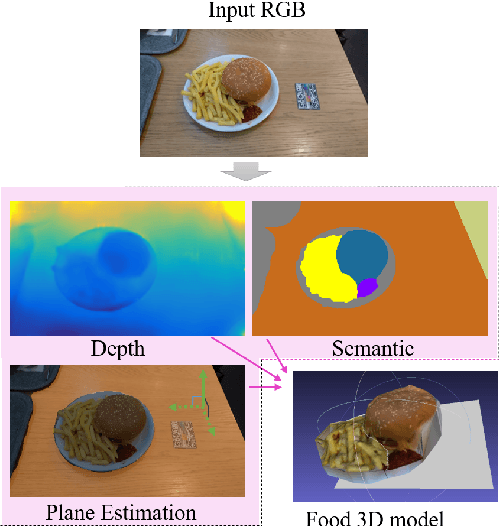


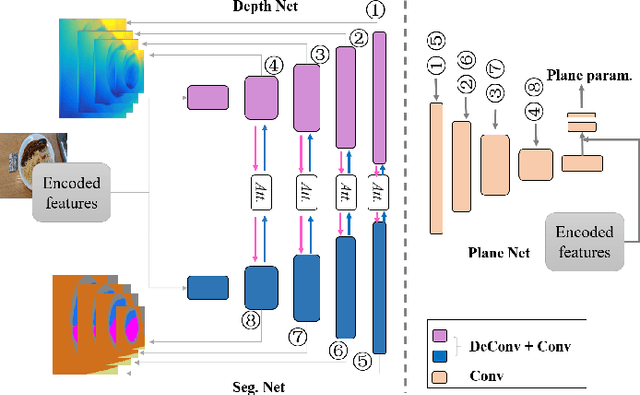
Food volume estimation is an essential step in the pipeline of dietary assessment and demands the precise depth estimation of the food surface and table plane. Existing methods based on computer vision require either multi-image input or additional depth maps, reducing convenience of implementation and practical significance. Despite the recent advances in unsupervised depth estimation from a single image, the achieved performance in the case of large texture-less areas needs to be improved. In this paper, we propose a network architecture that jointly performs geometric understanding (i.e., depth prediction and 3D plane estimation) and semantic prediction on a single food image, enabling a robust and accurate food volume estimation regardless of the texture characteristics of the target plane. For the training of the network, only monocular videos with semantic ground truth are required, while the depth map and 3D plane ground truth are no longer needed. Experimental results on two separate food image databases demonstrate that our method performs robustly on texture-less scenarios and is superior to unsupervised networks and structure from motion based approaches, while it achieves comparable performance to fully-supervised methods.
An Artificial Intelligence-Based System to Assess Nutrient Intake for Hospitalised Patients
Mar 18, 2020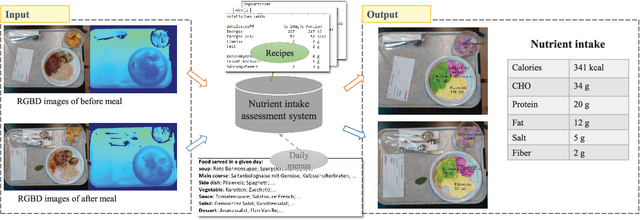
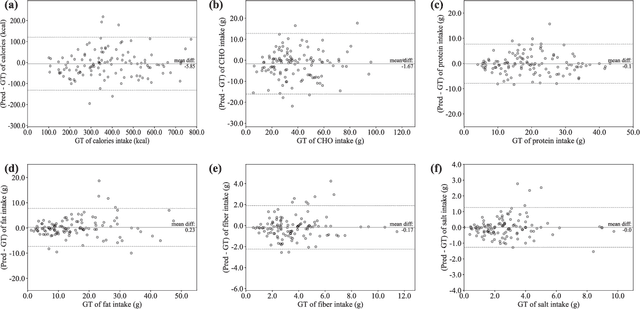
