 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing an Intelligent Digital Twin with a Self-organized Reconfiguration Management based on Adaptive Process Models
Jul 07, 2021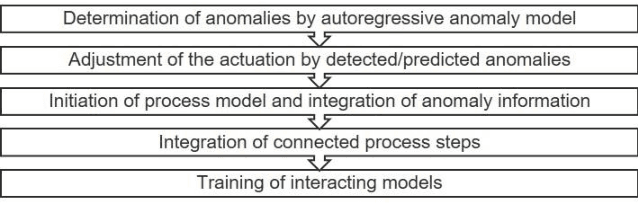
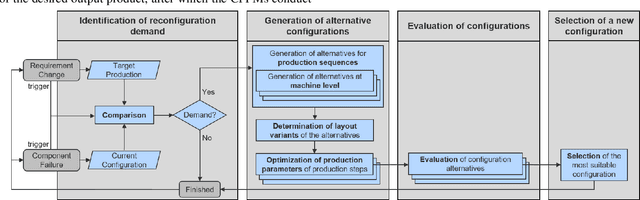
Shorter product life cycles and increasing individualization of production leads to an increased reconfiguration demand in the domain of industrial automation systems, which will be dominated by cyber-physical production systems in the future. In constantly changing systems, however, not all configuration alternatives of the almost infinite state space are fully understood. Thus, certain configurations can lead to process instability, a reduction in quality or machine failures. Therefore, this paper presents an approach that enhances an intelligent Digital Twin with a self-organized reconfiguration management based on adaptive process models in order to find optimized configurations more comprehensively.
Optimized Look-Ahead Tree Policies: A Bridge Between Look-Ahead Tree Policies and Direct Policy Search
Aug 23, 2012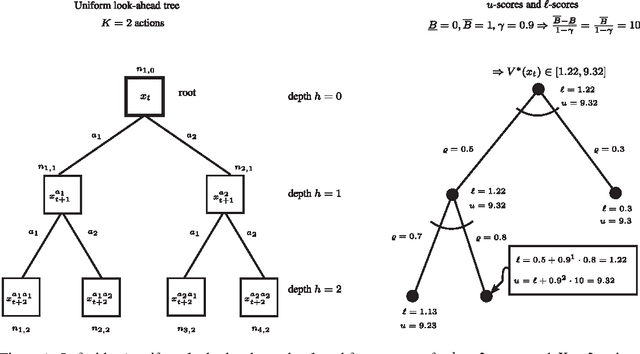
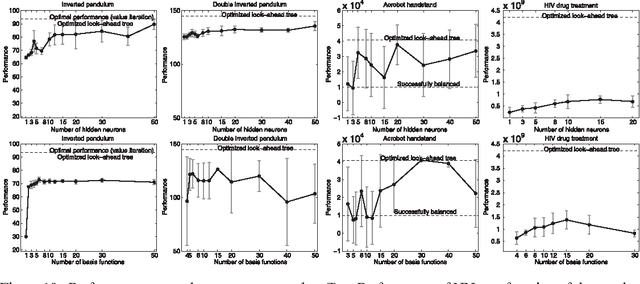
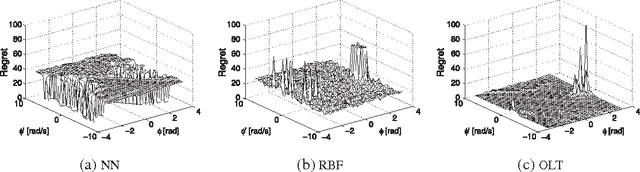
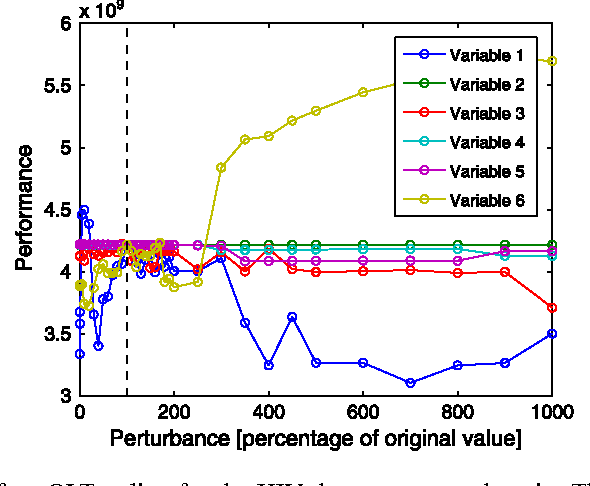
Direct policy search (DPS) and look-ahead tree (LT) policies are two widely used classes of techniques to produce high performance policies for sequential decision-making problems. To make DPS approaches work well, one crucial issue is to select an appropriate space of parameterized policies with respect to the targeted problem. A fundamental issue in LT approaches is that, to take good decisions, such policies must develop very large look-ahead trees which may require excessive online computational resources. In this paper, we propose a new hybrid policy learning scheme that lies at the intersection of DPS and LT, in which the policy is an algorithm that develops a small look-ahead tree in a directed way, guided by a node scoring function that is learned through DPS. The LT-based representation is shown to be a versatile way of representing policies in a DPS scheme, while at the same time, DPS enables to significantly reduce the size of the look-ahead trees that are required to take high-quality decisions. We experimentally compare our method with two other state-of-the-art DPS techniques and four common LT policies on four benchmark domains and show that it combines the advantages of the two techniques from which it originates. In particular, we show that our method: (1) produces overall better performing policies than both pure DPS and pure LT policies, (2) requires a substantially smaller number of policy evaluations than other DPS techniques, (3) is easy to tune and (4) results in policies that are quite robust with respect to perturbations of the initial conditions.
