 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiving AI Personalities Leads to More Human-Like Reasoning
Feb 21, 2025

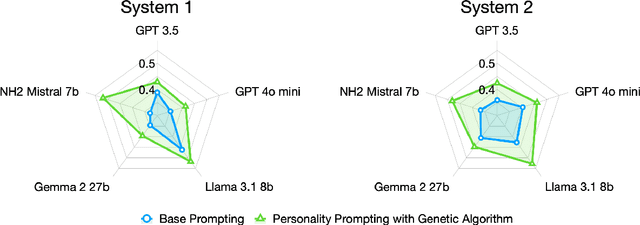

In computational cognitive modeling, capturing the full spectrum of human judgment and decision-making processes, beyond just optimal behaviors, is a significant challenge. This study explores whether Large Language Models (LLMs) can emulate the breadth of human reasoning by predicting both intuitive, fast System 1 and deliberate, slow System 2 processes. We investigate the potential of AI to mimic diverse reasoning behaviors across a human population, addressing what we call the "full reasoning spectrum problem". We designed reasoning tasks using a novel generalization of the Natural Language Inference (NLI) format to evaluate LLMs' ability to replicate human reasoning. The questions were crafted to elicit both System 1 and System 2 responses. Human responses were collected through crowd-sourcing and the entire distribution was modeled, rather than just the majority of the answers. We used personality-based prompting inspired by the Big Five personality model to elicit AI responses reflecting specific personality traits, capturing the diversity of human reasoning, and exploring how personality traits influence LLM outputs. Combined with genetic algorithms to optimize the weighting of these prompts, this method was tested alongside traditional machine learning models. The results show that LLMs can mimic human response distributions, with open-source models like Llama and Mistral outperforming proprietary GPT models. Personality-based prompting, especially when optimized with genetic algorithms, significantly enhanced LLMs' ability to predict human response distributions, suggesting that capturing suboptimal, naturalistic reasoning may require modeling techniques incorporating diverse reasoning styles and psychological profiles. The study concludes that personality-based prompting combined with genetic algorithms is promising for enhancing AI's 'human-ness' in reasoning.
No Strong Feelings One Way or Another: Re-operationalizing Neutrality in Natural Language Inference
Jun 16, 2023



Natural Language Inference (NLI) has been a cornerstone task in evaluating language models' inferential reasoning capabilities. However, the standard three-way classification scheme used in NLI has well-known shortcomings in evaluating models' ability to capture the nuances of natural human reasoning. In this paper, we argue that the operationalization of the neutral label in current NLI datasets has low validity, is interpreted inconsistently, and that at least one important sense of neutrality is often ignored. We uncover the detrimental impact of these shortcomings, which in some cases leads to annotation datasets that actually decrease performance on downstream tasks. We compare approaches of handling annotator disagreement and identify flaws in a recent NLI dataset that designs an annotator study based on a problematic operationalization. Our findings highlight the need for a more refined evaluation framework for NLI, and we hope to spark further discussion and action in the NLP community.
Resoling Open-textured Rules with Templated Interpretive Arguments
Dec 19, 2022
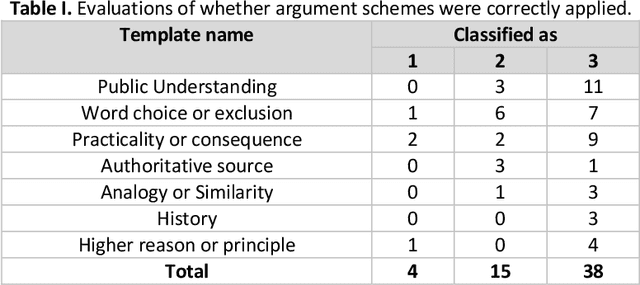
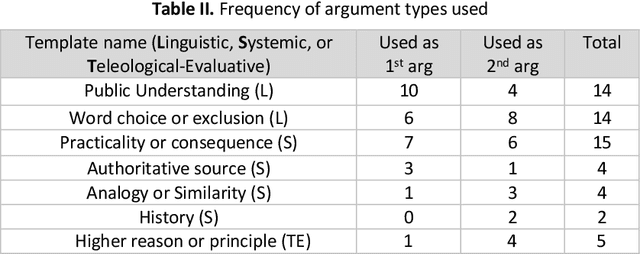
Open-textured terms in written rules are typically settled through interpretive argumentation. Ongoing work has attempted to catalogue the schemes used in such interpretive argumentation. But how can the use of these schemes affect the way in which people actually use and reason over the proper interpretations of open-textured terms? Using the interpretive argument-eliciting game Aporia as our framework, we carried out an empirical study to answer this question. Differing from previous work, we did not allow participants to argue for interpretations arbitrarily, but to only use arguments that fit with a given set of interpretive argument templates. Finally, we analyze the results captured by this new dataset, specifically focusing on practical implications for the development of interpretation-capable artificial reasoners.
