 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Approaches for our Participation to the n2c2 Challenge on Cohort Selection for Clinical Trials
Mar 19, 2019

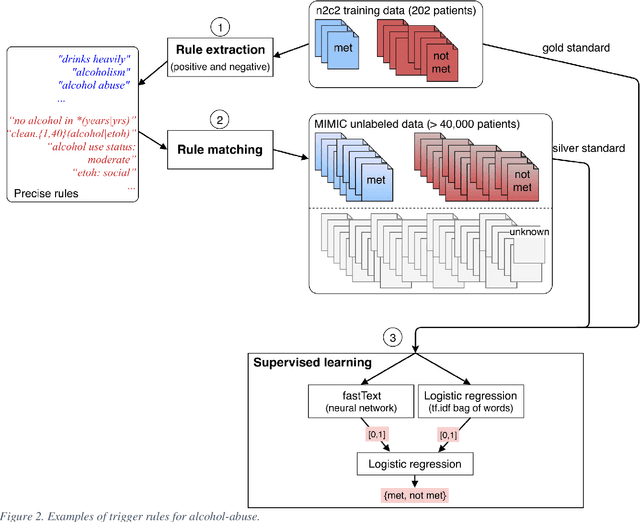
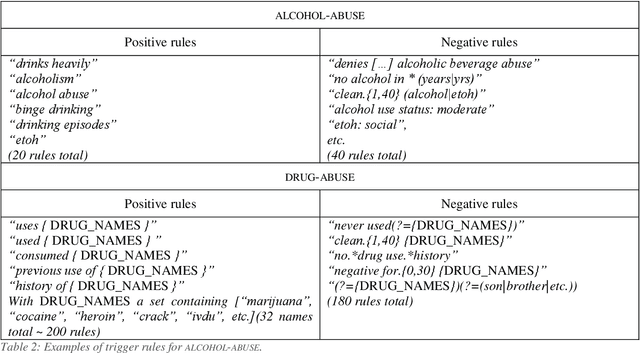
Objective: Natural language processing can help minimize human intervention in identifying patients meeting eligibility criteria for clinical trials, but there is still a long way to go to obtain a general and systematic approach that is useful for researchers. We describe two methods taking a step in this direction and present their results obtained during the n2c2 challenge on cohort selection for clinical trials. Materials and Methods: The first method is a weakly supervised method using an unlabeled corpus (MIMIC) to build a silver standard, by producing semi-automatically a small and very precise set of rules to detect some samples of positive and negative patients. This silver standard is then used to train a traditional supervised model. The second method is a terminology-based approach where a medical expert selects the appropriate concepts, and a procedure is defined to search the terms and check the structural or temporal constraints. Results: On the n2c2 dataset containing annotated data about 13 selection criteria on 288 patients, we obtained an overall F1-measure of 0.8969, which is the third best result out of 45 participant teams, with no statistically significant difference with the best-ranked team. Discussion: Both approaches obtained very encouraging results and apply to different types of criteria. The weakly supervised method requires explicit descriptions of positive and negative examples in some reports. The terminology-based method is very efficient when medical concepts carry most of the relevant information. Conclusion: It is unlikely that much more annotated data will be soon available for the task of identifying a wide range of patient phenotypes. One must focus on weakly or non-supervised learning methods using both structured and unstructured data and relying on a comprehensive representation of the patients.
A semi-automatic semantic method for mapping SNOMED CT concepts to VCM Icons
Dec 03, 2013
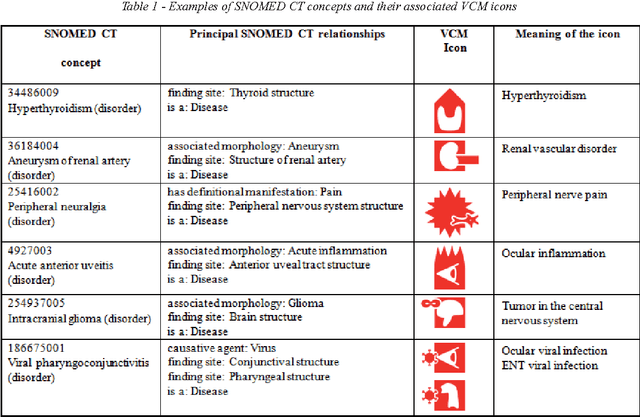
VCM (Visualization of Concept in Medicine) is an iconic language for representing key medical concepts by icons. However, the use of this language with reference terminologies, such as SNOMED CT, will require the mapping of its icons to the terms of these terminologies. Here, we present and evaluate a semi-automatic semantic method for the mapping of SNOMED CT concepts to VCM icons. Both SNOMED CT and VCM are compositional in nature; SNOMED CT is expressed in description logic and VCM semantics are formalized in an OWL ontology. The proposed method involves the manual mapping of a limited number of underlying concepts from the VCM ontology, followed by automatic generation of the rest of the mapping. We applied this method to the clinical findings of the SNOMED CT CORE subset, and 100 randomly-selected mappings were evaluated by three experts. The results obtained were promising, with 82 of the SNOMED CT concepts correctly linked to VCM icons according to the experts. Most of the errors were easy to fix.
Analyse et structuration automatique des guides de bonnes pratiques cliniques : essai d'évaluation
Dec 16, 2008
Health Practice Guideliens are supposed to unify practices and propose recommendations to physicians. This paper describes GemFrame, a system capable of semi-automatically filling an XML template from free texts in the clinical domain. The XML template includes semantic information not explicitly encoded in the text (pairs of conditions and ac-tions/recommendations). Therefore, there is a need to compute the exact scope of condi-tions over text sequences expressing the re-quired actions. We present a system developped for this task. We show that it yields good performance when applied to the analysis of French practice guidelines. We conclude with a precise evaluation of the tool.