 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Preference Optimization
May 20, 2025



While Large Language Models (LLMs) have demonstrated impressive performance across natural language generation tasks, their ability to generate truly creative content-characterized by novelty, diversity, surprise, and quality-remains limited. Existing methods for enhancing LLM creativity often focus narrowly on diversity or specific tasks, failing to address creativity's multifaceted nature in a generalizable way. In this work, we propose Creative Preference Optimization (CrPO), a novel alignment method that injects signals from multiple creativity dimensions into the preference optimization objective in a modular fashion. We train and evaluate creativity-augmented versions of several models using CrPO and MuCE, a new large-scale human preference dataset spanning over 200,000 human-generated responses and ratings from more than 30 psychological creativity assessments. Our models outperform strong baselines, including GPT-4o, on both automated and human evaluations, producing more novel, diverse, and surprising generations while maintaining high output quality. Additional evaluations on NoveltyBench further confirm the generalizability of our approach. Together, our results demonstrate that directly optimizing for creativity within preference frameworks is a promising direction for advancing the creative capabilities of LLMs without compromising output quality.
How do Humans and Language Models Reason About Creativity? A Comparative Analysis
Feb 05, 2025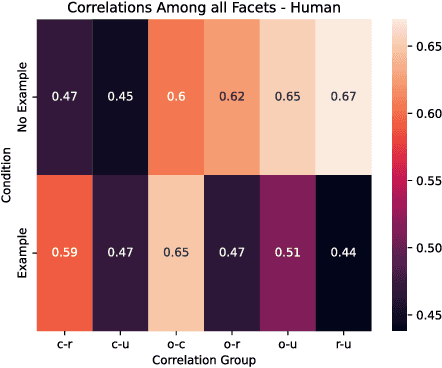
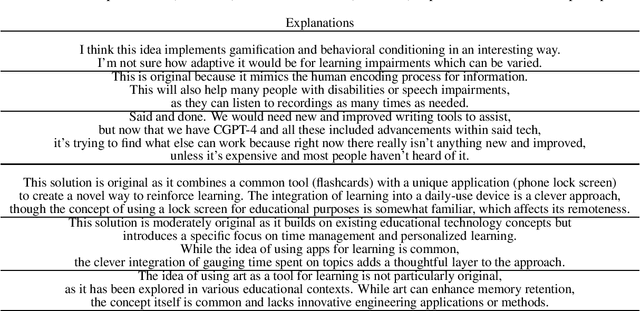
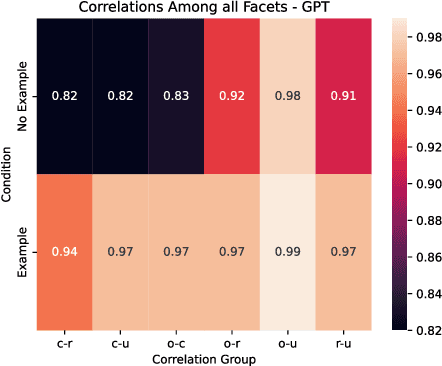
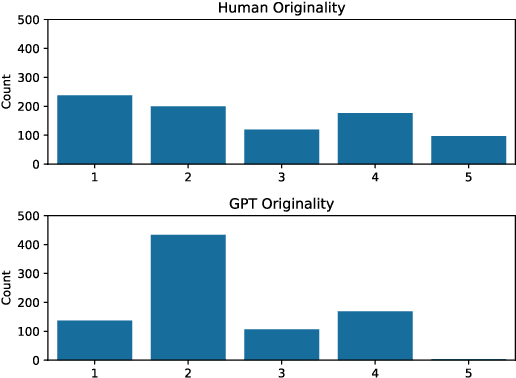
Creativity assessment in science and engineering is increasingly based on both human and AI judgment, but the cognitive processes and biases behind these evaluations remain poorly understood. We conducted two experiments examining how including example solutions with ratings impact creativity evaluation, using a finegrained annotation protocol where raters were tasked with explaining their originality scores and rating for the facets of remoteness (whether the response is "far" from everyday ideas), uncommonness (whether the response is rare), and cleverness. In Study 1, we analyzed creativity ratings from 72 experts with formal science or engineering training, comparing those who received example solutions with ratings (example) to those who did not (no example). Computational text analysis revealed that, compared to experts with examples, no-example experts used more comparative language (e.g., "better/worse") and emphasized solution uncommonness, suggesting they may have relied more on memory retrieval for comparisons. In Study 2, parallel analyses with state-of-the-art LLMs revealed that models prioritized uncommonness and remoteness of ideas when rating originality, suggesting an evaluative process rooted around the semantic similarity of ideas. In the example condition, while LLM accuracy in predicting the true originality scores improved, the correlations of remoteness, uncommonness, and cleverness with originality also increased substantially - to upwards of 0.99 - suggesting a homogenization in the LLMs evaluation of the individual facets. These findings highlight important implications for how humans and AI reason about creativity and suggest diverging preferences for what different populations prioritize when rating.