Cognitive Modeling of Semantic Fluency Using Transformers
Aug 20, 2022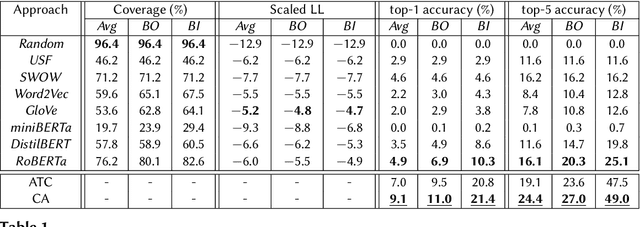

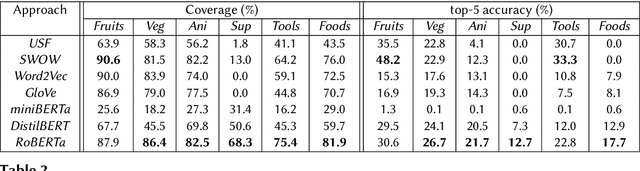

Can deep language models be explanatory models of human cognition? If so, what are their limits? In order to explore this question, we propose an approach called hyperparameter hypothesization that uses predictive hyperparameter tuning in order to find individuating descriptors of cognitive-behavioral profiles. We take the first step in this approach by predicting human performance in the semantic fluency task (SFT), a well-studied task in cognitive science that has never before been modeled using transformer-based language models (TLMs). In our task setup, we compare several approaches to predicting which word an individual performing SFT will utter next. We report preliminary evidence suggesting that, despite obvious implementational differences in how people and TLMs learn and use language, TLMs can be used to identify individual differences in human fluency task behaviors better than existing computational models, and may offer insights into human memory retrieval strategies -- cognitive process not typically considered to be the kinds of things TLMs can model. Finally, we discuss the implications of this work for cognitive modeling of knowledge representations.
Predicting Human Psychometric Properties Using Computational Language Models
May 12, 2022
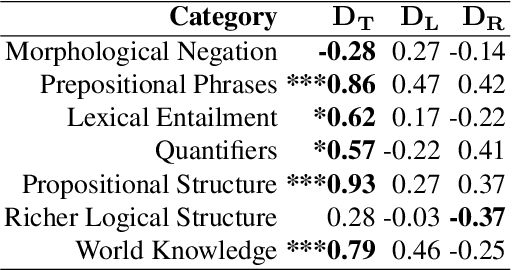
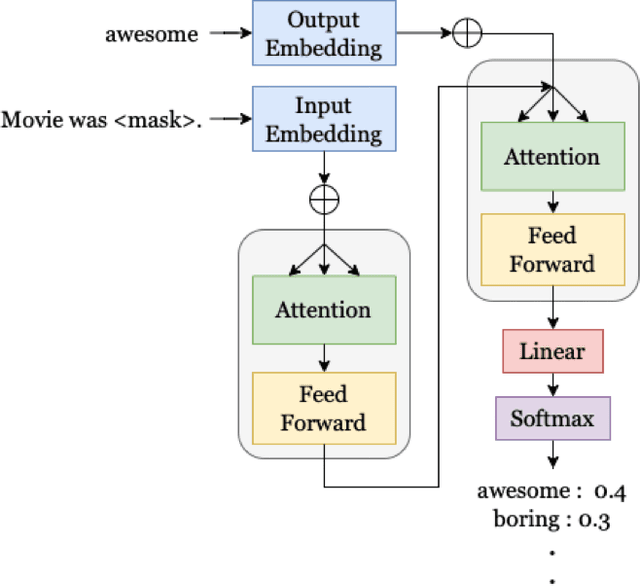
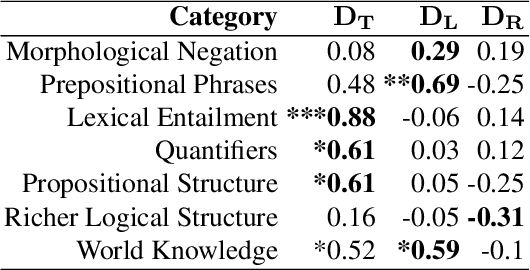
Transformer-based language models (LMs) continue to achieve state-of-the-art performance on natural language processing (NLP) benchmarks, including tasks designed to mimic human-inspired "commonsense" competencies. To better understand the degree to which LMs can be said to have certain linguistic reasoning skills, researchers are beginning