 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Weather Predictions: Super-Resolution via Deep Diffusion Models
Jun 06, 2024



This study investigates the application of deep-learning diffusion models for the super-resolution of weather data, a novel approach aimed at enhancing the spatial resolution and detail of meteorological variables. Leveraging the capabilities of diffusion models, specifically the SR3 and ResDiff architectures, we present a methodology for transforming low-resolution weather data into high-resolution outputs. Our experiments, conducted using the WeatherBench dataset, focus on the super-resolution of the two-meter temperature variable, demonstrating the models' ability to generate detailed and accurate weather maps. The results indicate that the ResDiff model, further improved by incorporating physics-based modifications, significantly outperforms traditional SR3 methods in terms of Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Peak Signal-to-Noise Ratio (PSNR). This research highlights the potential of diffusion models in meteorological applications, offering insights into their effectiveness, challenges, and prospects for future advancements in weather prediction and climate analysis.
Investigation into the Training Dynamics of Learned Optimizers
Dec 12, 2023Optimization is an integral part of modern deep learning. Recently, the concept of learned optimizers has emerged as a way to accelerate this optimization process by replacing traditional, hand-crafted algorithms with meta-learned functions. Despite the initial promising results of these methods, issues with stability and generalization still remain, limiting their practical use. Moreover, their inner workings and behavior under different conditions are not yet fully understood, making it difficult to come up with improvements. For this reason, our work examines their optimization trajectories from the perspective of network architecture symmetries and parameter update distributions. Furthermore, by contrasting the learned optimizers with their manually designed counterparts, we identify several key insights that demonstrate how each approach can benefit from the strengths of the other.
Improving deep learning precipitation nowcasting by using prior knowledge
Jan 27, 2023Deep learning methods dominate short-term high-resolution precipitation nowcasting in terms of prediction error. However, their operational usability is limited by difficulties explaining dynamics behind the predictions, which are smoothed out and missing the high-frequency features due to optimizing for mean error loss functions. We experiment with hand-engineering of the advection-diffusion differential equation into a PhyCell to introduce more accurate physical prior to a PhyDNet model that disentangles physical and residual dynamics. Results indicate that while PhyCell can learn the intended dynamics, training of PhyDNet remains driven by loss optimization, resulting in a model with the same prediction capabilities.
WeatherFusionNet: Predicting Precipitation from Satellite Data
Nov 30, 2022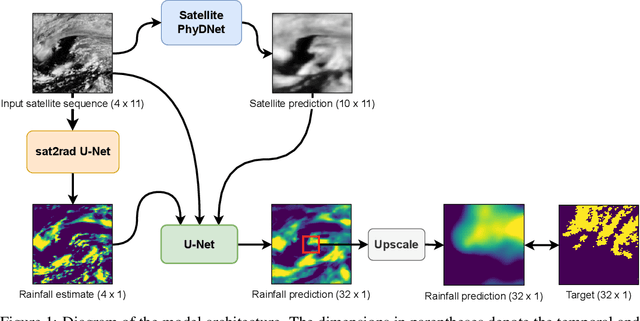
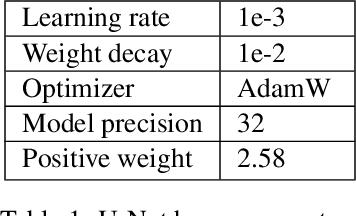
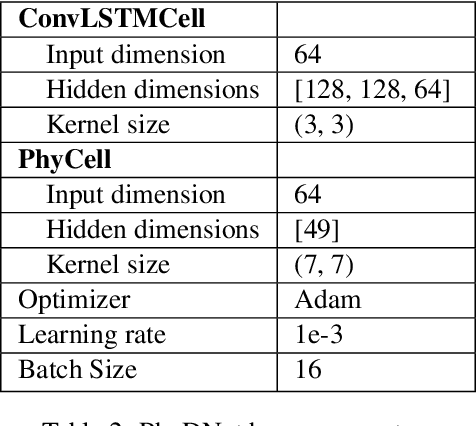
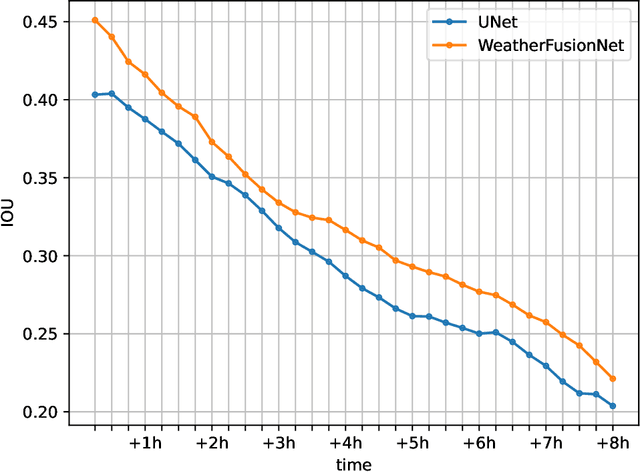
The short-term prediction of precipitation is critical in many areas of life. Recently, a large body of work was devoted to forecasting radar reflectivity images. The radar images are available only in areas with ground weather radars. Thus, we aim to predict high-resolution precipitation from lower-resolution satellite radiance images. A neural network called WeatherFusionNet is employed to predict severe rain up to eight hours in advance. WeatherFusionNet is a U-Net architecture that fuses three different ways to process the satellite data; predicting future satellite frames, extracting rain information from the current frames, and using the input sequence directly. Using the presented method, we achieved 1st place in the NeurIPS 2022 Weather4Cast Core challenge. The code and trained parameters are available at \url{https://github.com/Datalab-FIT-CTU/weather4cast-2022}.