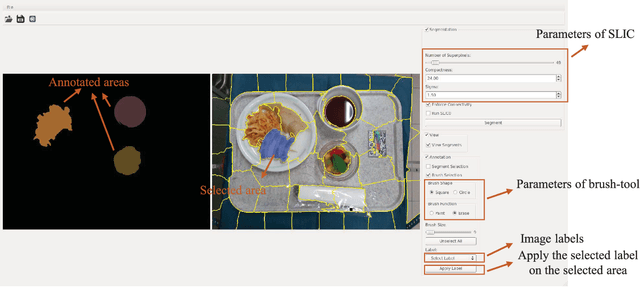
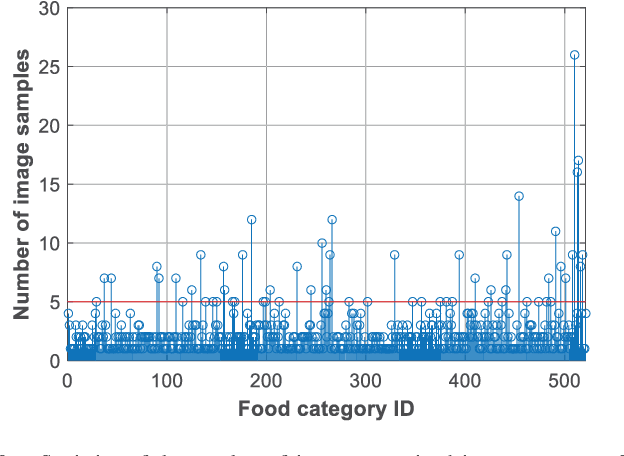
Regular monitoring of nutrient intake in hospitalised patients plays a critical role in reducing the risk of disease-related malnutrition. Although several methods to estimate nutrient intake have been developed, there is still a clear demand for a more reliable and fully automated technique, as this could improve data accuracy and reduce both the burden on participants and health costs. In this paper, we propose a novel system based on artificial intelligence (AI) to accurately estimate nutrient intake, by simply processing RGB Depth (RGB-D) image pairs captured before and after meal consumption. The system includes a novel multi-task contextual network for food segmentation, a few-shot learning-based classifier built by limited training samples for food recognition, and an algorithm for 3D surface construction. This allows sequential food segmentation, recognition, and estimation of the consumed food volume, permitting fully automatic estimation of the nutrient intake for each meal. For the development and evaluation of the system, a dedicated new database containing images and nutrient recipes of 322 meals is assembled, coupled to data annotation using innovative strategies. Experimental results demonstrate that the estimated nutrient intake is highly correlated (> 0.91) to the ground truth and shows very small mean relative errors (< 20%), outperforming existing techniques proposed for nutrient intake assessment.
