 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future is Sparse: Embedding Compression for Scalable Retrieval in Recommender Systems
May 16, 2025


Industry-scale recommender systems face a core challenge: representing entities with high cardinality, such as users or items, using dense embeddings that must be accessible during both training and inference. However, as embedding sizes grow, memory constraints make storage and access increasingly difficult. We describe a lightweight, learnable embedding compression technique that projects dense embeddings into a high-dimensional, sparsely activated space. Designed for retrieval tasks, our method reduces memory requirements while preserving retrieval performance, enabling scalable deployment under strict resource constraints. Our results demonstrate that leveraging sparsity is a promising approach for improving the efficiency of large-scale recommenders. We release our code at https://github.com/recombee/CompresSAE.
beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems
Sep 16, 2024



Recommender systems often use text-side information to improve their predictions, especially in cold-start or zero-shot recommendation scenarios, where traditional collaborative filtering approaches cannot be used. Many approaches to text-mining side information for recommender systems have been proposed over recent years, with sentence Transformers being the most prominent one. However, these models are trained to predict semantic similarity without utilizing interaction data with hidden patterns specific to recommender systems. In this paper, we propose beeFormer, a framework for training sentence Transformer models with interaction data. We demonstrate that our models trained with beeFormer can transfer knowledge between datasets while outperforming not only semantic similarity sentence Transformers but also traditional collaborative filtering methods. We also show that training on multiple datasets from different domains accumulates knowledge in a single model, unlocking the possibility of training universal, domain-agnostic sentence Transformer models to mine text representations for recommender systems. We release the source code, trained models, and additional details allowing replication of our experiments at https://github.com/recombee/beeformer.
Bridging Offline-Online Evaluation with a Time-dependent and Popularity Bias-free Offline Metric for Recommenders
Aug 14, 2023

