 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Difficulties of Attention Factorization through Shared Memory
Mar 31, 2024



Transformers have revolutionized deep learning in numerous fields, including natural language processing, computer vision, and audio processing. Their strength lies in their attention mechanism, which allows for the discovering of complex input relationships. However, this mechanism's quadratic time and memory complexity pose challenges for larger inputs. Researchers are now investigating models like Linear Unified Nested Attention (Luna) or Memory Augmented Transformer, which leverage external learnable memory to either reduce the attention computation complexity down to linear, or to propagate information between chunks in chunk-wise processing. Our findings challenge the conventional thinking on these models, revealing that interfacing with the memory directly through an attention operation is suboptimal, and that the performance may be considerably improved by filtering the input signal before communicating with memory.
Linear Self-Attention Approximation via Trainable Feedforward Kernel
Nov 08, 2022In pursuit of faster computation, Efficient Transformers demonstrate an impressive variety of approaches -- models attaining sub-quadratic attention complexity can utilize a notion of sparsity or a low-rank approximation of inputs to reduce the number of attended keys; other ways to reduce complexity include locality-sensitive hashing, key pooling, additional memory to store information in compacted or hybridization with other architectures, such as CNN. Often based on a strong mathematical basis, kernelized approaches allow for the approximation of attention with linear complexity while retaining high accuracy. Therefore, in the present paper, we aim to expand the idea of trainable kernel methods to approximate the self-attention mechanism of the Transformer architecture.
SimpleTron: Eliminating Softmax from Attention Computation
Dec 02, 2021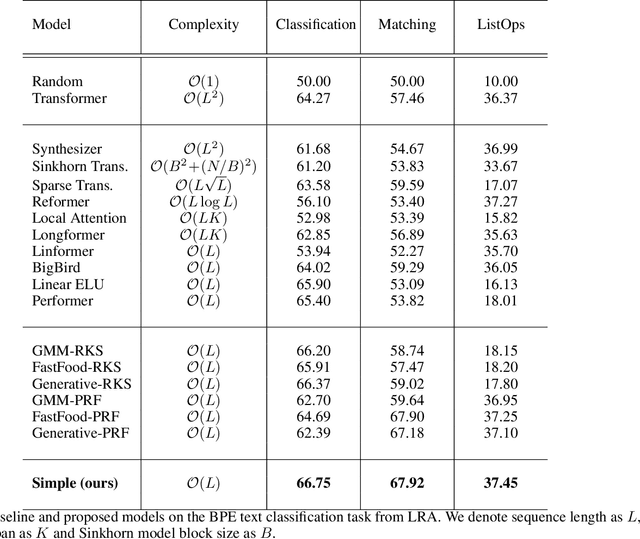



In this paper, we propose that the dot product pairwise matching attention layer, which is widely used in transformer-based models, is redundant for the model performance. Attention in its original formulation has to be rather seen as a human-level tool to explore and/or visualize relevancy scores in the sequences. Instead, we present a simple and fast alternative without any approximation that, to the best of our knowledge, outperforms existing attention approximations on several tasks from the Long-Range Arena benchmark.