The creative psychometric item generator: a framework for item generation and validation using large language models
Aug 30, 2024Increasingly, large language models (LLMs) are being used to automate workplace processes requiring a high degree of creativity. While much prior work has examined the creativity of LLMs, there has been little research on whether they can generate valid creativity assessments for humans despite the increasingly central role of creativity in modern economies. We develop a psychometrically inspired framework for creating test items (questions) for a classic free-response creativity test: the creative problem-solving (CPS) task. Our framework, the creative psychometric item generator (CPIG), uses a mixture of LLM-based item generators and evaluators to iteratively develop new prompts for writing CPS items, such that items from later iterations will elicit more creative responses from test takers. We find strong empirical evidence that CPIG generates valid and reliable items and that this effect is not attributable to known biases in the evaluation process. Our findings have implications for employing LLMs to automatically generate valid and reliable creativity tests for humans and AI.
No Strong Feelings One Way or Another: Re-operationalizing Neutrality in Natural Language Inference
Jun 16, 2023Natural Language Inference (NLI) has been a cornerstone task in evaluating language models' inferential reasoning capabilities. However, the standard three-way classification scheme used in NLI has well-known shortcomings in evaluating models' ability to capture the nuances of natural human reasoning. In this paper, we argue that the operationalization of the neutral label in current NLI datasets has low validity, is interpreted inconsistently, and that at least one important sense of neutrality is often ignored. We uncover the detrimental impact of these shortcomings, which in some cases leads to annotation datasets that actually