Learning RoboCup-Keepaway with Kernels
Jan 31, 2012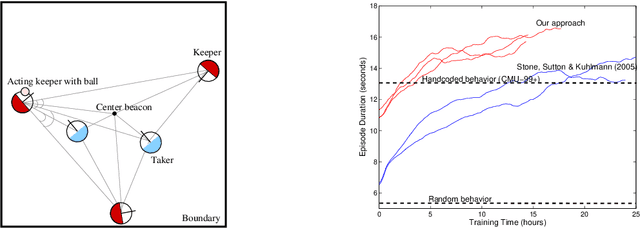
We apply kernel-based methods to solve the difficult reinforcement learning problem of 3vs2 keepaway in RoboCup simulated soccer. Key challenges in keepaway are the high-dimensionality of the state space (rendering conventional discretization-based function approximation like tilecoding infeasible), the stochasticity due to noise and multiple learning agents needing to cooperate (meaning that the exact dynamics of the environment are unknown) and real-time learning (meaning that an efficient online implementation is required). We employ the general framework of approximate policy iteration with least-squares-based policy evaluation. As underlying function approximator we consider the family of regularization networks with subset of regressors approximation. The core of our proposed solution is an efficient recursive implementation with automatic supervised selection of relevant basis functions. Simulation results indicate that the behavior learned through our approach clearly outperforms the best results obtained earlier with tilecoding by Stone et al. (2005).
Feature Selection for Value Function Approximation Using Bayesian Model Selection
Jan 31, 2012


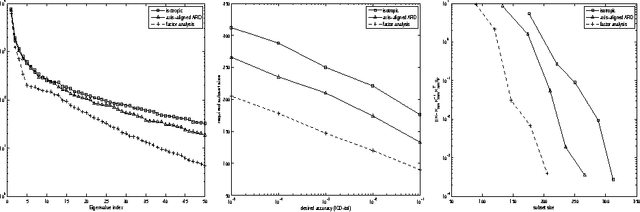
Feature selection in reinforcement learning (RL), i.e. choosing basis functions such that useful approximations of the unkown value function can be obtained, is one of the main challenges in scaling RL to real-world applications. Here we consider the Gaussian process based framework GPTD for approximate policy evaluation, and propose feature selection through marginal likelihood optimization of the associated hyperparameters. Our approach has two appealing benefits: (1) given just sample transitions, we can solve the policy evaluation problem fully automatically (without looking at the learning task, and, in theory, independent of the dimensionality of the state space), and (2) model selection allows us to consider more sophisticated kernels, which in turn enable us to identify relevant subspaces and eliminate irrelevant state variables such that we can achieve substantial computational savings and improved prediction performance.