Self-Attention and Ingredient-Attention Based Model for Recipe Retrieval from Image Queries
Nov 05, 2019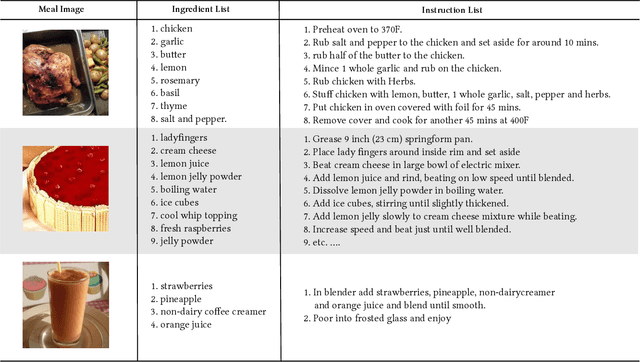
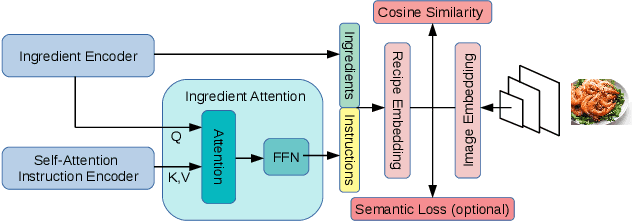
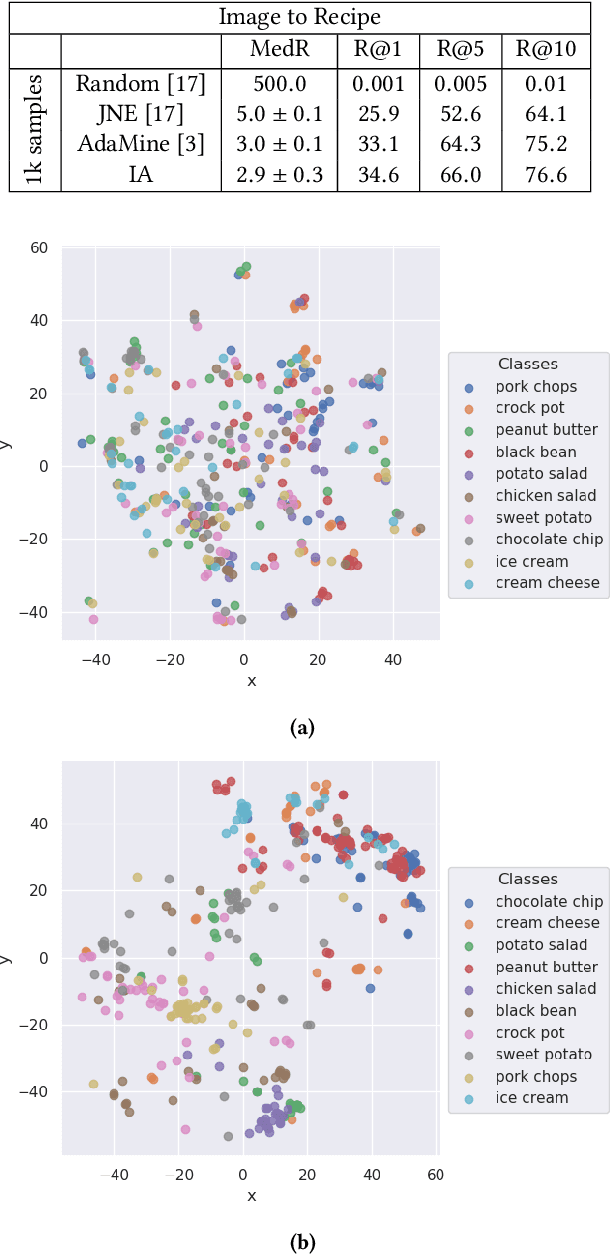

Direct computer vision based-nutrient content estimation is a demanding task, due to deformation and occlusions of ingredients, as well as high intra-class and low inter-class variability between meal classes. In order to tackle these issues, we propose a system for recipe retrieval from images. The recipe information can subsequently be used to estimate the nutrient content of the meal. In this study, we utilize the multi-modal Recipe1M dataset, which contains over 1 million recipes accompanied by over 13 million images. The proposed model can operate as a first step in an automatic pipeline for the estimation of nutrition content by supporting hints related to ingredient and instruction. Through self-attention, our model can directly process raw recipe text, making the upstream instruction sentence embedding process redundant and thus reducing training time, while providing desirable retrieval results. Furthermore, we propose the use of an ingredient attention mechanism, in order to gain insight into which instructions, parts of instructions or single instruction words are of importance for processing a single ingredient within a certain recipe. Attention-based recipe text encoding contributes to solving the issue of high intra-class/low inter-class variability by focusing on preparation steps specific to the meal. The experimental results demonstrate the potential of such a system for recipe retrieval from images. A comparison with respect to two baseline methods is also presented.