decrease performance on downstream tasks. We compare approaches of handling annotator disagreement and identify flaws in a recent NLI dataset that designs an annotator study based on a problematic operationalization. Our findings highlight the need for a more refined evaluation framework for NLI, and we hope to spark further discussion and action in the NLP community.
Predicting Human Psychometric Properties Using Computational Language Models
May 12, 2022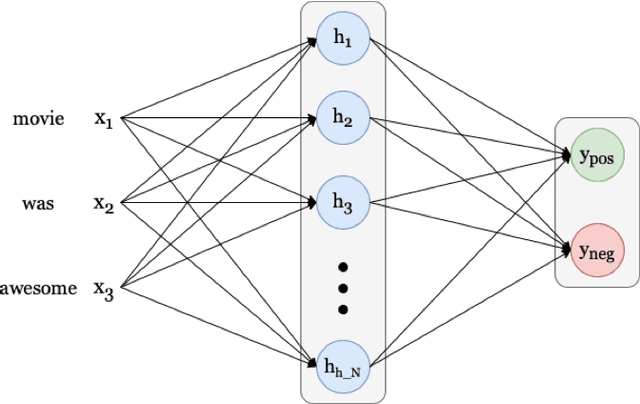
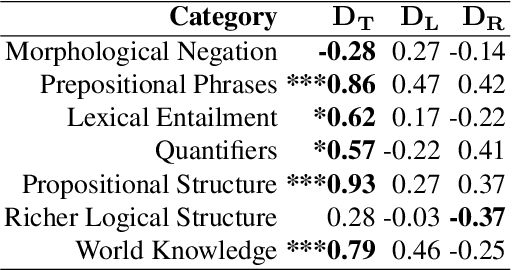
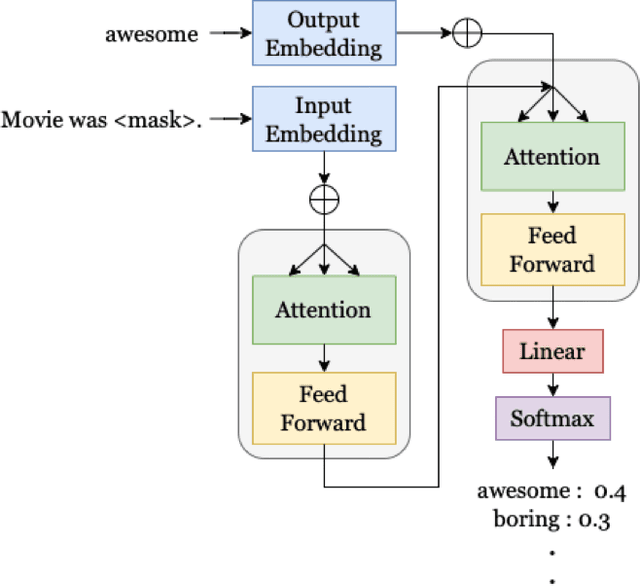
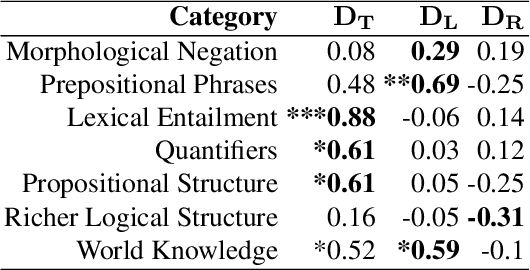
Transformer-based language models (LMs) continue to achieve state-of-the-art performance on natural language processing (NLP) benchmarks, including tasks designed to mimic human-inspired "commonsense" competencies. To better understand the degree to which LMs can be said to have certain linguistic reasoning skills, researchers are beginning to adapt the tools and concepts from psychometrics. But to what extent can benefits flow in the other direction? In other words, can LMs be of use in predicting the psychometric properties of test items, when those items are given to human participants? If so, the benefit for psychometric practitioners is enormous, as it can reduce the need for multiple rounds of empirical testing. We gather responses from numerous human participants and LMs (transformer- and non-transformer-based) on a broad diagnostic test of linguistic competencies. We then use the human responses to calculate standard psychometric properties of the items in the diagnostic test, using the human responses and the LM responses separately. We then determine how well these two sets of predictions correlate. We find that transformer-based LMs predict the human psychometric data consistently well across most categories, suggesting that they can be used to gather human-like psychometric data without the need for extensive human trials.
