 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Affordance Acquisition via Causal Action-Effect Modeling in the Video Domain
Paper and Code
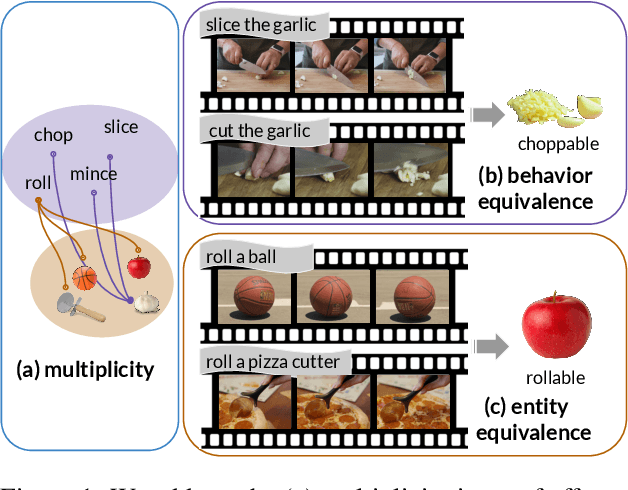
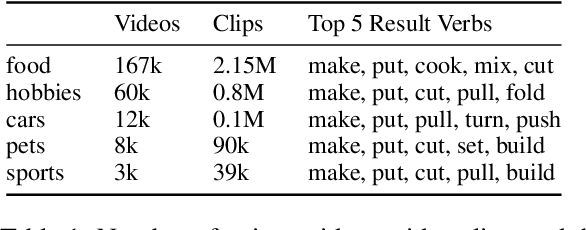

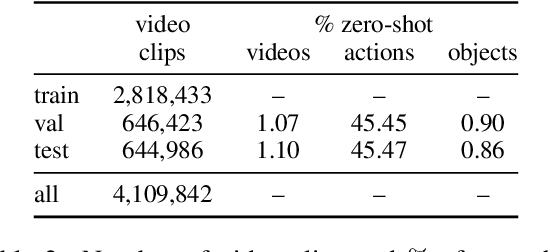
Affordance knowledge is a fundamental aspect of commonsense knowledge. Recent findings indicate that world knowledge emerges through large-scale self-supervised pretraining, motivating our exploration of acquiring affordance knowledge from the visual domain. To this end, we augment an existing instructional video resource to create the new Causal Action-Effect (CAE) dataset and design two novel pretraining tasks -- Masked Action Modeling (MAM) and Masked Effect Modeling (MEM) -- promoting the acquisition of two affordance properties in models: behavior and entity equivalence, respectively. We empirically demonstrate the effectiveness of our proposed methods in learning affordance properties. Furthermore, we show that a model pretrained on both tasks outperforms a strong image-based visual-linguistic foundation model (FLAVA) as well as pure linguistic models on a zero-shot physical reasoning probing task.