 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Features Reconstruction and Its Impact on Classification Accuracy
Paper and Code
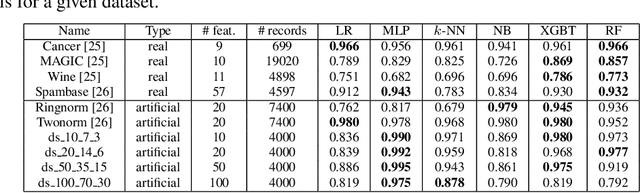
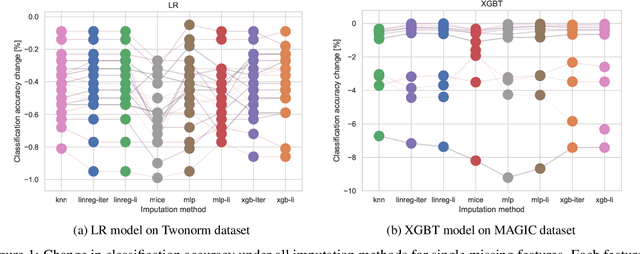
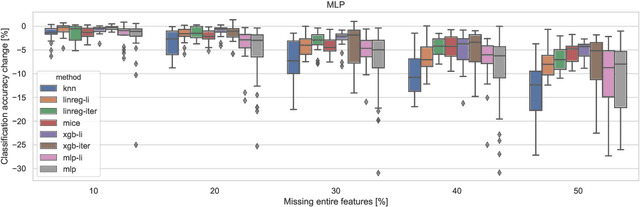
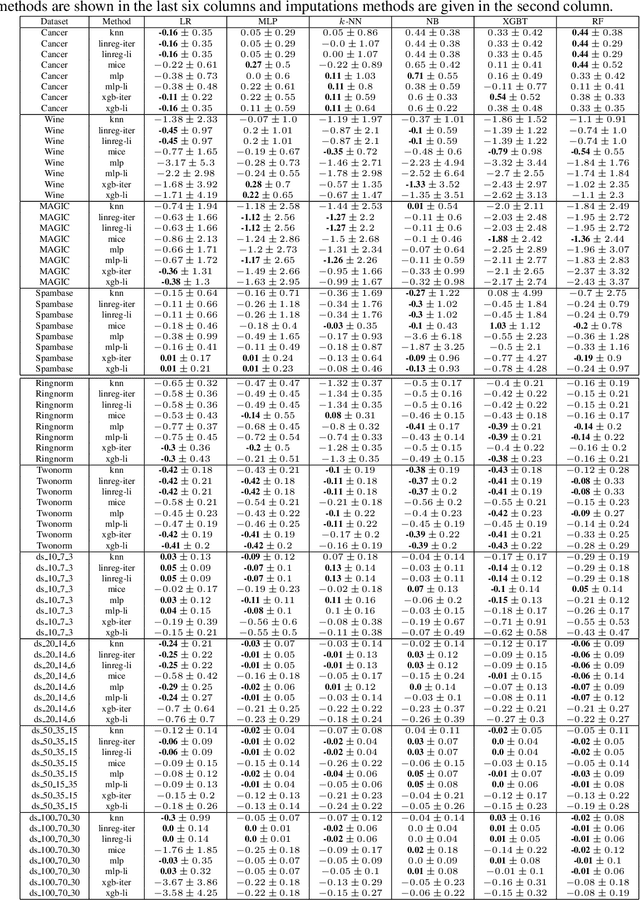
In real-world applications, we can encounter situations when a well-trained model has to be used to predict from a damaged dataset. The damage caused by missing or corrupted values can be either on the level of individual instances or on the level of entire features. Both situations have a negative impact on the usability of the model on such a dataset. This paper focuses on the scenario where entire features are missing which can be understood as a specific case of transfer learning. Our aim is to experimentally research the influence of various imputation methods on the performance of several classification models. The imputation impact is researched on a combination of traditional methods such as k-NN, linear regression, and MICE compared to modern imputation methods such as multi-layer perceptron (MLP) and gradient boosted trees (XGBT). For linear regression, MLP, and XGBT we also propose two approaches to using them for multiple features imputation. The experiments were performed on both real world and artificial datasets with continuous features where different numbers of features, varying from one feature to 50%, were missing. The results show that MICE and linear regression are generally good imputers regardless of the conditions. On the other hand, the performance of MLP and XGBT is strongly dataset dependent. Their performance is the best in some cases, but more often they perform worse than MICE or linear regression.