Developmental Negation Processing in Transformer Language Models
Apr 29, 2022
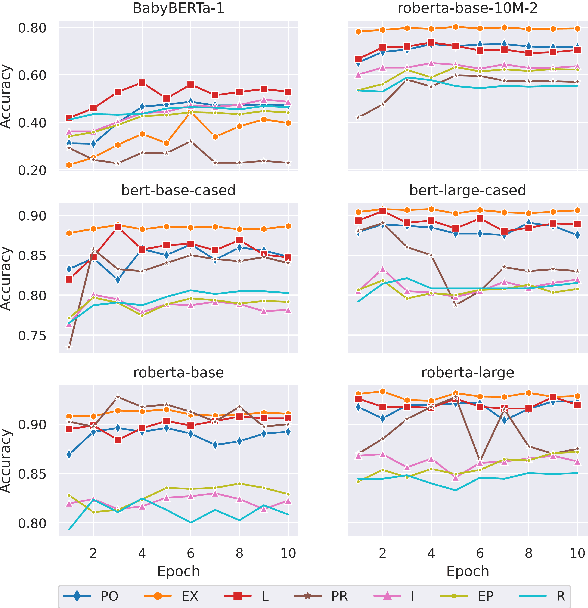

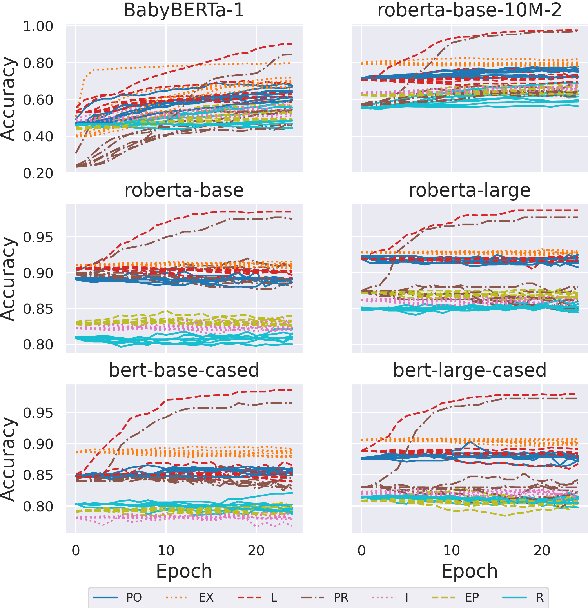
Reasoning using negation is known to be difficult for transformer-based language models. While previous studies have used the tools of psycholinguistics to probe a transformer's ability to reason over negation, none have focused on the types of negation studied in developmental psychology. We explore how well transformers can process such categories of negation, by framing the problem as a natural language inference (NLI) task. We curate a set of diagnostic questions for our target categories from popular NLI datasets and evaluate how well a suite of models reason over them. We find that models perform consistently better only on certain categories, suggesting clear distinctions in how they are processed.
A Large-Scale Study of Machine Translation in the Turkic Languages
Sep 09, 2021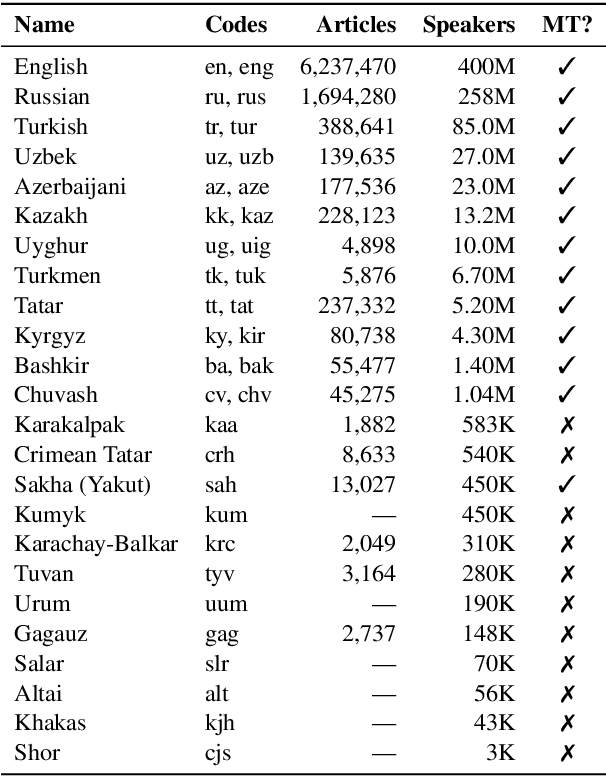
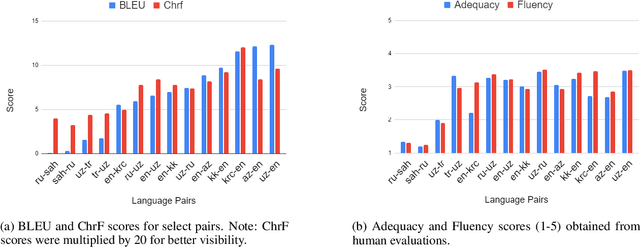
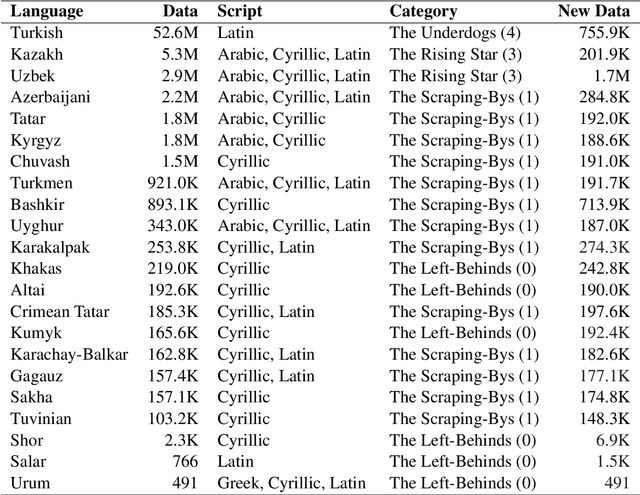

Recent advances in neural machine translation (NMT) have pushed the quality of machine translation systems to the point where they are becoming widely adopted to build competitive systems. However, there is still a large number of languages that are yet to reap the benefits of NMT. In this paper, we provide the first large-scale case study of the practical application of MT in the Turkic language family in order to realize the gains of NMT for Turkic languages under high-resource to extremely low-resource scenarios. In addition to presenting an extensive analysis that identifies the bottlenecks towards building competitive systems to ameliorate data scarcity, our study has several key contributions, including, i) a