to adapt the tools and concepts from psychometrics. But to what extent can benefits flow in the other direction? In other words, can LMs be of use in predicting the psychometric properties of test items, when those items are given to human participants? If so, the benefit for psychometric practitioners is enormous, as it can reduce the need for multiple rounds of empirical testing. We gather responses from numerous human participants and LMs (transformer- and non-transformer-based) on a broad diagnostic test of linguistic competencies. We then use the human responses to calculate standard psychometric properties of the items in the diagnostic test, using the human responses and the LM responses separately. We then determine how well these two sets of predictions correlate. We find that transformer-based LMs predict the human psychometric data consistently well across most categories, suggesting that they can be used to gather human-like psychometric data without the need for extensive human trials.
Developmental Negation Processing in Transformer Language Models
Apr 29, 2022
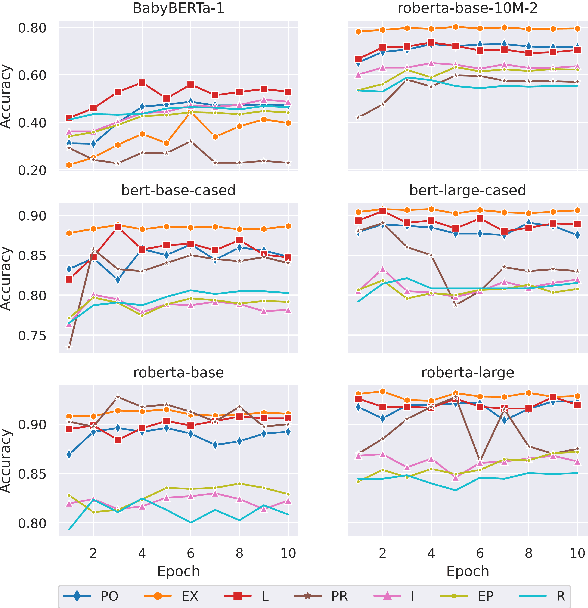

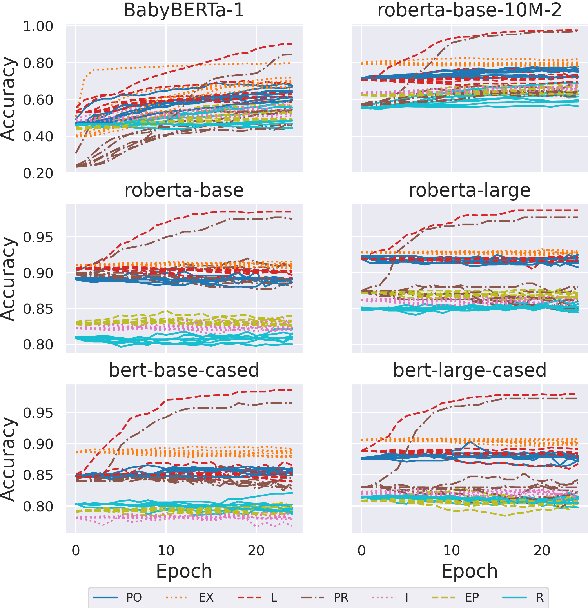
Reasoning using negation is known to be difficult for transformer-based language models. While previous studies have used the tools of psycholinguistics to probe a transformer's ability to reason over negation, none have focused on the types of negation studied in developmental psychology. We explore how well transformers can process such categories of negation, by framing the problem as a natural language inference (NLI) task. We curate a set of diagnostic questions for our target categories from popular NLI datasets and evaluate how well a suite of models reason over them. We find that models perform consistently better only on certain categories, suggesting clear distinctions in how they are processed.
