 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Artificial Neural Networks to Determine Ontologies Most Relevant to Scientific Texts
Paper and Code
Sep 17, 2023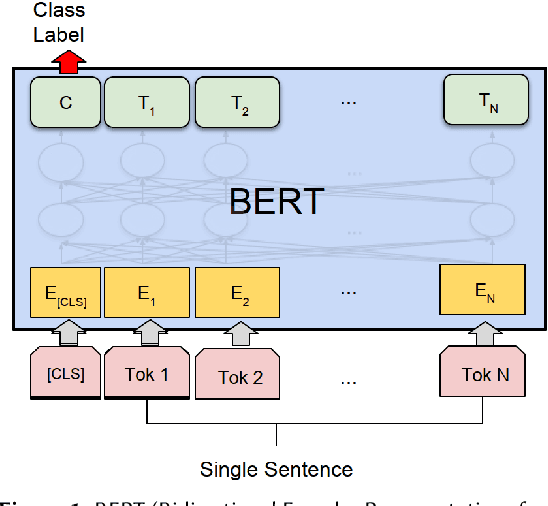
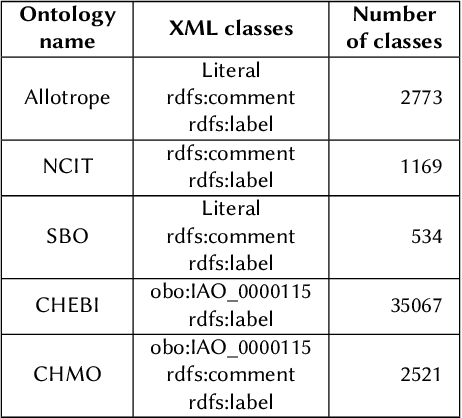
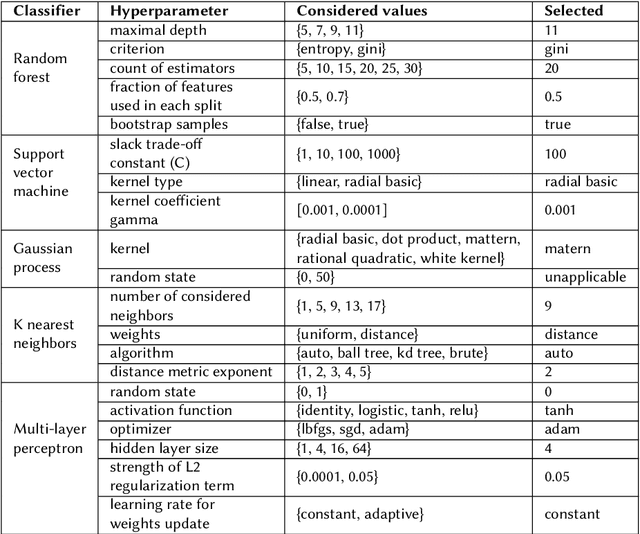
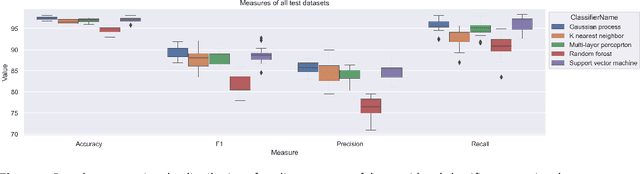
This paper provides an insight into the possibility of how to find ontologies most relevant to scientific texts using artificial neural networks. The basic idea of the presented approach is to select a representative paragraph from a source text file, embed it to a vector space by a pre-trained fine-tuned transformer, and classify the embedded vector according to its relevance to a target ontology. We have considered different classifiers to categorize the output from the transformer, in particular random forest, support vector machine, multilayer perceptron, k-nearest neighbors, and Gaussian process classifiers. Their suitability has been evaluated in a use case with ontologies and scientific texts concerning catalysis research. From results we can say the worst results have random forest. The best results in this task brought support vector machine classifier.