 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Using Machine Learning to Generatively Simulate EV Charging in Urban Areas
Dec 13, 2024



This study addresses the challenge of predicting electric vehicle (EV) charging profiles in urban locations with limited data. Utilizing a neural network architecture, we aim to uncover latent charging profiles influenced by spatio-temporal factors. Our model focuses on peak power demand and daily load shapes, providing insights into charging behavior. Our results indicate significant impacts from the type of Basic Administrative Units on predicted load curves, which contributes to the understanding and optimization of EV charging infrastructure in urban settings and allows Distribution System Operators (DSO) to more efficiently plan EV charging infrastructure expansion.
Dynamic Neural Diversification: Path to Computationally Sustainable Neural Networks
Sep 20, 2021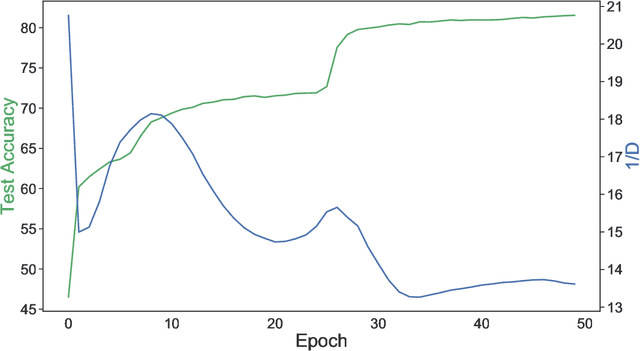
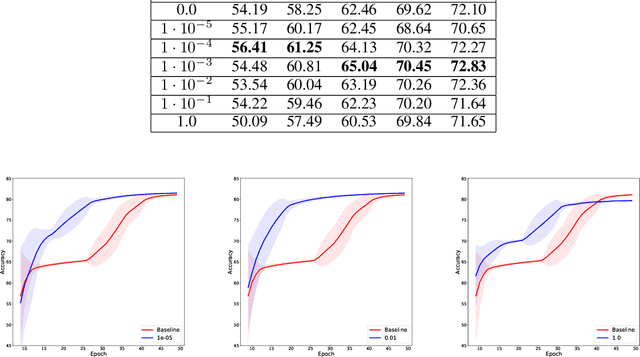
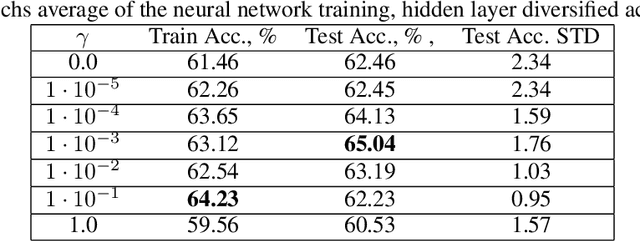
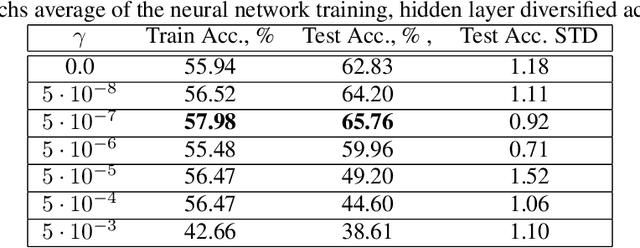
Small neural networks with a constrained number of trainable parameters, can be suitable resource-efficient candidates for many simple tasks, where now excessively large models are used. However, such models face several problems during the learning process, mainly due to the redundancy of the individual neurons, which results in sub-optimal accuracy or the need for additional training steps. Here, we explore the diversity of the neurons within the hidden layer during the learning process, and analyze how the diversity of the neurons affects predictions of the model. As following, we introduce several techniques to dynamically reinforce diversity between neurons during the training. These decorrelation techniques improve learning at early stages and occasionally help to overcome local minima faster. Additionally, we describe novel weight initialization method to obtain decorrelated, yet stochastic weight initialization for a fast and efficient neural network training. Decorrelated weight initialization in our case shows about 40% relative increase in test accuracy during the first 5 epochs.
