 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Modeling of Semantic Fluency Using Transformers
Aug 20, 2022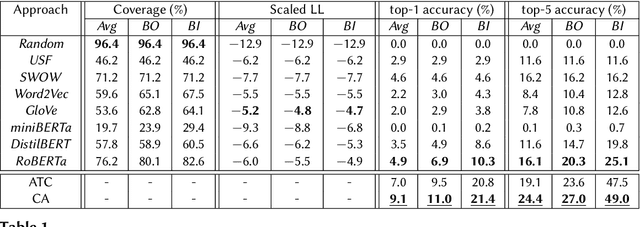

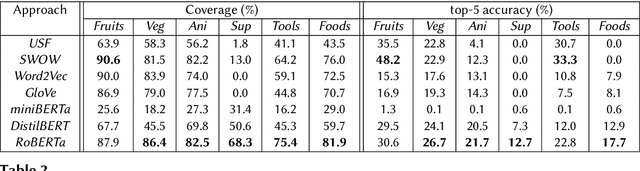

Can deep language models be explanatory models of human cognition? If so, what are their limits? In order to explore this question, we propose an approach called hyperparameter hypothesization that uses predictive hyperparameter tuning in order to find individuating descriptors of cognitive-behavioral profiles. We take the first step in this approach by predicting human performance in the semantic fluency task (SFT), a well-studied task in cognitive science that has never before been modeled using transformer-based language models (TLMs). In our task setup, we compare several approaches to predicting which word an individual performing SFT will utter next. We report preliminary evidence suggesting that, despite obvious implementational differences in how people and TLMs learn and use language, TLMs can be used to identify individual differences in human fluency task behaviors better than existing computational models, and may offer insights into human memory retrieval strategies -- cognitive process not typically considered to be the kinds of things TLMs can model. Finally, we discuss the implications of this work for cognitive modeling of knowledge representations.
On the Complementarity of Images and Text for the Expression of Emotions in Social Media
Feb 11, 2022
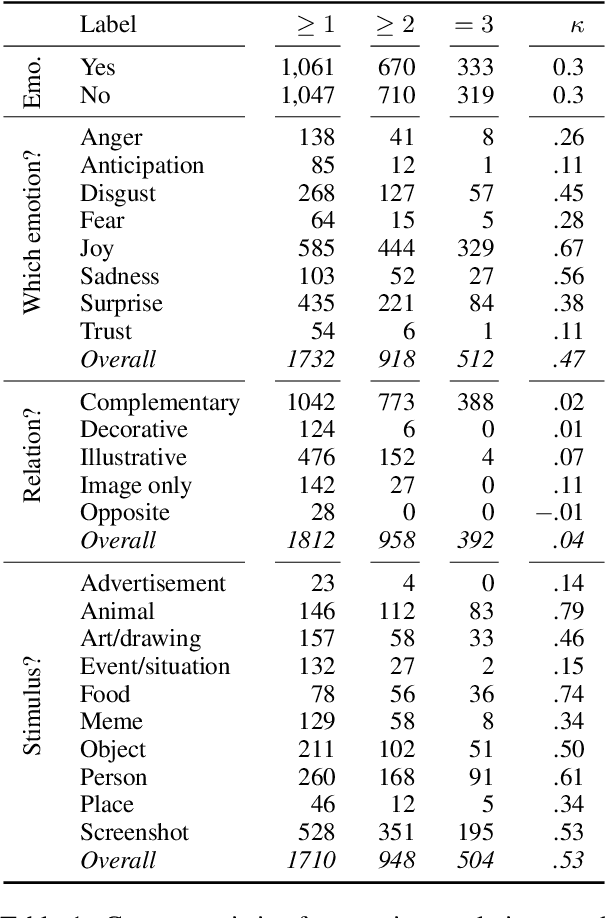


Authors of posts in social media communicate their emotions and what causes them with text and images. While there is work on emotion and stimulus detection for each modality separately, it is yet unknown if the modalities contain complementary emotion information in social media. We aim at filling this research gap and contribute a novel, annotated corpus of English multimodal Reddit posts. On this resource, we develop models to automatically detect the relation between image and text, an emotion stimulus category and the emotion class. We evaluate if these tasks require both modalities and find for the image-text relations, that text alone is sufficient for most categories (complementary, illustrative, opposing): the information in the text allows to predict if an image is required for emotion understanding. The emotions of anger and sadness are best predicted with a multimodal model, while text alone is sufficient for disgust, joy, and surprise. Stimuli depicted by objects, animals, food, or a person are best predicted by image-only models, while multimodal models are most effective on art, events, memes, places, or screenshots.