 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Context-Based Low-Light Image Enhancement via Neural Implicit Representations
Jul 17, 2024
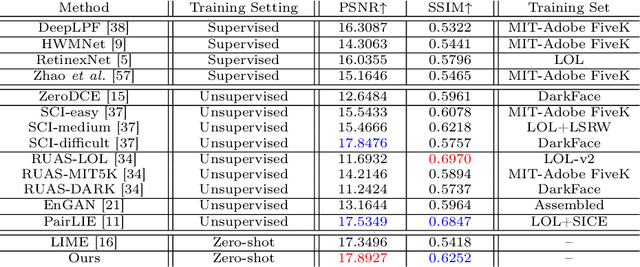
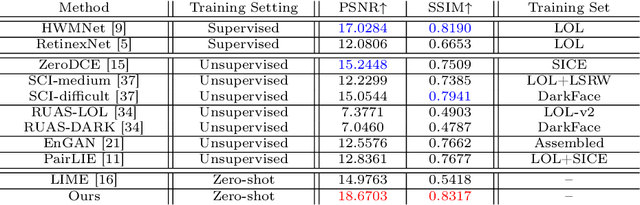
Current deep learning-based low-light image enhancement methods often struggle with high-resolution images, and fail to meet the practical demands of visual perception across diverse and unseen scenarios. In this paper, we introduce a novel approach termed CoLIE, which redefines the enhancement process through mapping the 2D coordinates of an underexposed image to its illumination component, conditioned on local context. We propose a reconstruction of enhanced-light images within the HSV space utilizing an implicit neural function combined with an embedded guided filter, thereby significantly reducing computational overhead. Moreover, we introduce a single image-based training loss function to enhance the model's adaptability to various scenes, further enhancing its practical applicability. Through rigorous evaluations, we analyze the properties of our proposed framework, demonstrating its superiority in both image quality and scene adaptability. Furthermore, our evaluation extends to applications in downstream tasks within low-light scenarios, underscoring the practical utility of CoLIE. The source code is available at https://github.com/ctom2/colie.
Leveraging Classic Deconvolution and Feature Extraction in Zero-Shot Image Restoration
Oct 03, 2023Non-blind deconvolution aims to restore a sharp image from its blurred counterpart given an obtained kernel. Existing deep neural architectures are often built based on large datasets of sharp ground truth images and trained with supervision. Sharp, high quality ground truth images, however, are not always available, especially for biomedical applications. This severely hampers the applicability of current approaches in practice. In this paper, we propose a novel non-blind deconvolution method that leverages the power of deep learning and classic iterative deconvolution algorithms. Our approach combines a pre-trained network to extract deep features from the input image with iterative Richardson-Lucy deconvolution steps. Subsequently, a zero-shot optimisation process is employed to integrate the deconvolved features, resulting in a high-quality reconstructed image. By performing the preliminary reconstruction with the classic iterative deconvolution method, we can effectively utilise a smaller network to produce the final image, thus accelerating the reconstruction whilst reducing the demand for valuable computational resources. Our method demonstrates significant improvements in various real-world applications non-blind deconvolution tasks.
