 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning text-to-video retrieval from image captioning
Paper and Code

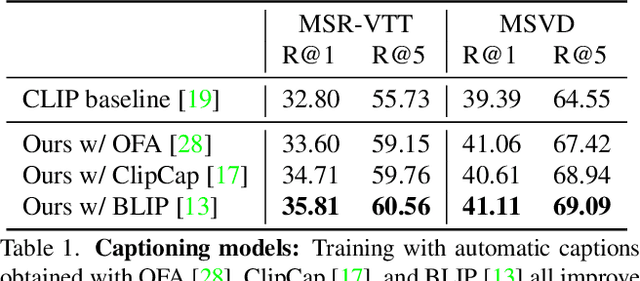

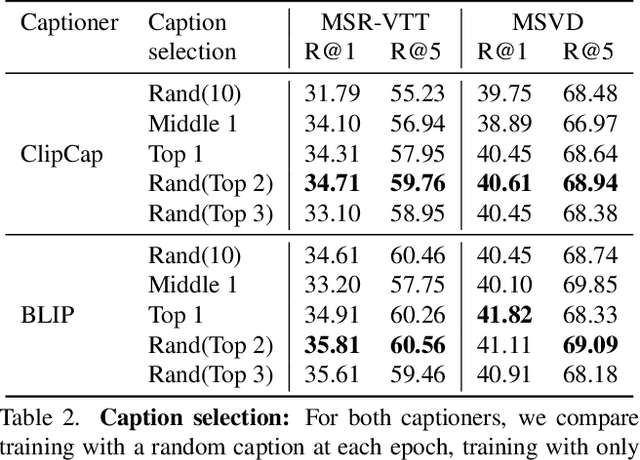
We describe a protocol to study text-to-video retrieval training with unlabeled videos, where we assume (i) no access to labels for any videos, i.e., no access to the set of ground-truth captions, but (ii) access to labeled images in the form of text. Using image expert models is a realistic scenario given that annotating images is cheaper therefore scalable, in contrast to expensive video labeling schemes. Recently, zero-shot image experts such as CLIP have established a new strong baseline for video understanding tasks. In this paper, we make use of this progress and instantiate the image experts from two types of models: a text-to-image retrieval model to provide an initial backbone, and image captioning models to provide supervision signal into unlabeled videos. We show that automatically labeling video frames with image captioning allows text-to-video retrieval training. This process adapts the features to the target domain at no manual annotation cost, consequently outperforming the strong zero-shot CLIP baseline. During training, we sample captions from multiple video frames that best match the visual content, and perform a temporal pooling over frame representations by scoring frames according to their relevance to each caption. We conduct extensive ablations to provide insights and demonstrate the effectiveness of this simple framework by outperforming the CLIP zero-shot baselines on text-to-video retrieval on three standard datasets, namely ActivityNet, MSR-VTT, and MSVD.