* Accepted to ICANN 2021
Image Inpainting Using Wasserstein Generative Adversarial Imputation Network
Jun 23, 2021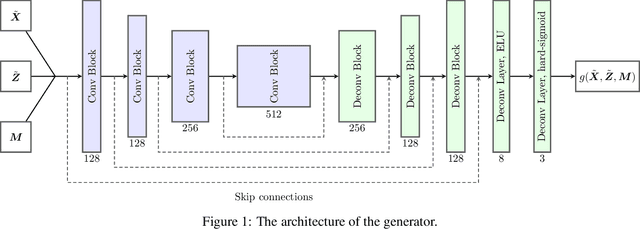
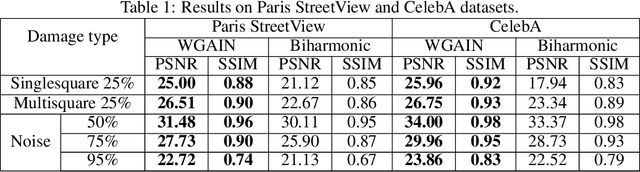

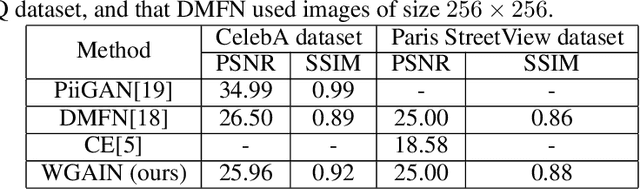
Image inpainting is one of the important tasks in computer vision which focuses on the reconstruction of missing regions in an image. The aim of this paper is to introduce an image inpainting model based on Wasserstein Generative Adversarial Imputation Network. The generator network of the model uses building blocks of convolutional layers with different dilation rates, together with skip connections that help the model reproduce fine details of the output. This combination yields a universal imputation model that is able to handle various scenarios of missingness with sufficient quality. To show this experimentally, the model is simultaneously trained to deal with three scenarios given by missing pixels at random, missing various smaller square regions, and one missing square placed in the center of the image. It turns out that our model achieves high-quality inpainting results on all scenarios. Performance is evaluated using peak signal-to-noise ratio and structural similarity index on two real-world benchmark datasets, CelebA faces and Paris StreetView. The results of our model are compared to biharmonic imputation and to some of the other state-of-the-art image inpainting methods.
Missing Features Reconstruction Using a Wasserstein Generative Adversarial Imputation Network
Jun 21, 2020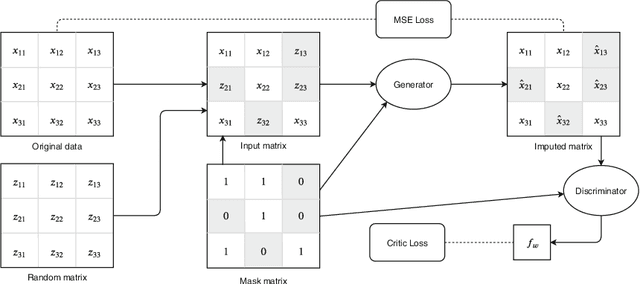
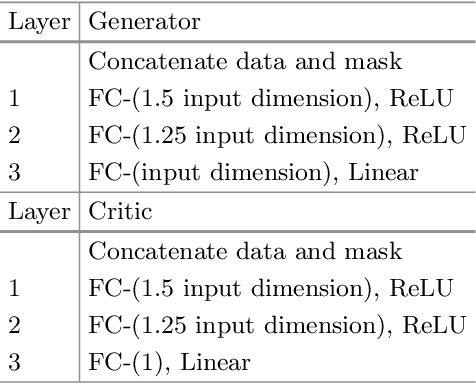
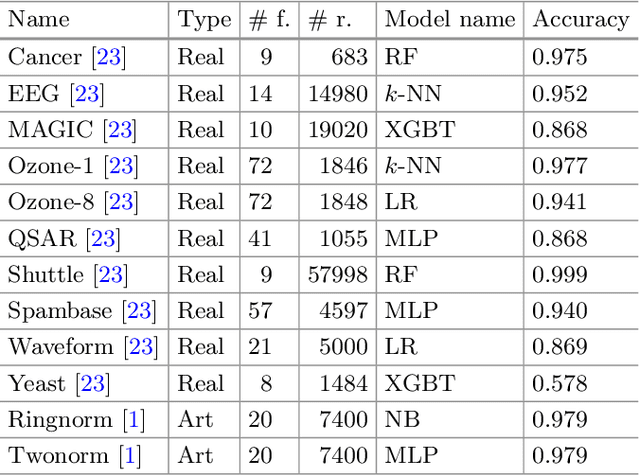
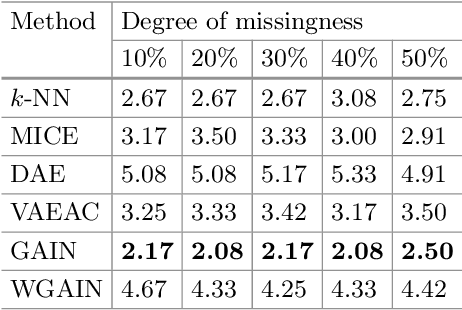
