 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Artist Catalogs for Cold-Start Music Recommendation
Apr 08, 2026The item cold-start problem poses a fundamental challenge for music recommendation: newly added tracks lack the interaction history that collaborative filtering (CF) requires. Existing approaches often address this problem by learning mappings from content features such as audio, text, and metadata to the CF latent space. However, previous works either omit artist information or treat it as just another input modality, missing the fundamental hierarchy of artists and items. Since most new tracks come from artists with previous history available, we frame cold-start track recommendation as 'semi-cold' by leveraging the rich collaborative signal that exists at the artist level. We show that artist-aware methods can more than double Recall and NDCG compared to content-only baselines, and propose ACARec, an attention-based architecture that generates CF embeddings for new tracks by attending over the artist's existing catalog. We show that our approach has notable advantages in predicting user preferences for new tracks, especially for new artist discovery and more accurate estimation of cold item popularity.
Efficient Learning of Sparse Representations from Interactions
Feb 10, 2026Behavioral patterns captured in embeddings learned from interaction data are pivotal across various stages of production recommender systems. However, in the initial retrieval stage, practitioners face an inherent tradeoff between embedding expressiveness and the scalability and latency of serving components, resulting in the need for representations that are both compact and expressive. To address this challenge, we propose a training strategy for learning high-dimensional sparse embedding layers in place of conventional dense ones, balancing efficiency, representational expressiveness, and interpretability. To demonstrate our approach, we modified the production-grade collaborative filtering autoencoder ELSA, achieving up to 10x reduction in embedding size with no loss of recommendation accuracy, and up to 100x reduction with only a 2.5% loss. Moreover, the active embedding dimensions reveal an interpretable inverted-index structure that segments items in a way directly aligned with the model's latent space, thereby enabling integration of segment-level recommendation functionality (e.g., 2D homepage layouts) within the candidate retrieval model itself. Source codes, additional results, as well as a live demo are available at https://github.com/zombak79/compressed_elsa
From Knots to Knobs: Towards Steerable Collaborative Filtering Using Sparse Autoencoders
Jan 16, 2026Sparse autoencoders (SAEs) have recently emerged as pivotal tools for introspection into large language models. SAEs can uncover high-quality, interpretable features at different levels of granularity and enable targeted steering of the generation process by selectively activating specific neurons in their latent activations. Our paper is the first to apply this approach to collaborative filtering, aiming to extract similarly interpretable features from representations learned purely from interaction signals. In particular, we focus on a widely adopted class of collaborative autoencoders (CFAEs) and augment them by inserting an SAE between their encoder and decoder networks. We demonstrate that such representation is largely monosemantic and propose suitable mapping functions between semantic concepts and individual neurons. We also evaluate a simple yet effective method that utilizes this representation to steer the recommendations in a desired direction.
The Future is Sparse: Embedding Compression for Scalable Retrieval in Recommender Systems
May 16, 2025


Industry-scale recommender systems face a core challenge: representing entities with high cardinality, such as users or items, using dense embeddings that must be accessible during both training and inference. However, as embedding sizes grow, memory constraints make storage and access increasingly difficult. We describe a lightweight, learnable embedding compression technique that projects dense embeddings into a high-dimensional, sparsely activated space. Designed for retrieval tasks, our method reduces memory requirements while preserving retrieval performance, enabling scalable deployment under strict resource constraints. Our results demonstrate that leveraging sparsity is a promising approach for improving the efficiency of large-scale recommenders. We release our code at https://github.com/recombee/CompresSAE.
beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems
Sep 16, 2024



Recommender systems often use text-side information to improve their predictions, especially in cold-start or zero-shot recommendation scenarios, where traditional collaborative filtering approaches cannot be used. Many approaches to text-mining side information for recommender systems have been proposed over recent years, with sentence Transformers being the most prominent one. However, these models are trained to predict semantic similarity without utilizing interaction data with hidden patterns specific to recommender systems. In this paper, we propose beeFormer, a framework for training sentence Transformer models with interaction data. We demonstrate that our models trained with beeFormer can transfer knowledge between datasets while outperforming not only semantic similarity sentence Transformers but also traditional collaborative filtering methods. We also show that training on multiple datasets from different domains accumulates knowledge in a single model, unlocking the possibility of training universal, domain-agnostic sentence Transformer models to mine text representations for recommender systems. We release the source code, trained models, and additional details allowing replication of our experiments at https://github.com/recombee/beeformer.
Deep Variational Autoencoder with Shallow Parallel Path for Top-N Recommendation (VASP)
Feb 10, 2021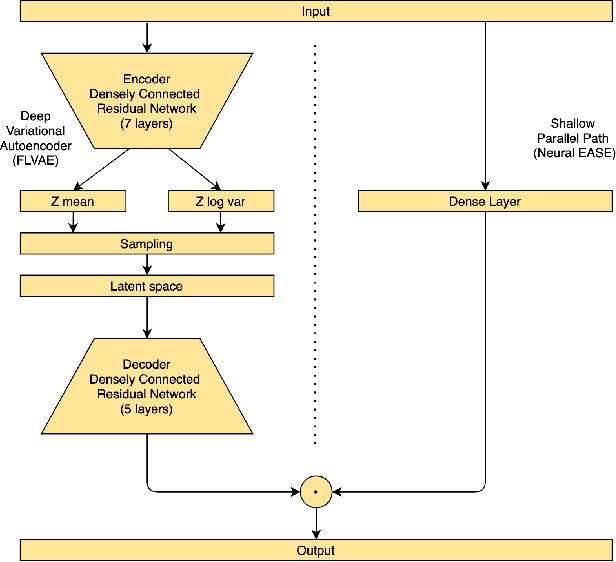

Recently introduced EASE algorithm presents a simple and elegant way, how to solve the top-N recommendation task. In this paper, we introduce Neural EASE to further improve the performance of this algorithm by incorporating techniques for training modern neural networks. Also, there is a growing interest in the recsys community to utilize variational autoencoders (VAE) for this task. We introduce deep autoencoder FLVAE benefiting from multiple non-linear layers without an information bottleneck while not overfitting towards the identity. We show how to learn FLVAE in parallel with Neural EASE and achieve the state of the art performance on the MovieLens 20M dataset and competitive results on the Netflix Prize dataset.