LUCYD: A Feature-Driven Richardson-Lucy Deconvolution Network
Jul 16, 2023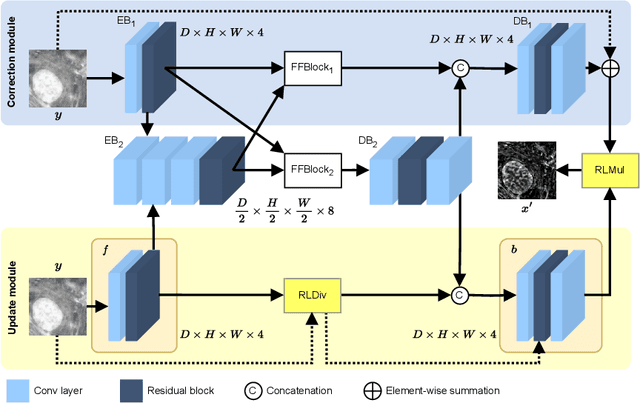
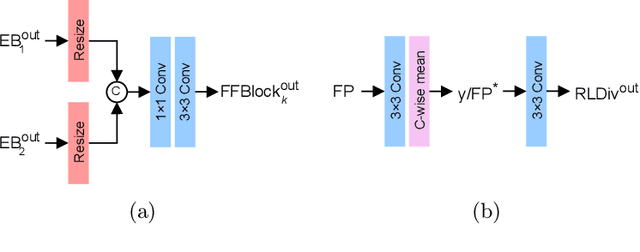
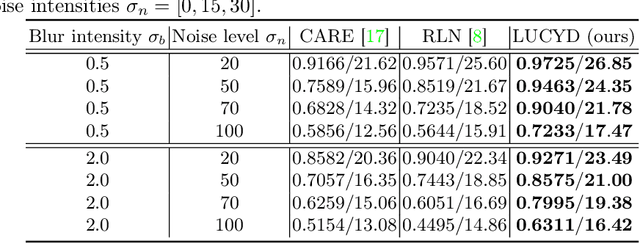
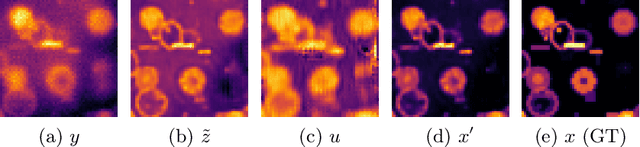
The process of acquiring microscopic images in life sciences often results in image degradation and corruption, characterised by the presence of noise and blur, which poses significant challenges in accurately analysing and interpreting the obtained data. This paper proposes LUCYD, a novel method for the restoration of volumetric microscopy images that combines the Richardson-Lucy deconvolution formula and the fusion of deep features obtained by a fully convolutional network. By integrating the image formation process into a feature-driven restoration model, the proposed approach aims to enhance the quality of the restored images whilst reducing computational costs and maintaining a high degree of interpretability. Our results demonstrate that LUCYD outperforms the state-of-the-art methods in both synthetic and real microscopy images, achieving superior performance in terms of image quality and generalisability. We show that the model can handle various microscopy modalities and different imaging conditions by evaluating it on two different microscopy datasets, including volumetric widefield and light-sheet microscopy. Our experiments indicate that LUCYD can significantly improve resolution, contrast, and overall quality of microscopy images. Therefore, it can be a valuable tool for microscopy image restoration and can facilitate further research in various microscopy applications. We made the source code for the model accessible under https://github.com/ctom2/lucyd-deconvolution.
Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network