Learning to Optimize with Dynamic Mode Decomposition
Nov 29, 2022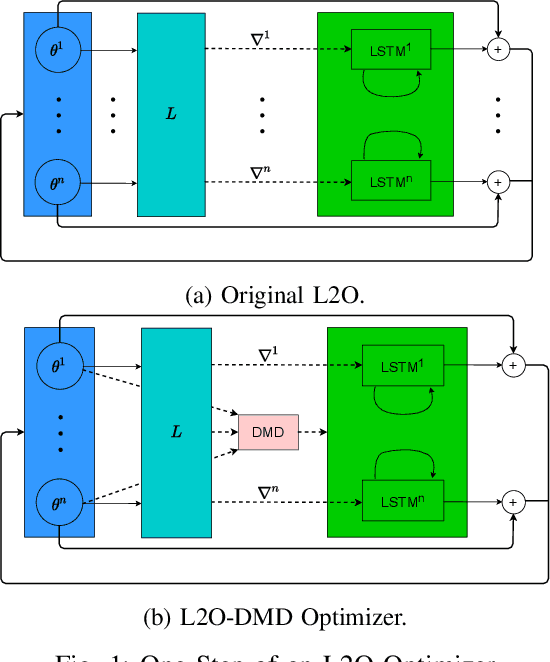
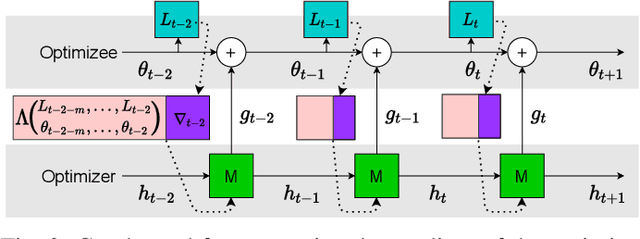
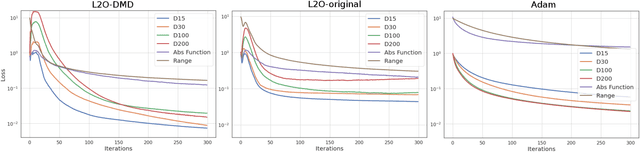
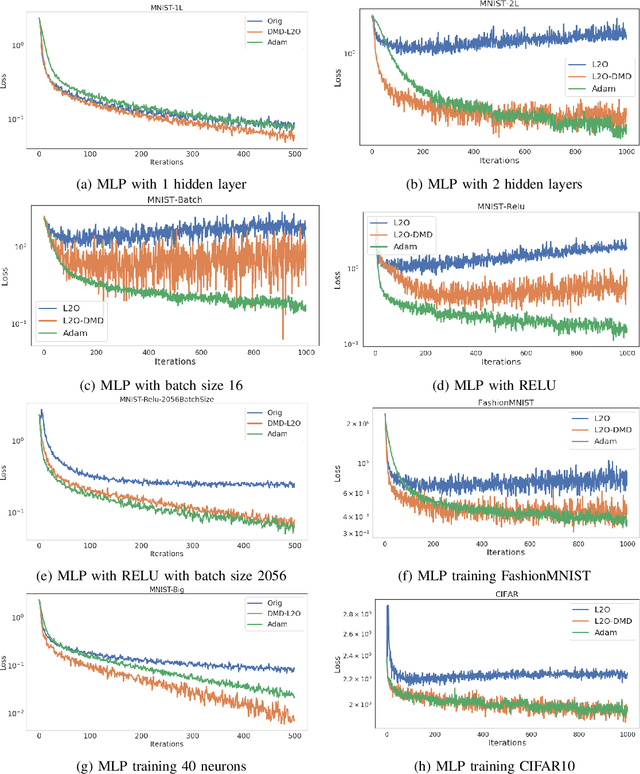
Designing faster optimization algorithms is of ever-growing interest. In recent years, learning to learn methods that learn how to optimize demonstrated very encouraging results. Current approaches usually do not effectively include the dynamics of the optimization process during training. They either omit it entirely or only implicitly assume the dynamics of an isolated parameter. In this paper, we show how to utilize the dynamic mode decomposition method for extracting informative features about optimization dynamics. By employing those features, we show that our learned optimizer generalizes much better to unseen optimization problems in short. The improved generalization is illustrated on multiple tasks where training the optimizer on one neural network generalizes to different architectures and distinct datasets.