How Should AI Interpret Rules? A Defense of Minimally Defeasible Interpretive Argumentation
Oct 26, 2021Can artificially intelligent systems follow rules? The answer might seem an obvious `yes', in the sense that all (current) AI strictly acts in accordance with programming code constructed from highly formalized and well-defined rulesets. But here I refer to the kinds of rules expressed in human language that are the basis of laws, regulations, codes of conduct, ethical guidelines, and so on. The ability to follow such rules, and to reason about them, is not nearly as clear-cut as it seems on first analysis. Real-world rules are unavoidably rife with open-textured terms, which imbue rules with a possibly infinite set of possible interpretations. Narrowing down this set requires a complex reasoning process that is not yet within the scope of contemporary AI. This poses a serious problem for autonomous AI: If one cannot reason about open-textured terms, then one cannot reason about (or in accordance with) real-world rules. And if one cannot reason about real-world rules, then one cannot: follow human laws, comply with regulations, act in accordance with written agreements, or even obey mission-specific commands that are anything more than trivial. But before tackling these problems, we must first answer a more fundamental question: Given an open-textured rule, what is its correct interpretation? Or more precisely: How should our artificially intelligent systems determine which interpretation to consider correct? In this essay, I defend the following answer: Rule-following AI should act in accordance with the interpretation best supported by minimally defeasible interpretive arguments (MDIA).
Evaluating Multiway Multilingual NMT in the Turkic Languages
Sep 13, 2021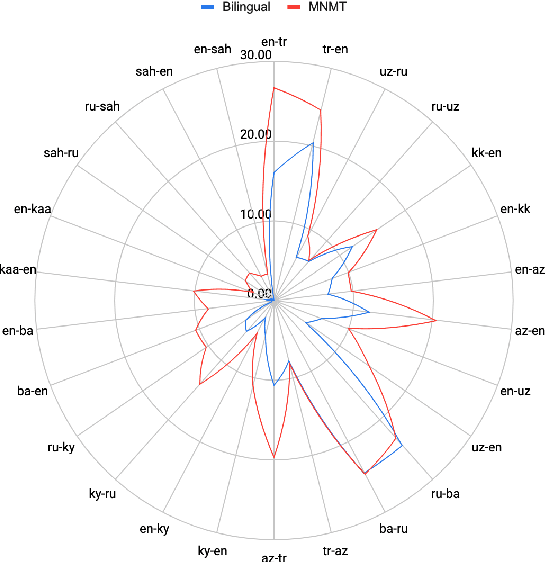
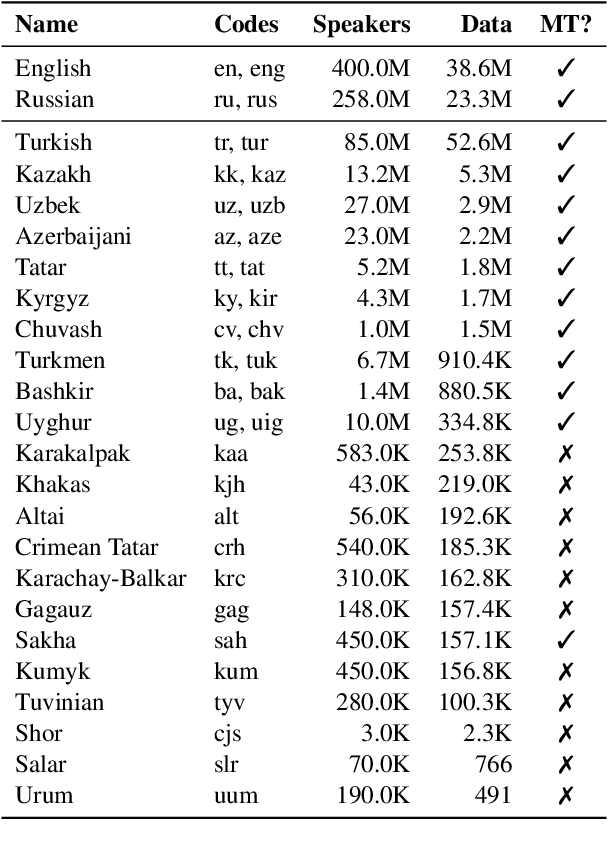

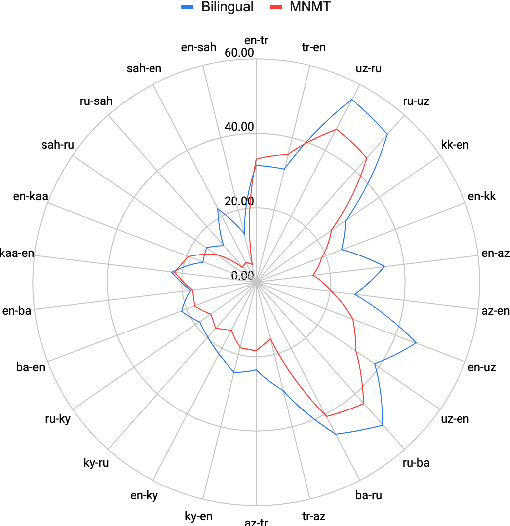