Gaussian Processes for Sample Efficient Reinforcement Learning with RMAX-like Exploration
Jan 31, 2012
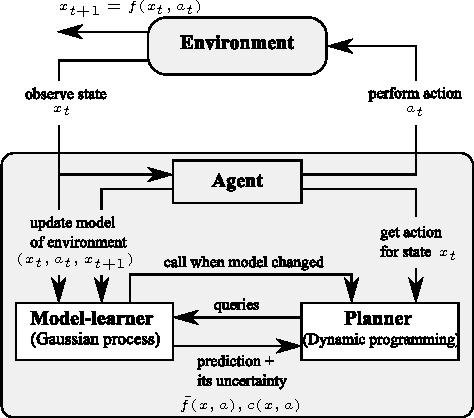

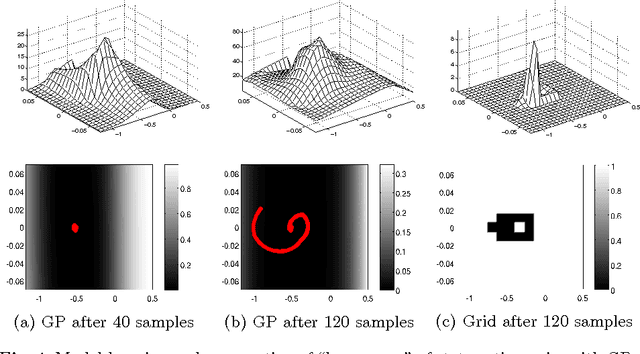
We present an implementation of model-based online reinforcement learning (RL) for continuous domains with deterministic transitions that is specifically designed to achieve low sample complexity. To achieve low sample complexity, since the environment is unknown, an agent must intelligently balance exploration and exploitation, and must be able to rapidly generalize from observations. While in the past a number of related sample efficient RL algorithms have been proposed, to allow theoretical analysis, mainly model-learners with weak generalization capabilities were considered. Here, we separate function approximation in the model learner (which does require samples) from the interpolation in the planner (which does not require samples). For model-learning we apply Gaussian processes regression (GP) which is able to automatically adjust itself to the complexity of the problem (via Bayesian hyperparameter selection) and, in practice, often able to learn a highly accurate model from very little data. In addition, a GP provides a natural way to determine the uncertainty of its predictions, which allows us to implement the "optimism in the face of uncertainty" principle used to efficiently control exploration. Our method is evaluated on four common benchmark domains.
Empowerment for Continuous Agent-Environment Systems
Jan 31, 2012



This paper develops generalizations of empowerment to continuous states. Empowerment is a recently introduced information-theoretic quantity motivated by hypotheses about the efficiency of the sensorimotor loop in biological organisms, but also from considerations stemming from curiosity-driven learning. Empowemerment measures, for agent-environment systems with stochastic transitions, how much influence an agent has on its environment, but only that influence that can be sensed by the agent sensors. It is an information-theoretic generalization of joint controllability (influence on environment) and observability (measurement by sensors) of the environment by the agent, both controllability and observability being usually defined in control theory as the dimensionality of the control/observation spaces. Earlier work has shown that empowerment has various interesting and relevant properties, e.g., it allows us to identify salient states using only the dynamics, and it can act as intrinsic reward without requiring an external reward. However, in this previous work empowerment was limited to the case of small-scale and discrete domains and furthermore state transition probabilities were assumed to be known. The goal of this paper is to extend empowerment to the significantly more important and relevant case of continuous vector-valued state spaces and initially unknown state transition probabilities. The continuous state space is addressed by Monte-Carlo approximation; the unknown transitions are addressed by model learning and prediction for which we apply Gaussian processes regression with iterated forecasting. In a number of well-known continuous control tasks we examine the dynamics induced by empowerment and include an application to exploration and online model learning.