 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Paraphrase Detection with the Adversarial Paraphrasing Task
Paper and Code
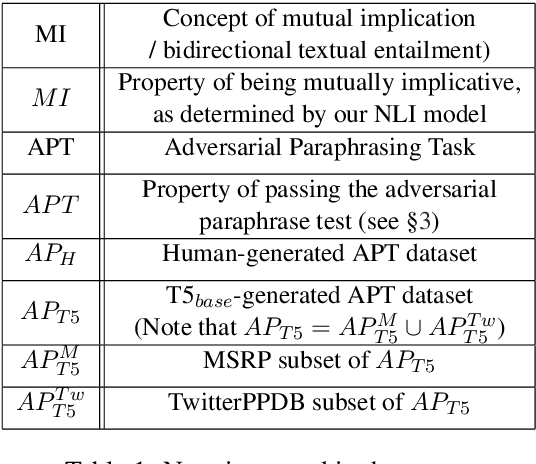
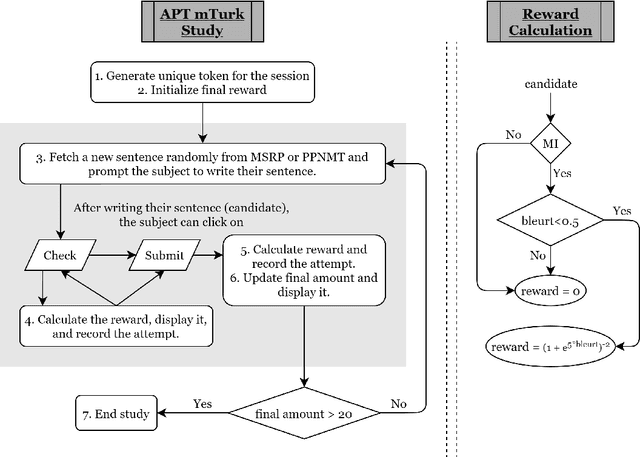
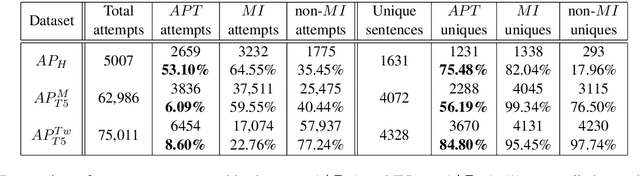
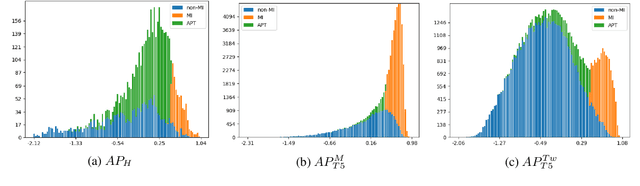
If two sentences have the same meaning, it should follow that they are equivalent in their inferential properties, i.e., each sentence should textually entail the other. However, many paraphrase datasets currently in widespread use rely on a sense of paraphrase based on word overlap and syntax. Can we teach them instead to identify paraphrases in a way that draws on the inferential properties of the sentences, and is not over-reliant on lexical and syntactic similarities of a sentence pair? We apply the adversarial paradigm to this question, and introduce a new adversarial method of dataset creation for paraphrase identification: the Adversarial Paraphrasing Task (APT), which asks participants to generate semantically equivalent (in the sense of mutually implicative) but lexically and syntactically disparate paraphrases. These sentence pairs can then be used both to test paraphrase identification models (which get barely random accuracy) and then improve their performance. To accelerate dataset generation, we explore automation of APT using T5, and show that the resulting dataset also improves accuracy. We discuss implications for paraphrase detection and release our dataset in the hope of making paraphrase detection models better able to detect sentence-level meaning equivalence.