 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Subspace with Trees for Feature Selection Under Memory Constraints
Paper and Code
Sep 06, 2017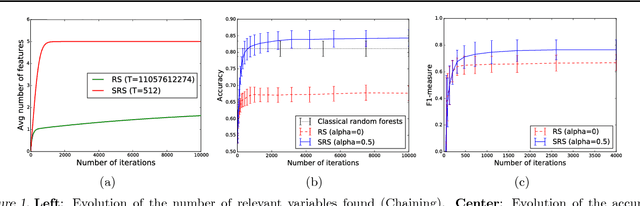
Dealing with datasets of very high dimension is a major challenge in machine learning. In this paper, we consider the problem of feature selection in applications where the memory is not large enough to contain all features. In this setting, we propose a novel tree-based feature selection approach that builds a sequence of randomized trees on small subsamples of variables mixing both variables already identified as relevant by previous models and variables randomly selected among the other variables. As our main contribution, we provide an in-depth theoretical analysis of this method in infinite sample setting. In particular, we study its soundness with respect to common definitions of feature relevance and its convergence speed under various variable dependance scenarios. We also provide some preliminary empirical results highlighting the potential of the approach.