Missing data is one of the most common preprocessing problems. In this paper, we experimentally research the use of generative and non-generative models for feature reconstruction. Variational Autoencoder with Arbitrary Conditioning (VAEAC) and Generative Adversarial Imputation Network (GAIN) were researched as representatives of generative models, while the denoising autoencoder (DAE) represented non-generative models. Performance of the models is compared to traditional methods k-nearest neighbors (k-NN) and Multiple Imputation by Chained Equations (MICE). Moreover, we introduce WGAIN as the Wasserstein modification of GAIN, which turns out to be the best imputation model when the degree of missingness is less than or equal to 30%. Experiments were performed on real-world and artificial datasets with continuous features where different percentages of features, varying from 10% to 50%, were missing. Evaluation of algorithms was done by measuring the accuracy of the classification model previously trained on the uncorrupted dataset. The results show that GAIN and especially WGAIN are the best imputers regardless of the conditions. In general, they outperform or are comparative to MICE, k-NN, DAE, and VAEAC.
* Preprint of the conference paper (ICCS 2020), part of the Lecture Notes in Computer Science
Unsupervised Latent Space Translation Network
Mar 20, 2020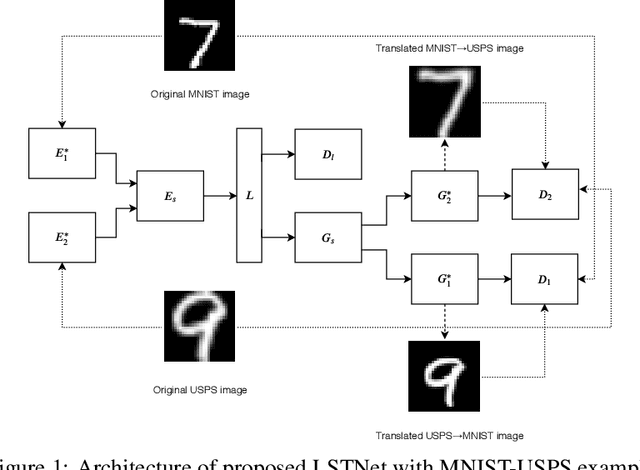
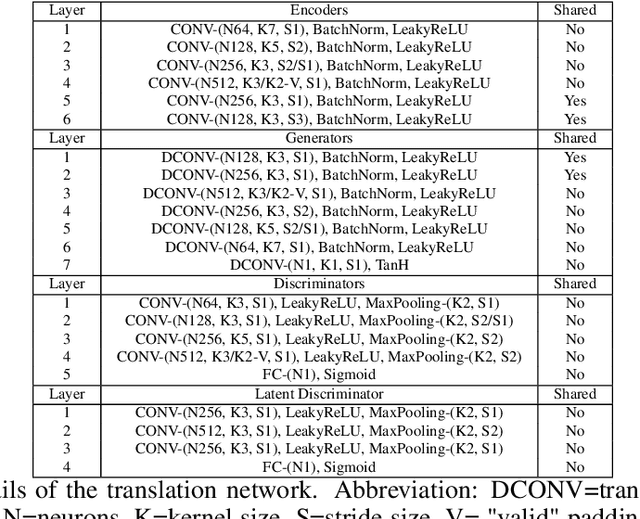
One task that is often discussed in a computer vision is the mapping of an image from one domain to a corresponding image in another domain known as image-to-image translation. Currently there are several approaches solving this task. In this paper, we present an enhancement of the UNIT framework that aids in removing its main drawbacks. More specifically, we introduce an additional adversarial discriminator on the latent representation used instead of VAE, which enforces the latent space distributions of both domains to be similar. On MNIST and USPS domain adaptation tasks, this approach greatly outperforms competing approaches.
