 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Nuclei Segmentation in Histopathological Images Using Attention
Jul 16, 2020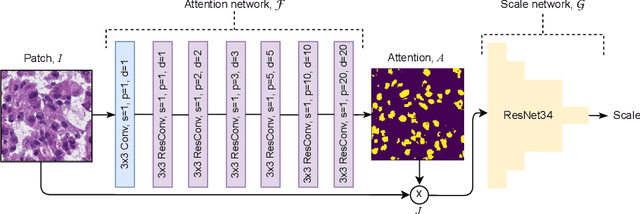
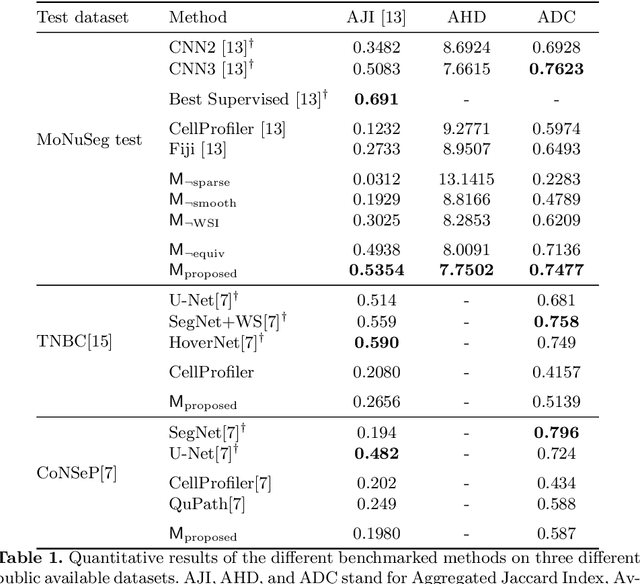

Segmentation and accurate localization of nuclei in histopathological images is a very challenging problem, with most existing approaches adopting a supervised strategy. These methods usually rely on manual annotations that require a lot of time and effort from medical experts. In this study, we present a self-supervised approach for segmentation of nuclei for whole slide histopathology images. Our method works on the assumption that the size and texture of nuclei can determine the magnification at which a patch is extracted. We show that the identification of the magnification level for tiles can generate a preliminary self-supervision signal to locate nuclei. We further show that by appropriately constraining our model it is possible to retrieve meaningful segmentation maps as an auxiliary output to the primary magnification identification task. Our experiments show that with standard post-processing, our method can outperform other unsupervised nuclei segmentation approaches and report similar performance with supervised ones on the publicly available MoNuSeg dataset. Our code and models are available online to facilitate further research.
Lifting AutoEncoders: Unsupervised Learning of a Fully-Disentangled 3D Morphable Model using Deep Non-Rigid Structure from Motion
Apr 26, 2019
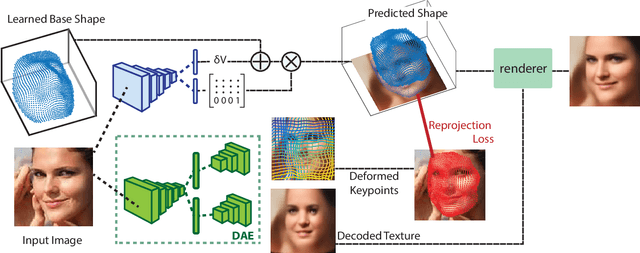


In this work we introduce Lifting Autoencoders, a generative 3D surface-based model of object categories. We bring together ideas from non-rigid structure from motion, image formation, and morphable models to learn a controllable, geometric model of 3D categories in an entirely unsupervised manner from an unstructured set of images. We exploit the 3D geometric nature of our model and use normal information to disentangle appearance into illumination, shading and albedo. We further use weak supervision to disentangle the non-rigid shape variability of human faces into identity and expression. We combine the 3D representation with a differentiable renderer to generate RGB images and append an adversarially trained refinement network to obtain sharp, photorealistic image reconstruction results. The learned generative model can be controlled in terms of interpretable geometry and appearance factors, allowing us to perform photorealistic image manipulation of identity, expression, 3D pose, and illumination properties.
Linear and Deformable Image Registration with 3D Convolutional Neural Networks
Sep 13, 2018
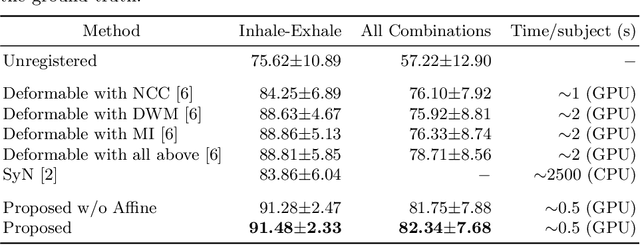


Image registration and in particular deformable registration methods are pillars of medical imaging. Inspired by the recent advances in deep learning, we propose in this paper, a novel convolutional neural network architecture that couples linear and deformable registration within a unified architecture endowed with near real-time performance. Our framework is modular with respect to the global transformation component, as well as with respect to the similarity function while it guarantees smooth displacement fields. We evaluate the performance of our network on the challenging problem of MRI lung registration, and demonstrate superior performance with respect to state of the art elastic registration methods. The proposed deformation (between inspiration & expiration) was considered within a clinically relevant task of interstitial lung disease (ILD) classification and showed promising results.
Deforming Autoencoders: Unsupervised Disentangling of Shape and Appearance
Jun 18, 2018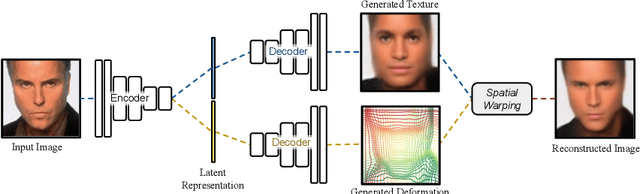

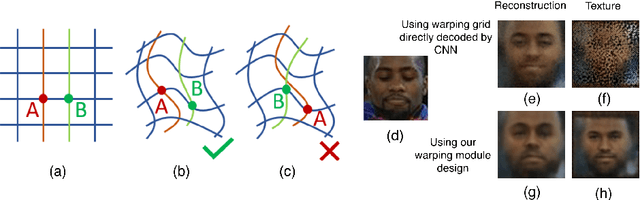

In this work we introduce Deforming Autoencoders, a generative model for images that disentangles shape from appearance in an unsupervised manner. As in the deformable template paradigm, shape is represented as a deformation between a canonical coordinate system (`template') and an observed image, while appearance is modeled in `canonical', template, coordinates, thus discarding variability due to deformations. We introduce novel techniques that allow this approach to be deployed in the setting of autoencoders and show that this method can be used for unsupervised group-wise image alignment. We show experiments with expression morphing in humans, hands, and digits, face manipulation, such as shape and appearance interpolation, as well as unsupervised landmark localization. A more powerful form of unsupervised disentangling becomes possible in template coordinates, allowing us to successfully decompose face images into shading and albedo, and further manipulate face images.