The evaluation of recommendation systems is a complex task. The offline and online evaluation metrics for recommender systems are ambiguous in their true objectives. The majority of recently published papers benchmark their methods using ill-posed offline evaluation methodology that often fails to predict true online performance. Because of this, the impact that academic research has on the industry is reduced. The aim of our research is to investigate and compare the online performance of offline evaluation metrics. We show that penalizing popular items and considering the time of transactions during the evaluation significantly improves our ability to choose the best recommendation model for a live recommender system. Our results, averaged over five large-size real-world live data procured from recommenders, aim to help the academic community to understand better offline evaluation and optimization criteria that are more relevant for real applications of recommender systems.
Learning to Optimize with Dynamic Mode Decomposition
Nov 29, 2022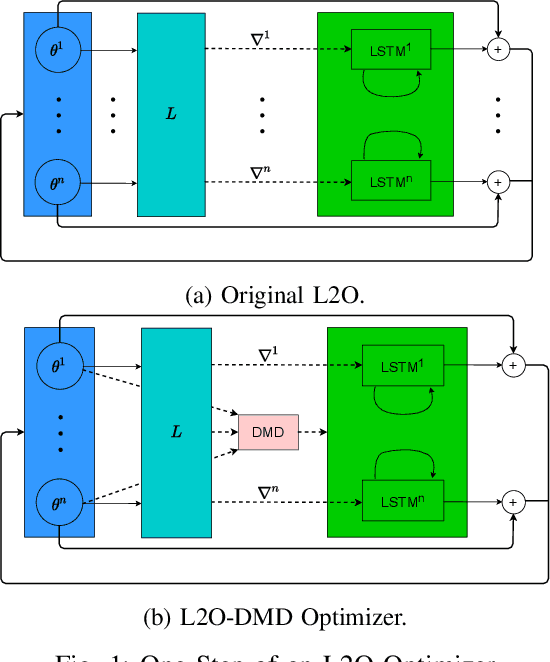
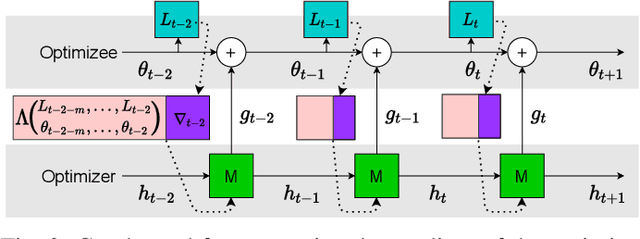
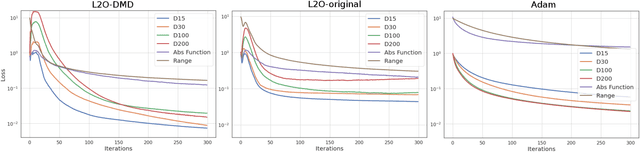
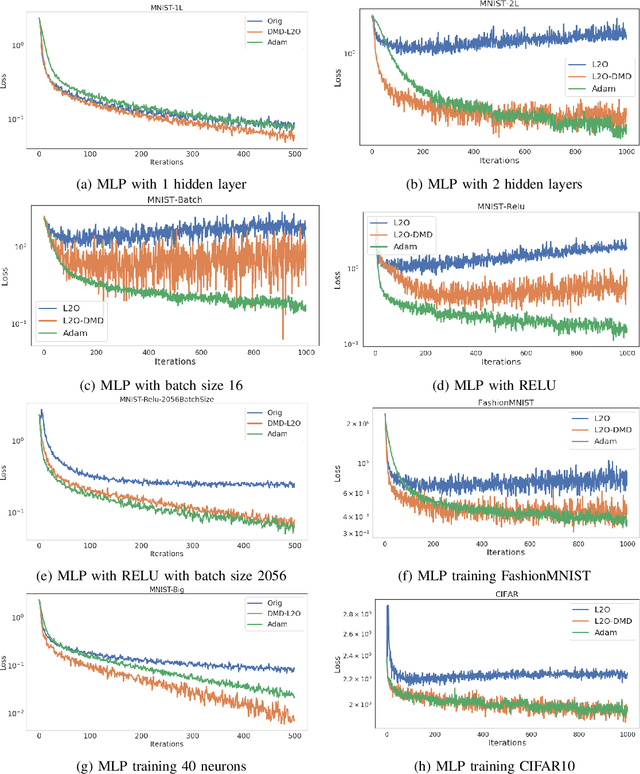
Designing faster optimization algorithms is of ever-growing interest. In recent years, learning to learn methods that learn how to optimize demonstrated very encouraging results. Current approaches usually do not effectively include the dynamics of the optimization process during training. They either omit it entirely or only implicitly assume the dynamics of an isolated parameter. In this paper, we show how to utilize the dynamic mode decomposition method for extracting informative features about optimization dynamics. By employing those features, we show that our learned optimizer generalizes much better to unseen optimization problems in short. The improved generalization is illustrated on multiple tasks where training the optimizer on one neural network generalizes to different architectures and distinct datasets.
SimpleTron: Eliminating Softmax from Attention Computation
Dec 02, 2021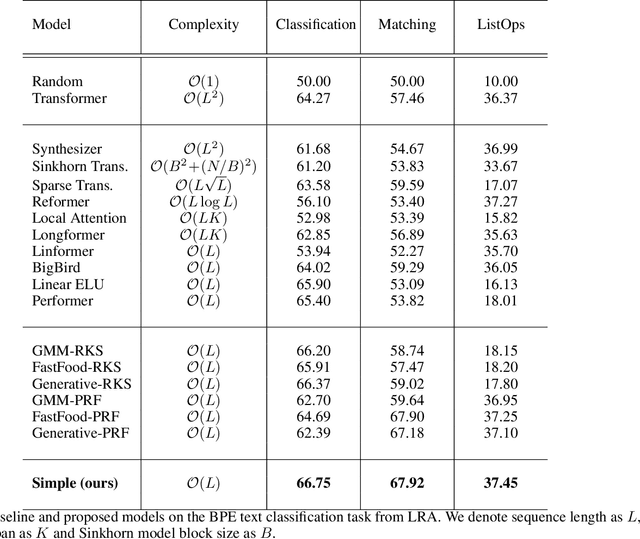



In this paper, we propose that the dot product pairwise matching attention layer, which is widely used in transformer-based models, is redundant for the model performance. Attention in its original formulation has to be rather seen as a human-level tool to explore and/or visualize relevancy scores in the sequences. Instead, we present a simple and fast alternative without any approximation that, to the best of our knowledge, outperforms existing attention approximations on several tasks from the Long-Range Arena benchmark.