large parallel corpus covering 22 Turkic languages consisting of common public datasets in combination with new datasets of approximately 2 million parallel sentences, ii) bilingual baselines for 26 language pairs, iii) novel high-quality test sets in three different translation domains and iv) human evaluation scores. All models, scripts, and data will be released to the public.
Can Transformer Language Models Predict Psychometric Properties?
Jun 12, 2021
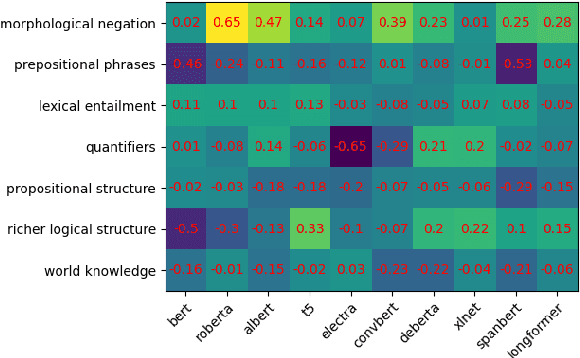

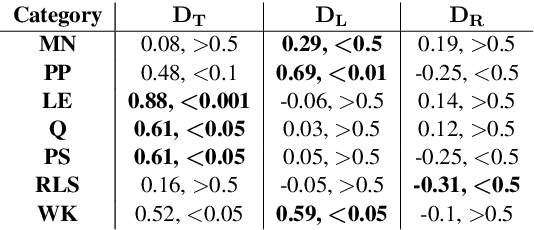
Transformer-based language models (LMs) continue to advance state-of-the-art performance on NLP benchmark tasks, including tasks designed to mimic human-inspired "commonsense" competencies. To better understand the degree to which LMs can be said to have certain linguistic reasoning skills, researchers are beginning to adapt the tools and concepts of the field of psychometrics. But to what extent can the benefits flow in the other direction? I.e., can LMs be of use in predicting what the psychometric properties of test items will be when those items are given to human participants? We gather responses from numerous human participants and LMs (transformer and non-transformer-based) on a broad diagnostic test of linguistic competencies. We then use the responses to calculate standard psychometric properties of the items in the diagnostic test, using the human responses and the LM responses separately. We then determine how well these two sets of predictions match. We find cases in which transformer-based LMs predict psychometric properties consistently well in certain categories but consistently poorly in others, thus providing new insights into fundamental similarities and differences between human and LM reasoning.