Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Inclusion-Optimal Chordal Graphs
Paper and Code
Jun 13, 2012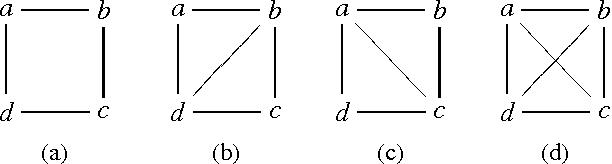
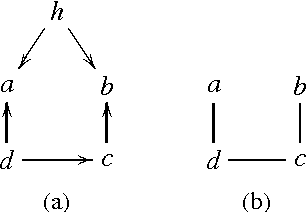
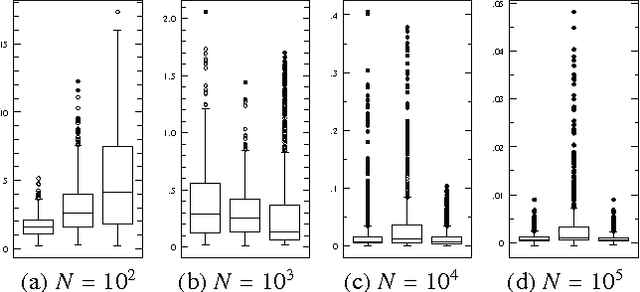
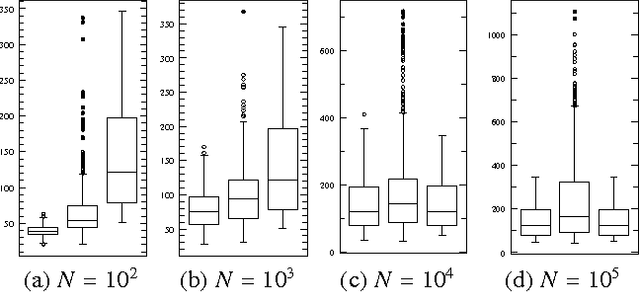
Chordal graphs can be used to encode dependency models that are representable by both directed acyclic and undirected graphs. This paper discusses a very simple and efficient algorithm to learn the chordal structure of a probabilistic model from data. The algorithm is a greedy hill-climbing search algorithm that uses the inclusion boundary neighborhood over chordal graphs. In the limit of a large sample size and under appropriate hypotheses on the scoring criterion, we prove that the algorithm will find a structure that is inclusion-optimal when the dependency model of the data-generating distribution can be represented exactly by an undirected graph. The algorithm is evaluated on simulated datasets.
* Appears in Proceedings of the Twenty-Fourth Conference on Uncertainty
in Artificial Intelligence (UAI2008)
View paper on