Dynamic Neural Diversification: Path to Computationally Sustainable Neural Networks
Sep 20, 2021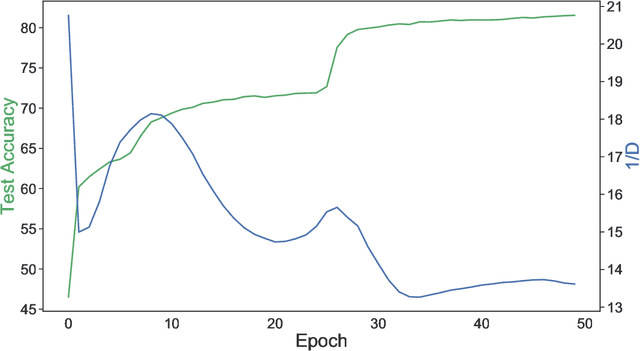
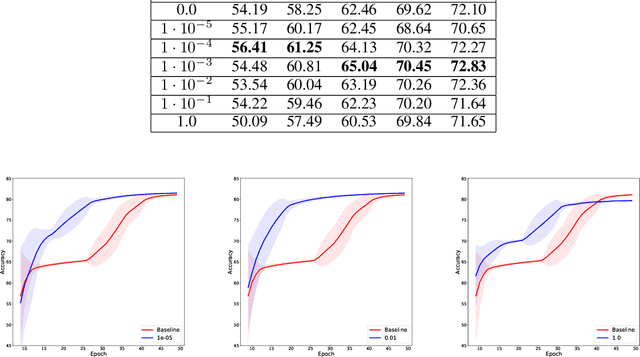
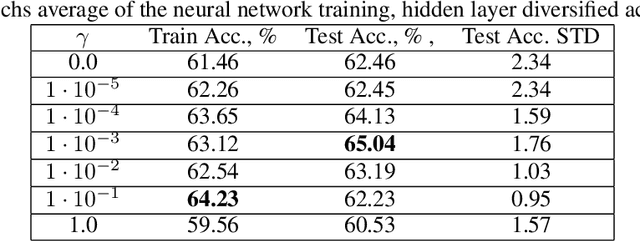
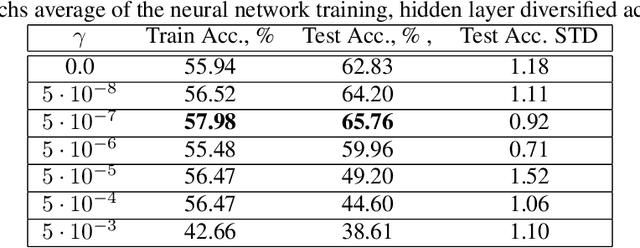
Small neural networks with a constrained number of trainable parameters, can be suitable resource-efficient candidates for many simple tasks, where now excessively large models are used. However, such models face several problems during the learning process, mainly due to the redundancy of the individual neurons, which results in sub-optimal accuracy or the need for additional training steps. Here, we explore the diversity of the neurons within the hidden layer during the learning process, and analyze how the diversity of the neurons affects predictions of the model. As following, we introduce several techniques to dynamically reinforce diversity between neurons during the training. These decorrelation techniques improve learning at early stages and occasionally help to overcome local minima faster. Additionally, we describe novel weight initialization method to obtain decorrelated, yet stochastic weight initialization for a fast and efficient neural network training. Decorrelated weight initialization in our case shows about 40% relative increase in test accuracy during the first 5 epochs.