Despite the increasing number of large and comprehensive machine translation (MT) systems, evaluation of these methods in various languages has been restrained by the lack of high-quality parallel corpora as well as engagement with the people that speak these languages. In this study, we present an evaluation of state-of-the-art approaches to training and evaluating MT systems in 22 languages from the Turkic language family, most of which being extremely under-explored. First, we adopt the TIL Corpus with a few key improvements to the training and the evaluation sets. Then, we train 26 bilingual baselines as well as a multi-way neural MT (MNMT) model using the corpus and perform an extensive analysis using automatic metrics as well as human evaluations. We find that the MNMT model outperforms almost all bilingual baselines in the out-of-domain test sets and finetuning the model on a downstream task of a single pair also results in a huge performance boost in both low- and high-resource scenarios. Our attentive analysis of evaluation criteria for MT models in Turkic languages also points to the necessity for further research in this direction. We release the corpus splits, test sets as well as models to the public.
Improving Paraphrase Detection with the Adversarial Paraphrasing Task
Jun 14, 2021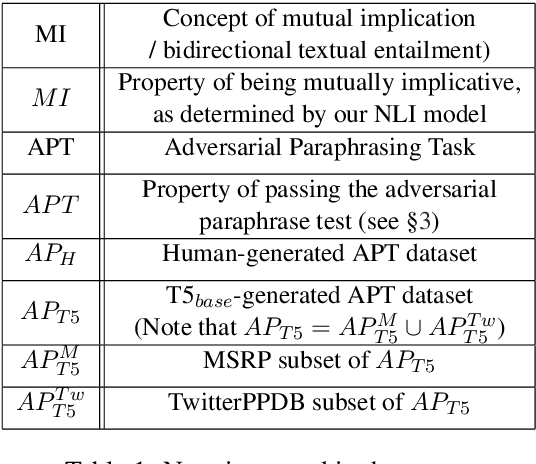
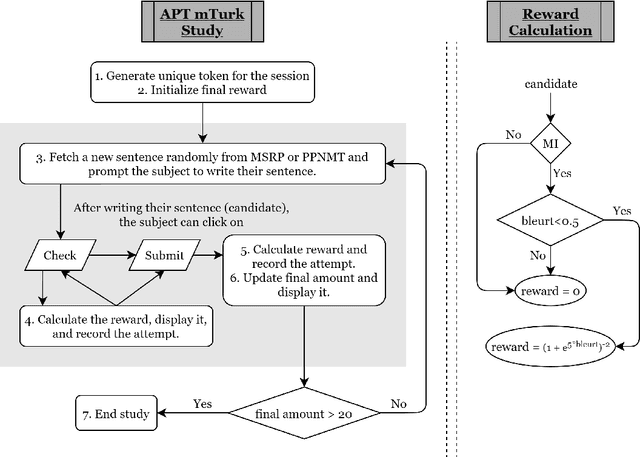
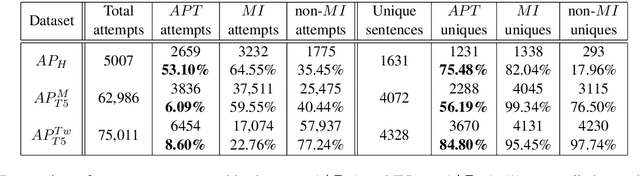
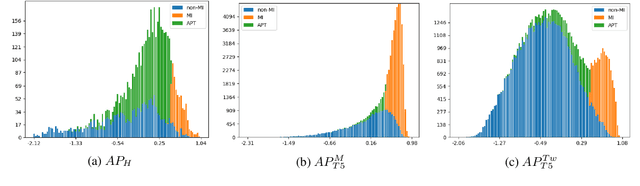
If two sentences have the same meaning, it should follow that they are equivalent in their inferential properties, i.e., each sentence should textually entail the other. However, many paraphrase datasets currently in widespread use rely on a sense of paraphrase based on word overlap and syntax. Can we teach them instead to identify paraphrases in a way that draws on the inferential properties of the sentences, and is not over-reliant on lexical and syntactic similarities of a sentence pair? We apply the adversarial paradigm to this question, and introduce a new adversarial method of dataset creation for paraphrase identification: the Adversarial Paraphrasing