Missing Features Reconstruction and Its Impact on Classification Accuracy
Nov 09, 2019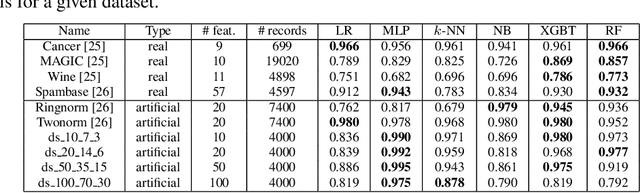
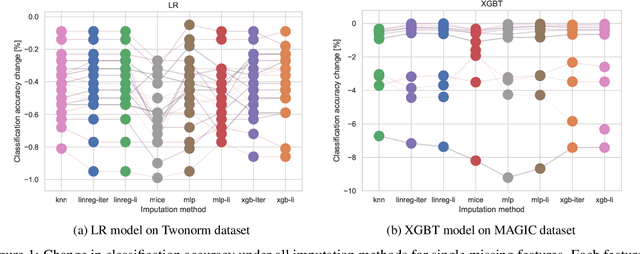
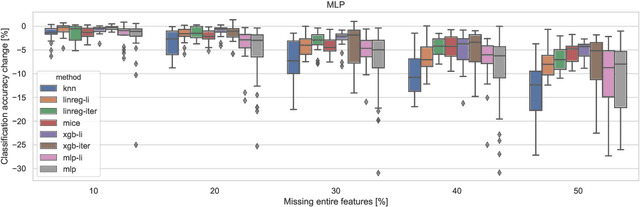
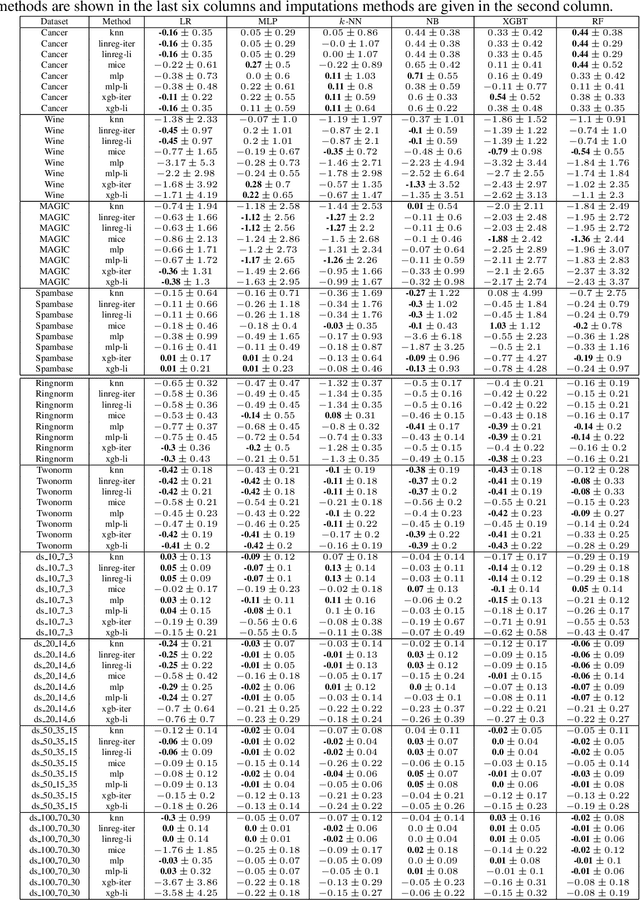
In real-world applications, we can encounter situations when a well-trained model has to be used to predict from a damaged dataset. The damage caused by missing or corrupted values can be either on the level of individual instances or on the level of entire features. Both situations have a negative impact on the usability of the model on such a dataset. This paper focuses on the scenario where entire features are missing which can be understood as a specific case of transfer learning. Our aim is to experimentally research the influence of various imputation methods on the performance of several classification models. The imputation impact is researched on a combination of traditional methods such as k-NN, linear regression, and MICE compared to modern imputation methods such as multi-layer perceptron (MLP) and gradient boosted trees (XGBT). For linear regression, MLP, and XGBT we also propose two approaches to using them for multiple features imputation. The experiments were performed on both real world and artificial datasets with continuous features where different numbers of features, varying from one feature to 50%, were missing. The results show that MICE and linear regression are generally good imputers regardless of the conditions. On the other hand, the performance of MLP and XGBT is strongly dataset dependent. Their performance is the best in some cases, but more often they perform worse than MICE or linear regression.
* Preprint of the conference paper (ICCS 2019), part of the Lecture Notes in Computer Science