* Accepted to ICANN 2021
Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network
Feb 11, 2021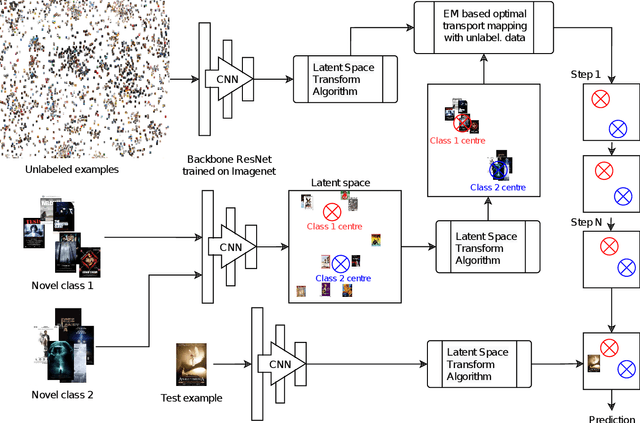
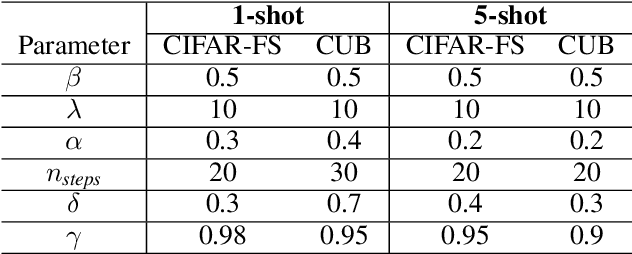
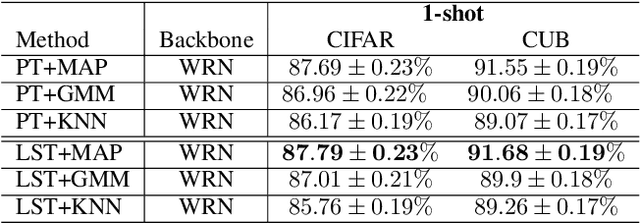
MetaDL Challenge 2020 focused on image classification tasks in few-shot settings. This paper describes second best submission in the competition. Our meta learning approach modifies the distribution of classes in a latent space produced by a backbone network for each class in order to better follow the Gaussian distribution. After this operation which we call Latent Space Transform algorithm, centers of classes are further aligned in an iterative fashion of the Expectation Maximisation algorithm to utilize information in unlabeled data that are often provided on top of few labelled instances. For this task, we utilize optimal transport mapping using the Sinkhorn algorithm. Our experiments show that this approach outperforms previous works as well as other variants of the algorithm, using K-Nearest Neighbour algorithm, Gaussian Mixture Models, etc.
Deep Variational Autoencoder with Shallow Parallel Path for Top-N Recommendation (VASP)
Feb 10, 2021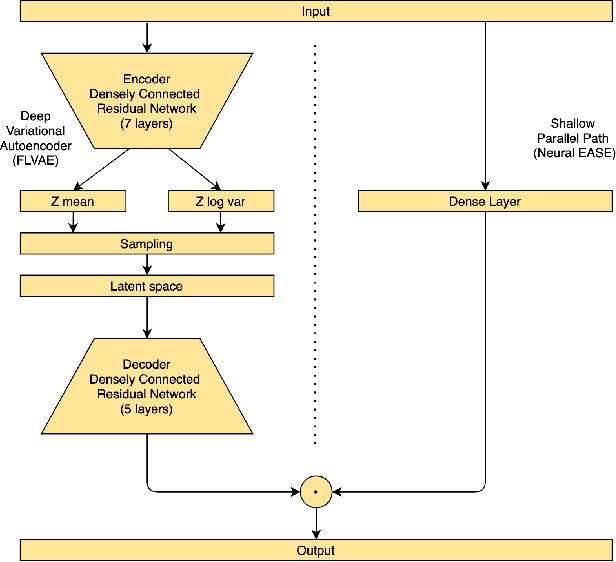

Recently introduced EASE algorithm presents a simple and elegant way, how to solve the top-N recommendation task. In this paper, we introduce Neural EASE to further improve the performance of this algorithm by incorporating techniques for training modern neural networks. Also, there is a growing interest in the recsys community to utilize variational autoencoders (VAE) for this task. We introduce deep autoencoder FLVAE benefiting from multiple non-linear layers without an information bottleneck while not overfitting towards the identity. We show how to learn FLVAE in parallel with Neural EASE and achieve the state of the art performance on the MovieLens 20M dataset and competitive results on the Netflix Prize dataset.