 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Difficulties of Attention Factorization through Shared Memory
Mar 31, 2024



Transformers have revolutionized deep learning in numerous fields, including natural language processing, computer vision, and audio processing. Their strength lies in their attention mechanism, which allows for the discovering of complex input relationships. However, this mechanism's quadratic time and memory complexity pose challenges for larger inputs. Researchers are now investigating models like Linear Unified Nested Attention (Luna) or Memory Augmented Transformer, which leverage external learnable memory to either reduce the attention computation complexity down to linear, or to propagate information between chunks in chunk-wise processing. Our findings challenge the conventional thinking on these models, revealing that interfacing with the memory directly through an attention operation is suboptimal, and that the performance may be considerably improved by filtering the input signal before communicating with memory.
Video Scene Location Recognition with Neural Networks
Sep 21, 2023


This paper provides an insight into the possibility of scene recognition from a video sequence with a small set of repeated shooting locations (such as in television series) using artificial neural networks. The basic idea of the presented approach is to select a set of frames from each scene, transform them by a pre-trained singleimage pre-processing convolutional network, and classify the scene location with subsequent layers of the neural network. The considered networks have been tested and compared on a dataset obtained from The Big Bang Theory television series. We have investigated different neural network layers to combine individual frames, particularly AveragePooling, MaxPooling, Product, Flatten, LSTM, and Bidirectional LSTM layers. We have observed that only some of the approaches are suitable for the task at hand.
Using Artificial Neural Networks to Determine Ontologies Most Relevant to Scientific Texts
Sep 17, 2023
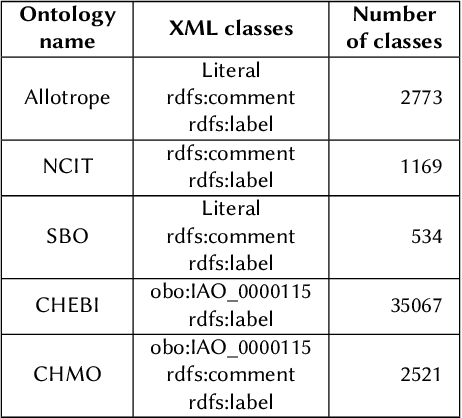
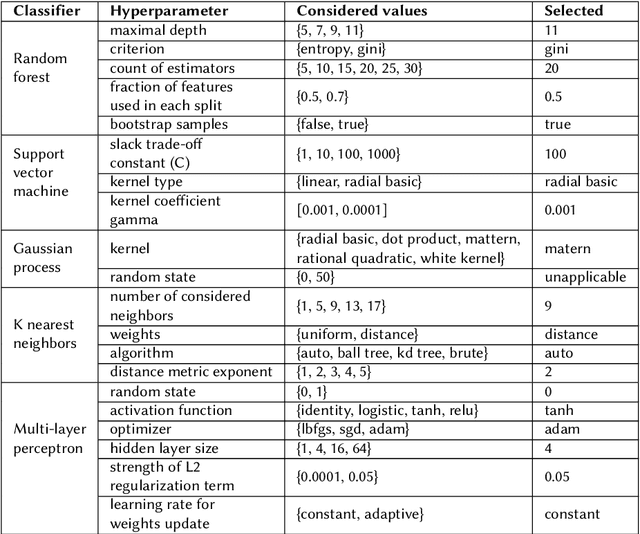
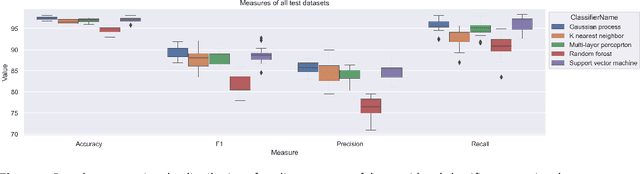
This paper provides an insight into the possibility of how to find ontologies most relevant to scientific texts using artificial neural networks. The basic idea of the presented approach is to select a representative paragraph from a source text file, embed it to a vector space by a pre-trained fine-tuned transformer, and classify the embedded vector according to its relevance to a target ontology. We have considered different classifiers to categorize the output from the transformer, in particular random forest, support vector machine, multilayer perceptron, k-nearest neighbors, and Gaussian process classifiers. Their suitability has been evaluated in a use case with ontologies and scientific texts concerning catalysis research. From results we can say the worst results have random forest. The best results in this task brought support vector machine classifier.
Two Gaussian Approaches to Black-Box Optomization
Nov 28, 2014Outline of several strategies for using Gaussian processes as surrogate models for the covariance matrix adaptation evolution strategy (CMA-ES).