Feb 11, 2021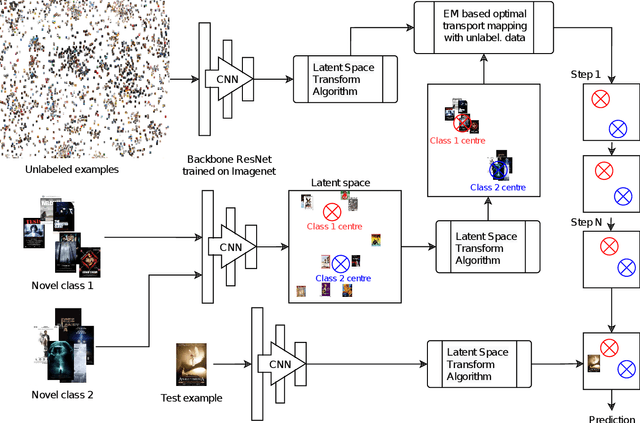
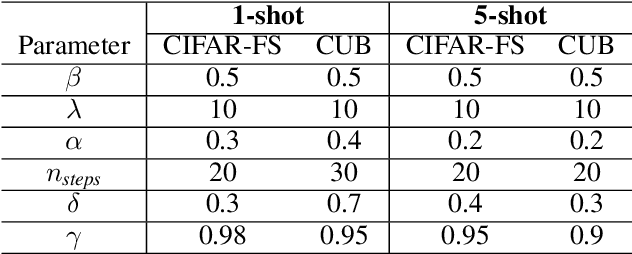
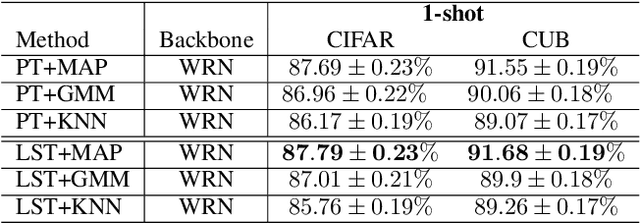
MetaDL Challenge 2020 focused on image classification tasks in few-shot settings. This paper describes second best submission in the competition. Our meta learning approach modifies the distribution of classes in a latent space produced by a backbone network for each class in order to better follow the Gaussian distribution. After this operation which we call Latent Space Transform algorithm, centers of classes are further aligned in an iterative fashion of the Expectation Maximisation algorithm to utilize information in unlabeled data that are often provided on top of few labelled instances. For this task, we utilize optimal transport mapping using the Sinkhorn algorithm. Our experiments show that this approach outperforms previous works as well as other variants of the algorithm, using K-Nearest Neighbour algorithm, Gaussian Mixture Models, etc.
Unsupervised Latent Space Translation Network
Mar 20, 2020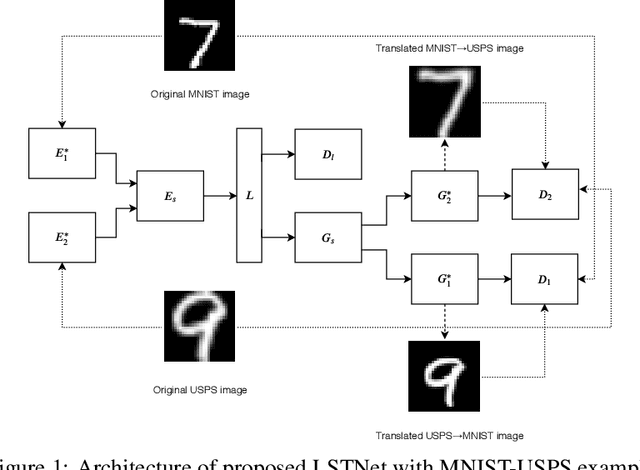
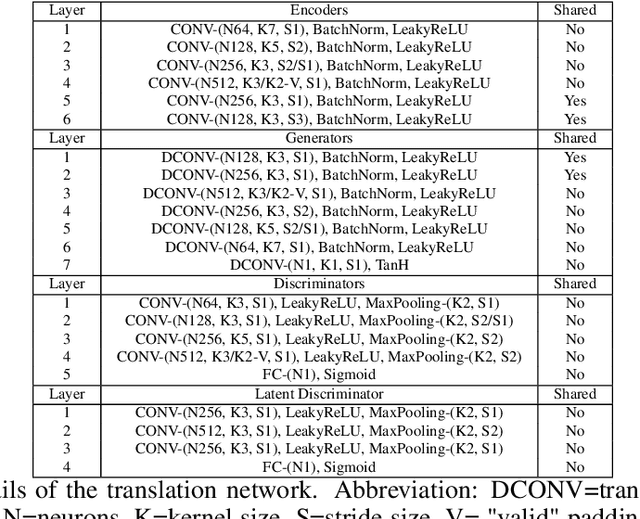
One task that is often discussed in a computer vision is the mapping of an image from one domain to a corresponding image in another domain known as image-to-image translation. Currently there are several approaches solving this task. In this paper, we present an enhancement of the UNIT framework that aids in removing its main drawbacks. More specifically, we introduce an additional adversarial discriminator on the latent representation used instead of VAE, which enforces the latent space distributions of both domains to be similar. On MNIST and USPS domain adaptation tasks, this approach greatly outperforms competing approaches.