 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in Automated Speaker Recognition
Paper and Code

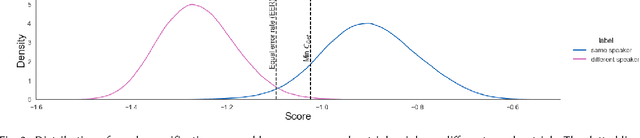

Automated speaker recognition uses data processing to identify speakers by their voice. Today, automated speaker recognition technologies are deployed on billions of smart devices and in services such as call centres. Despite their wide-scale deployment and known sources of bias in face recognition and natural language processing, bias in automated speaker recognition has not been studied systematically. We present an in-depth empirical and analytical study of bias in the machine learning development workflow of speaker verification, a voice biometric and core task in automated speaker recognition. Drawing on an established framework for understanding sources of harm in machine learning, we show that bias exists at every development stage in the well-known VoxCeleb Speaker Recognition Challenge, including model building, implementation, and data generation. Most affected are female speakers and non-US nationalities, who experience significant performance degradation. Leveraging the insights from our findings, we make practical recommendations for mitigating bias in automated speaker recognition, and outline future research directions.