 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs
Mar 31, 2025We address the task of video chaptering, i.e., partitioning a long video timeline into semantic units and generating corresponding chapter titles. While relatively underexplored, automatic chaptering has the potential to enable efficient navigation and content retrieval in long-form videos. In this paper, we achieve strong chaptering performance on hour-long videos by efficiently addressing the problem in the text domain with our 'Chapter-Llama' framework. Specifically, we leverage a pretrained large language model (LLM) with large context window, and feed as input (i) speech transcripts and (ii) captions describing video frames, along with their respective timestamps. Given the inefficiency of exhaustively captioning all frames, we propose a lightweight speech-guided frame selection strategy based on speech transcript content, and experimentally demonstrate remarkable advantages. We train the LLM to output timestamps for the chapter boundaries, as well as free-form chapter titles. This simple yet powerful approach scales to processing one-hour long videos in a single forward pass. Our results demonstrate substantial improvements (e.g., 45.3 vs 26.7 F1 score) over the state of the art on the recent VidChapters-7M benchmark. To promote further research, we release our code and models at our project page.
Learning text-to-video retrieval from image captioning
Apr 26, 2024
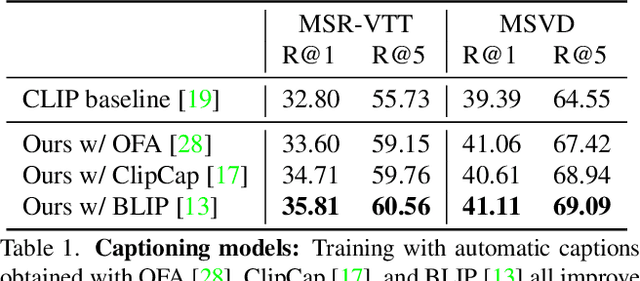

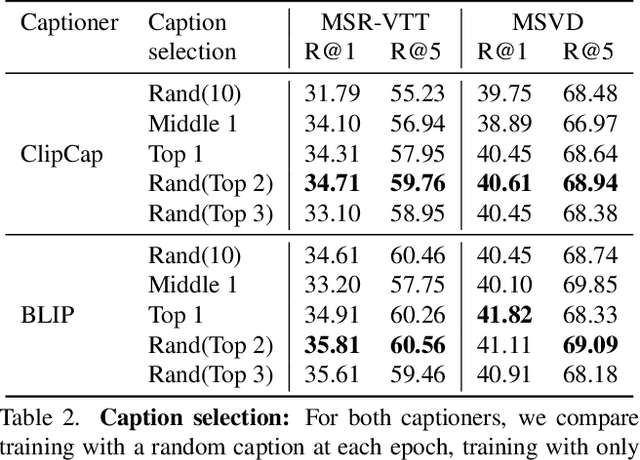
We describe a protocol to study text-to-video retrieval training with unlabeled videos, where we assume (i) no access to labels for any videos, i.e., no access to the set of ground-truth captions, but (ii) access to labeled images in the form of text. Using image expert models is a realistic scenario given that annotating images is cheaper therefore scalable, in contrast to expensive video labeling schemes. Recently, zero-shot image experts such as CLIP have established a new strong baseline for video understanding tasks. In this paper, we make use of this progress and instantiate the image experts from two types of models: a text-to-image retrieval model to provide an initial backbone, and image captioning models to provide supervision signal into unlabeled videos. We show that automatically labeling video frames with image captioning allows text-to-video retrieval training. This process adapts the features to the target domain at no manual annotation cost, consequently outperforming the strong zero-shot CLIP baseline. During training, we sample captions from multiple video frames that best match the visual content, and perform a temporal pooling over frame representations by scoring frames according to their relevance to each caption. We conduct extensive ablations to provide insights and demonstrate the effectiveness of this simple framework by outperforming the CLIP zero-shot baselines on text-to-video retrieval on three standard datasets, namely ActivityNet, MSR-VTT, and MSVD.
CoVR: Learning Composed Video Retrieval from Web Video Captions
Aug 28, 2023Composed Image Retrieval (CoIR) has recently gained popularity as a task that considers both text and image queries together, to search for relevant images in a database. Most CoIR approaches require manually annotated datasets, comprising image-text-image triplets, where the text describes a modification from the query image to the target image. However, manual curation of CoIR triplets is expensive and prevents scalability. In this work, we instead propose a scalable automatic dataset creation methodology that generates triplets given video-caption pairs, while also expanding the scope of the task to include composed video retrieval (CoVR). To this end, we mine paired videos with a similar caption from a large database, and leverage a large language model to generate the corresponding modification text. Applying this methodology to the extensive WebVid2M collection, we automatically construct our WebVid-CoVR dataset, resulting in 1.6 million triplets. Moreover, we introduce a new benchmark for CoVR with a manually annotated evaluation set, along with baseline results. Our experiments further demonstrate that training a CoVR model on our dataset effectively transfers to CoIR, leading to improved state-of-the-art performance in the zero-shot setup on both the CIRR and FashionIQ benchmarks. Our code, datasets, and models are publicly available at https://imagine.enpc.fr/~ventural/covr.
Can Everybody Sign Now? Exploring Sign Language Video Generation from 2D Poses
Jan 04, 2021



Recent work have addressed the generation of human poses represented by 2D/3D coordinates of human joints for sign language. We use the state of the art in Deep Learning for motion transfer and evaluate them on How2Sign, an American Sign Language dataset, to generate videos of signers performing sign language given a 2D pose skeleton. We evaluate the generated videos quantitatively and qualitatively showing that the current models are not enough to generated adequate videos for Sign Language due to lack of detail in hands.