Task (APT), which asks participants to generate semantically equivalent (in the sense of mutually implicative) but lexically and syntactically disparate paraphrases. These sentence pairs can then be used both to test paraphrase identification models (which get barely random accuracy) and then improve their performance. To accelerate dataset generation, we explore automation of APT using T5, and show that the resulting dataset also improves accuracy. We discuss implications for paraphrase detection and release our dataset in the hope of making paraphrase detection models better able to detect sentence-level meaning equivalence.
Can Transformer Language Models Predict Psychometric Properties?
Jun 12, 2021
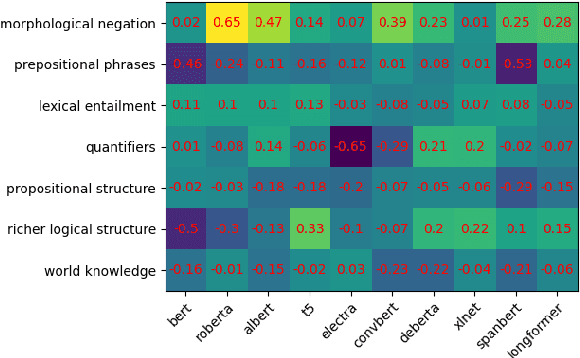

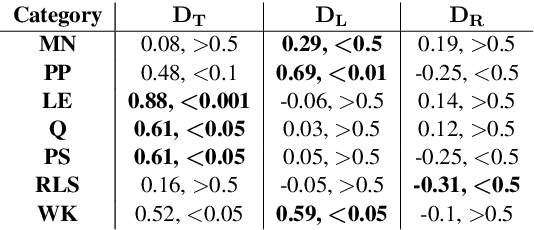
Transformer-based language models (LMs) continue to advance state-of-the-art performance on NLP benchmark tasks, including tasks designed to mimic human-inspired "commonsense" competencies. To better understand the degree to which LMs can be said to have certain linguistic reasoning skills, researchers are beginning to adapt the tools and concepts of the field of psychometrics. But to what extent can the benefits flow in the other direction? I.e., can LMs be of use in predicting what the psychometric properties of test items will be when those items are given to human participants? We gather responses from numerous human participants and LMs (transformer and non-transformer-based) on a broad diagnostic test of linguistic competencies. We then use the responses to calculate standard psychometric properties of the items in the diagnostic test, using the human responses and the LM responses separately. We then determine how well these two sets of predictions match. We find cases in which transformer-based LMs predict psychometric properties consistently well in certain categories but consistently poorly in others, thus providing new insights into fundamental similarities and differences between human and LM reasoning.