 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize with Dynamic Mode Decomposition
Paper and Code
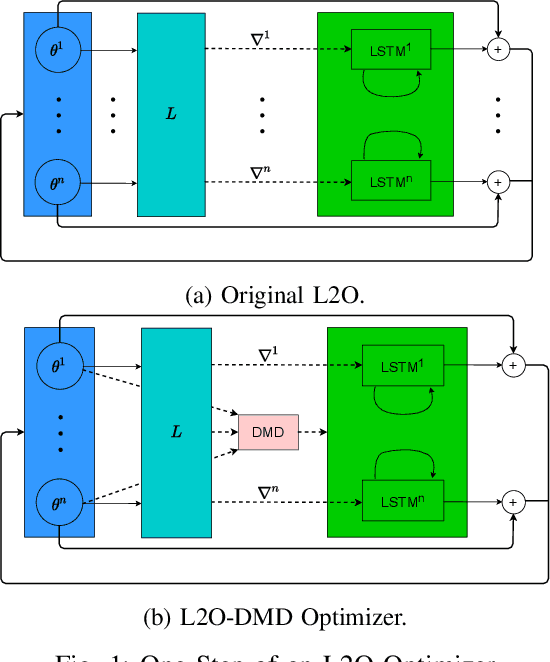
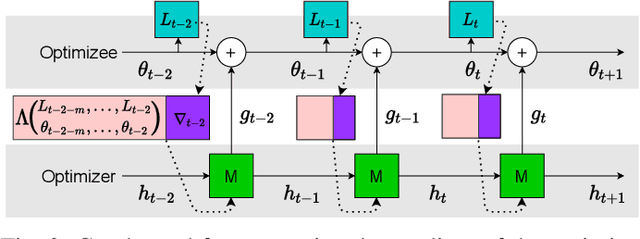
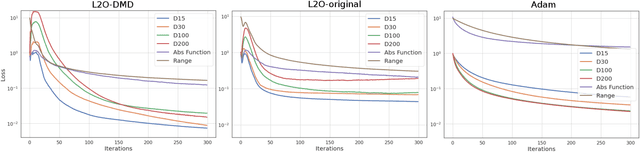
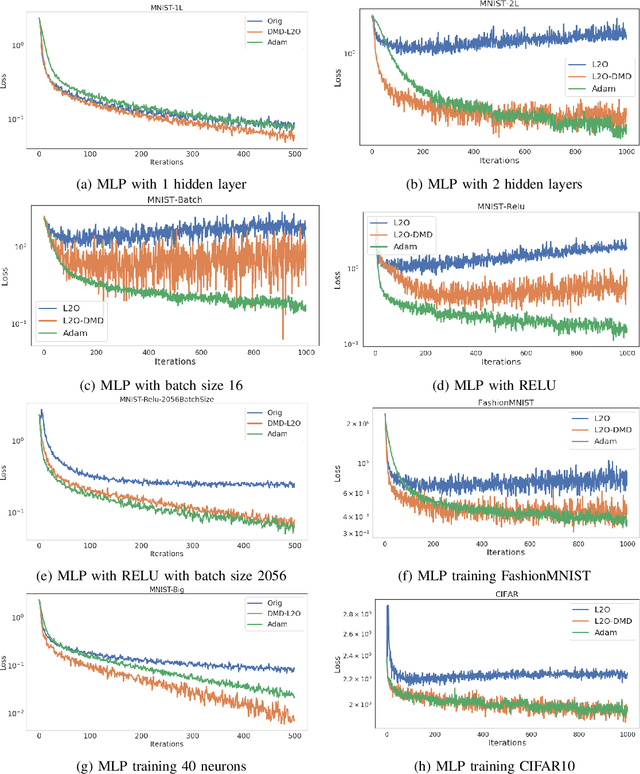
Designing faster optimization algorithms is of ever-growing interest. In recent years, learning to learn methods that learn how to optimize demonstrated very encouraging results. Current approaches usually do not effectively include the dynamics of the optimization process during training. They either omit it entirely or only implicitly assume the dynamics of an isolated parameter. In this paper, we show how to utilize the dynamic mode decomposition method for extracting informative features about optimization dynamics. By employing those features, we show that our learned optimizer generalizes much better to unseen optimization problems in short. The improved generalization is illustrated on multiple tasks where training the optimizer on one neural network generalizes to different architectures and distinct datasets.