 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune without Validation: Searching for Learning Rate and Weight Decay on Training Sets
Paper and Code
Mar 08, 2024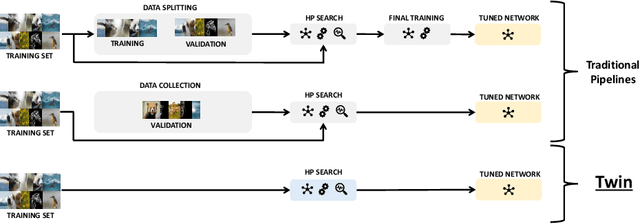
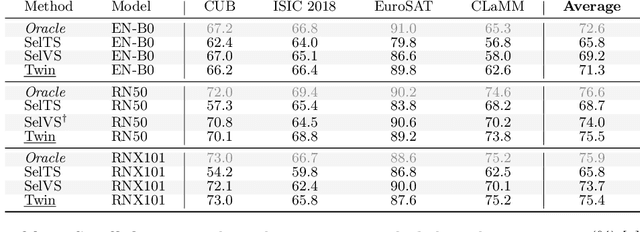
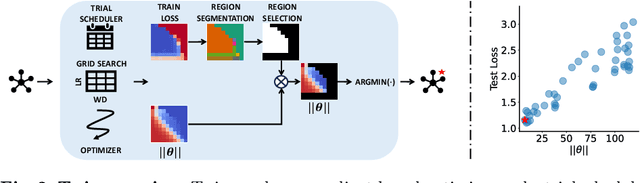
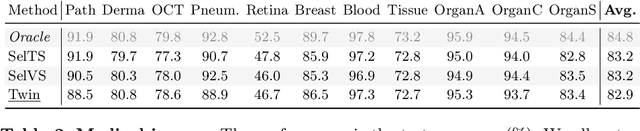
We introduce Tune without Validation (Twin), a pipeline for tuning learning rate and weight decay without validation sets. We leverage a recent theoretical framework concerning learning phases in hypothesis space to devise a heuristic that predicts what hyper-parameter (HP) combinations yield better generalization. Twin performs a grid search of trials according to an early-/non-early-stopping scheduler and then segments the region that provides the best results in terms of training loss. Among these trials, the weight norm strongly correlates with predicting generalization. To assess the effectiveness of Twin, we run extensive experiments on 20 image classification datasets and train several families of deep networks, including convolutional, transformer, and feed-forward models. We demonstrate proper HP selection when training from scratch and fine-tuning, emphasizing small-sample scenarios.